- @ddrfan
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
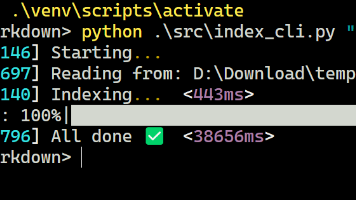
官方llama.cpp现已支持MTP模型,无需单独draft模型。使用最新二进制程序和Qwen3.6-35B-A3B-UD-IQ2_M.gguf模型,通过添加--spec-type draft-mtp和--spec-draft-n-max 2参数可显著提升推理速度。测试显示,关闭推理模式后,RAG性能接近在线LLM,生成速度大幅提升(draft接受率达88.6%)。建议显存充足的用户尝试MTP优化

本文实测了Gemma-4-26B模型在多token预测(MTP)技术下的性能表现。通过ik_llama.cpp分支测试发现,当显存不足24GB时,MTP加速效果受限:在4060Ti显卡(16GB显存)上运行会触发共享显存机制,导致生成速度反而降至3分44秒,远慢于原版llama.cpp的1分34秒。测试数据显示,MTP技术虽在理想条件下可实现2倍加速(如作者测试的49t/s),但实际应用中显存容量

这篇文章重点讲解了如何通过LlamaIndex实现向量数据库的抽象统一和数据处理流程。作者强调了调试模式的重要性,建议在正式入库前先人工检查node质量,包括metadata完整性、文本长度合理性等。文章详细说明了初始化向量数据库、构建文档node、统计分析metadata以及观察最大最小node等关键步骤,并指出这些预处理工作能有效避免后续检索质量问题。整个工具设计注重灵活性和可维护性,支持多种
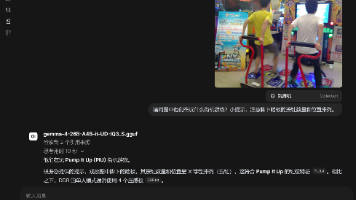
本地大模型部署评测报告 本文对比测试了Qwen和Gemma系列模型在本地环境(i9-12900F/RTX4060Ti/64GB)下的表现。通过llama.cpp框架评测了7款量化模型,重点考察了RAG能力和视觉识别表现。
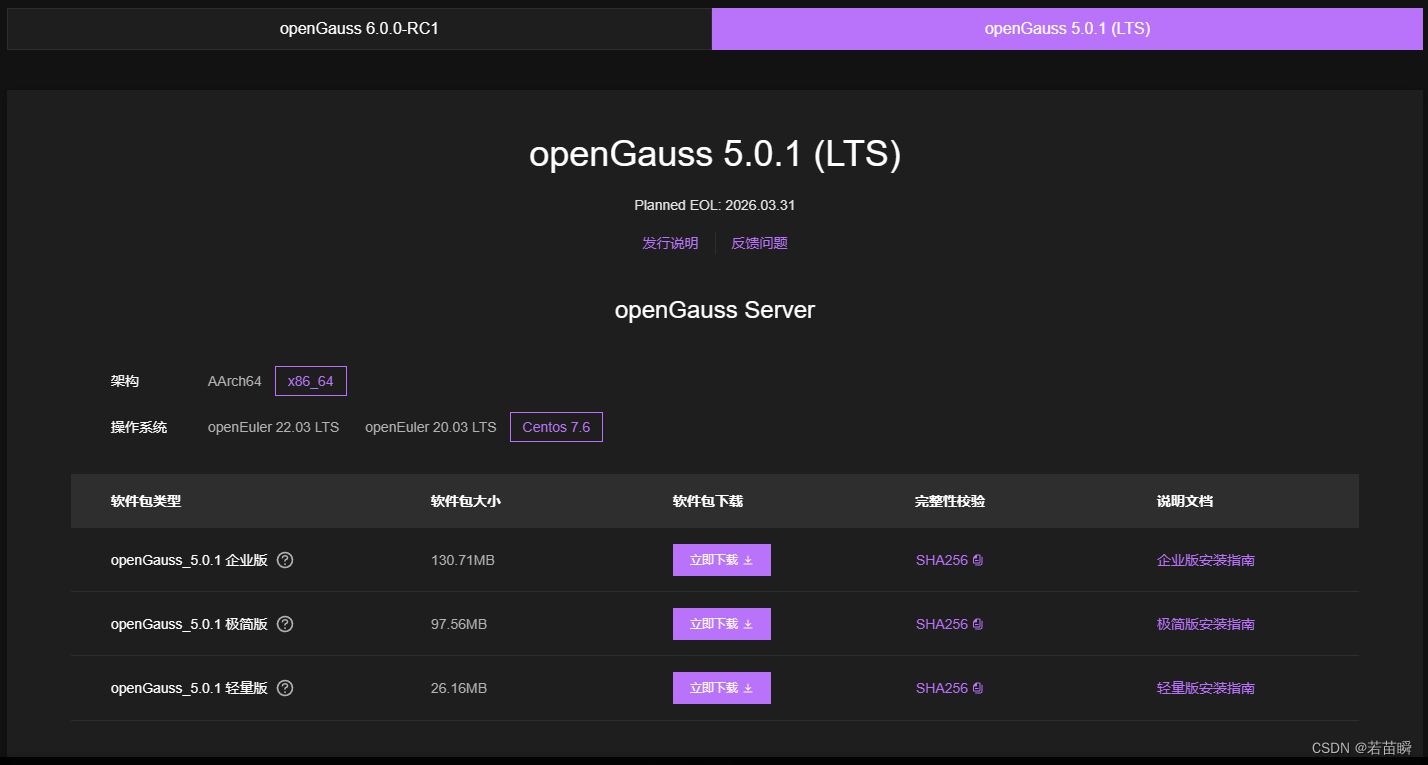
我们的国产化们:panweiDB,openGauss,Postgres。GoldenDB,mySQL……
我们训练自己的模型时,需要找到最像原型,且适应性依然强的那个阶段输出。
由于世界风云变幻,无论是国家、客户、还是我们自己。都希望自研软件系统的数据库能够自主可控,最好还是开源的……哎……
清华镜像:https://mirrors.tuna.tsinghua.edu.cn/Adoptium/8/jdk/x64/windows/
更高更快更强,天下武功,唯快不破……

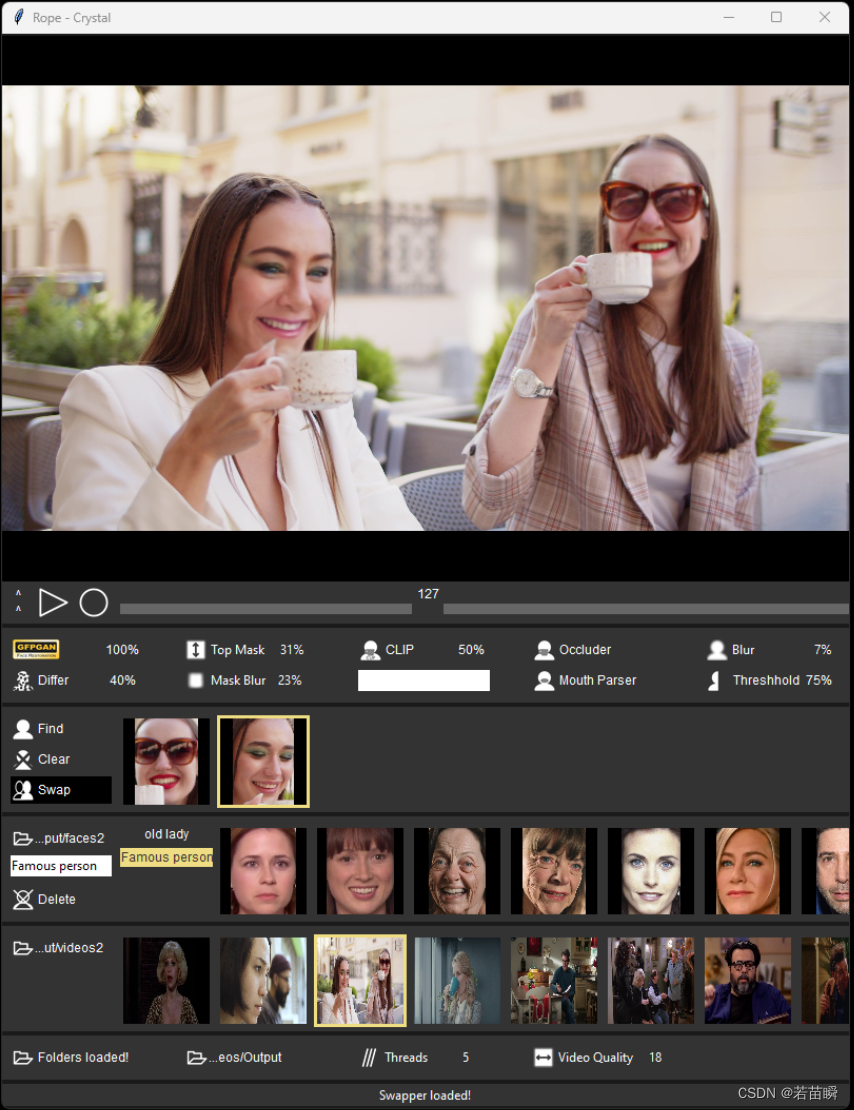
跟不上了啊啊啊,roop停止更新,出现了很多类似roop的项目。