




- @cr7258
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
CloudCanal 介绍CloudCanal 是一款数据迁移同步工具,提供友好的可视化操作界面,支持多种数据源间的数据迁移、数据同步、结构迁移、数据校验。CloudCanal 核心团队成员来自阿里巴巴中间件和数据库团队, 长期从事分布式数据库、数据库中间件、应用中间件工作。CloudCanal 在 MySQL binlog 解析使用了 Canal 部分代码,其他均为自主研发,并且对 Canal
vLLM 是一个高效、易用的大语言模型(LLM)推理和服务框架,专注于优化推理速度和吞吐量,尤其适合高并发的生产环境。它由加州大学伯克利分校的研究团队开发,并因其出色的性能成为当前最受欢迎的 LLM 推理引擎之一。vLLM 同时支持在 GPU 和 CPU 上运行,本文将会分别介绍 vLLM 使用 GPU 和 CPU 作为后端时的安装与运行方法。本文系统介绍了高性能 LLM 推理框架 vLLM 的部

Crossplane是一个开源的 Kubernetes 扩展,其核心目标是将 Kubernetes 转化为一个通用的控制平面,使其能够管理和编排分布于 Kubernetes 集群内外的各种资源。通过扩展 Kubernetes 的功能,Crossplane 对 Kubernetes 集群外部的资源进行了抽象,允许用户使用 Kubernetes 的 API 来统一管理云服务(例如 AWS EC2, S

本文介绍了如何使用 SeekDB 和 PowerMem 构建一个多模态智能记忆系统 MemBox。通过 SeekDB 的向量检索能力和 PowerMem 的智能记忆提取,MemBox 能够自动从对话中提取关键信息、构建用户画像,并在后续对话中提供个性化回复。前端基于 Vercel AI SDK 实现了流式对话和多模态图片理解,后端通过 FastAPI 提供记忆存储和检索服务。整个系统还支持多用户隔
本文详细介绍如何结合 Dify、OceanBase 和 MCP 从零开始构建一个功能完备的 RAG 应用。教程涵盖了从部署环境、创建知识库、到构建聊天助手并进行调试的全过程。最后,文章还演示了如何将 Dify 应用转化为一个标准的 MCP Server,使其能被外部客户端调用,从而极大地扩展了 AI 应用的集成与协作能力。
本教程通过构建一个 Elasticsearch MCP Server 的实例,展示了如何利用 MCP 协议的三个核心原语(Tool、Resource 和 Prompt)来增强 LLM 的能力。通过 Tool 实现了索引操作和文档写入,通过 Resource 提供数据的访问能力,而 Prompt 则帮助 LLM 以标准化的方式完成任务。最后通过一个实际的组合示例,演示了如何让 LLM 利用这些组件完
本文重点介绍了 Higress AI 网关的模型降级和令牌降级功能。在 LLM 服务不可用时,模型降级功能能自动切换到备用 LLM,确保业务连续性。而令牌降级功能则通过健康检查机制,自动移除不可用的 ApiToken,并在恢复后重新加入,从而提升服务的稳定性和用户体验。

本文通过实际案例演示了如何利用 Context7 MCP Server 解决 AI 编程助手中的代码幻觉问题和使用过时 API 的问题。借助 Context7 获取最新、最准确的代码建议,显著提升了 AI 生成的代码质量,从而有效提高了开发效率。
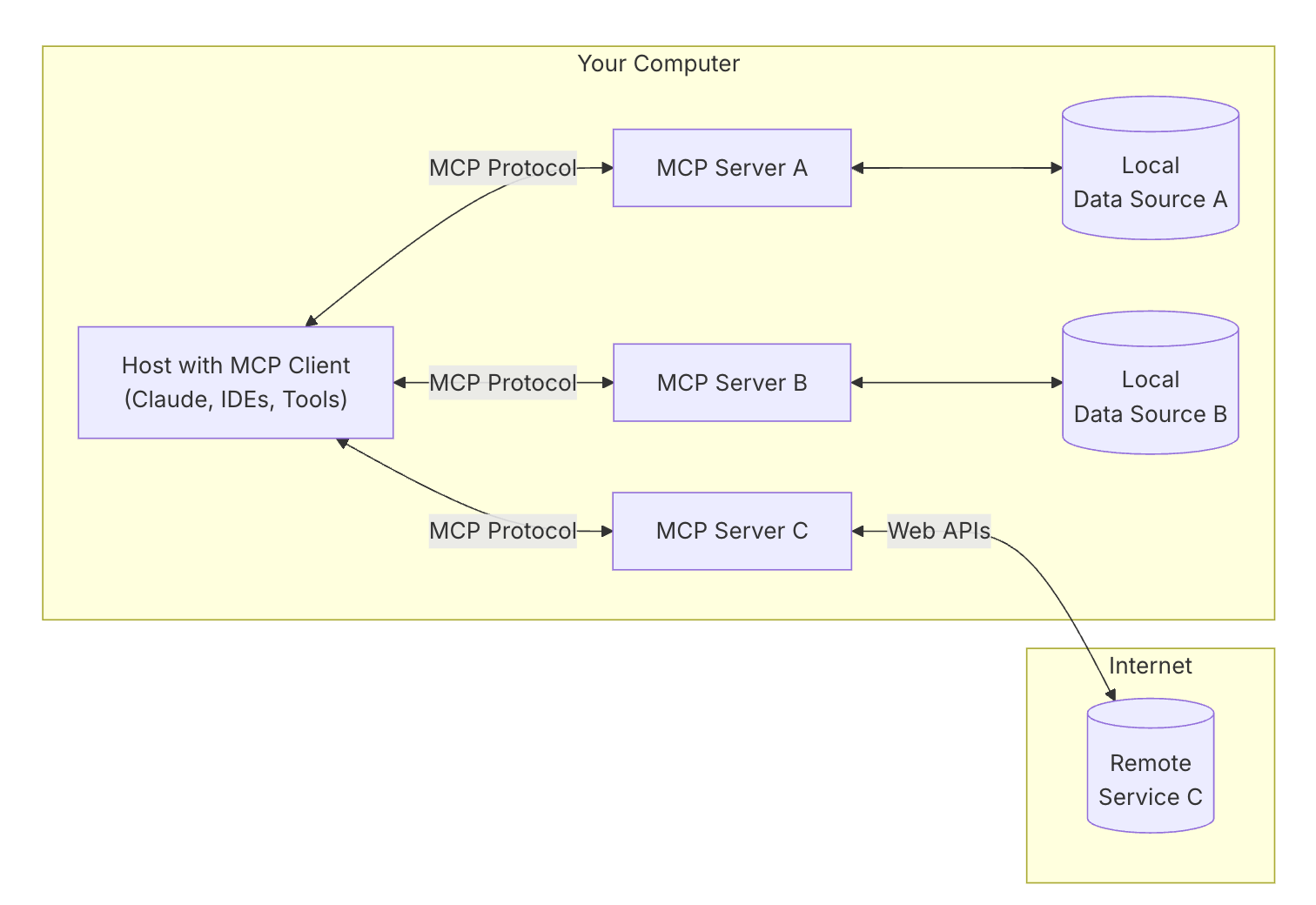
MCP(Model Context Protocol,模型上下文协议) 是由 Anthropic 推出的一种开放标准,旨在统一大型语言模型(LLM)与外部数据源和工具之间的通信协议。MCP 的主要目的在于解决当前 AI 模型因数据孤岛限制而无法充分发挥潜力的难题,MCP 使得 AI 应用能够安全地访问和操作本地及远程数据,为 AI 应用提供了连接万物的接口。本文带领读者快速入门了 MCP(模型上下
1 什么是图(Graph)本文介绍的图和日常生活中常见的图片有所不同。通常,在英文中,为了区分这两种不同的图,前者会称为 Image,后者称为 Graph。在中文中,前者会强调为“图片”,后者会强调为“拓扑图”、“网络图”等。一张图(Graph)由一些小圆点(称为顶点或节点,即 Vertex)和连接这些圆点的直线或曲线(称为边,即 Edge)组成。“图(Graph)“这一名词最早由西尔维斯特在 1