




- @coolinfo
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
skills/│ ├── SKILL.md # 技能描述文档│ ├── config.yaml # 配置参数│ ├── tools/ # 工具实现│ └── scripts/ # 配套脚本└── tools/SKILL.md文档结构示例## Tools```python### 3.2 工具创建与注册技能通过标准的 Tool 接口实现 :```python"""执行网页搜索"""# 实现搜索逻辑#
Beam search通过在每个时间步保留最可能的 num_beams 个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险。1、基于N-gram或者其他的都是概率模型, N-gram模型对训练数据的需求较少,但对数据的覆盖性要求高。缺点: 错过了隐藏在低概率词后面的高概率词,如:dog=0.5, has=0.9。选出概率最大的 K 个词,重新归一化,最后在归一化后的 K 个词中采

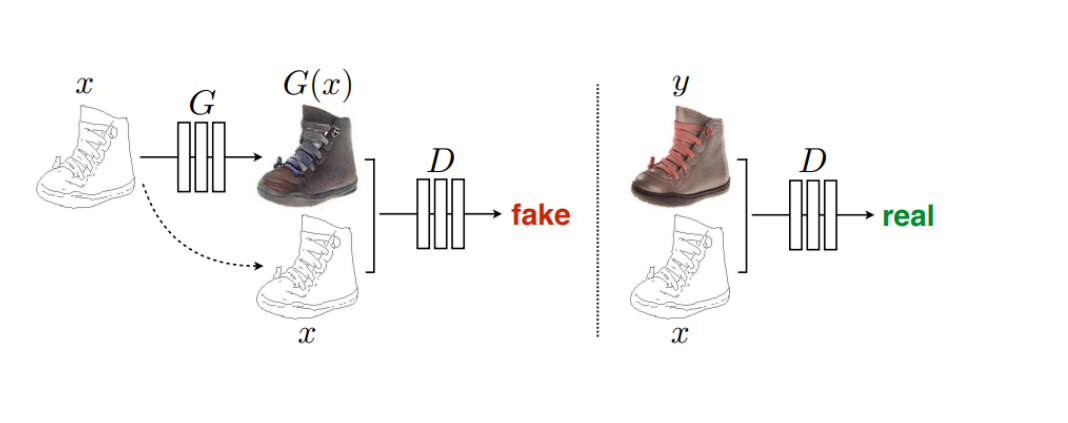
Pix2Pix是基于条件生成对抗网络(cGAN, Condition Generative Adversarial Networks )实现的一种深度学习图像转换模型,该模型是由Phillip Isola等作者在2017年CVPR上提出的,可以实现语义/标签到真实图片、灰度图到彩色图、航空图到地图、白天到黑夜、线稿图到实物图的转换。Pix2Pix是将cGAN应用于有监督的图像到图像翻译的经典之作,
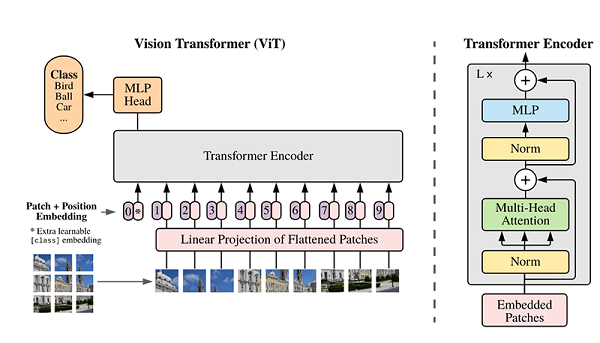
近些年,随着基于自注意(Self-Attention)结构的模型的发展,特别是Transformer模型的提出,极大地促进了自然语言处理模型的发展。由于Transformers的计算效率和可扩展性,它已经能够训练具有超过100B参数的空前规模的模型。ViT则是自然语言处理和计算机视觉两个领域的融合结晶。在不依赖卷积操作的情况下,依然可以在图像分类任务上达到很好的效果。本案例完成了一个ViT模型在I
本案例将使用MNIST手写数字数据集来训练一个生成式对抗网络,使用该网络模拟生成手写数字图片。、要注意的是刚开始的D不能太聪明,要能给出G网络一个方向(也就是不能说有G网络生成的图像都给0分,这样G网络就没有目标方向了,因为其向得分高的一侧适配);而后G得到一定分数后,G网络进化,这时需要D网络也进化,找出聪明一点儿的G网络不好的部分,如此D\G两个网络互相竞争,形成最后结果3、实践发现,当提升e
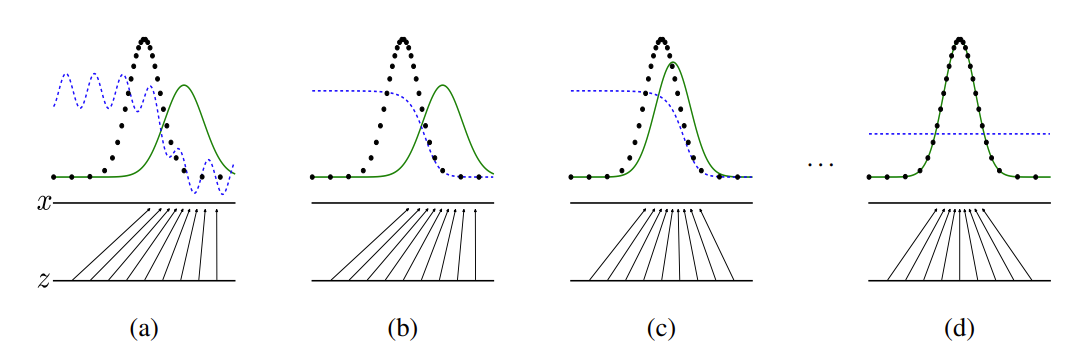
如果将Diffusion与其他生成模型(如Normalizing Flows、GAN或VAE)进行比较,它并没有那么复杂,它们都将噪声从一些简单分布转换为数据样本,Diffusion也是从纯噪声开始通过一个神经网络学习逐步去噪,最终得到一个实际图像。Diffusion对于图像的处理包括以下两个过程:我们选择的固定(或预定义)正向扩散过程qqq:它逐渐将高斯噪声添加到图像中,直到最终得到纯噪声一个学

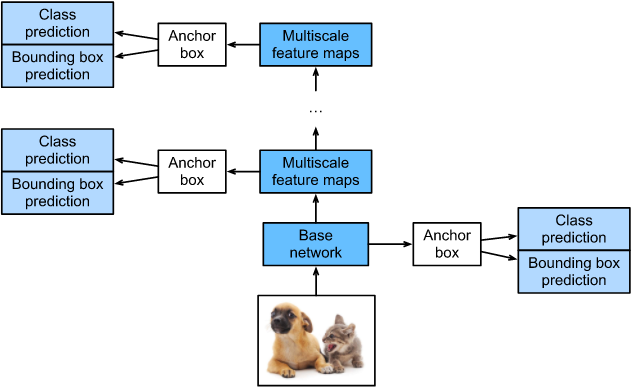
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法。使用Nvidia Titan X在VOC 2007测试集上,SSD对于输入尺寸300x300的网络,达到74.3%mAP(mean Average Precision)以及59FPS;对于512x512的网络,达到了76.9%mAP ,超越当时最强的Faster R
给出了MIndspore框架在ResNet50训练上的应用
MusicGen是来自Meta AI的Jade Copet等人提出的基于单个语言模型(LM)的音乐生成模型,能够根据文本描述或音频提示生成高质量的音乐样本,相关研究成果参考论文《MusicGen直接使用谷歌的及其权重作为文本编码器模型,并使用及其权重作为音频压缩模型。MusicGen解码器是一个语言模型架构,针对音乐生成任务从零开始进行训练。MusicGen 模型的新颖之处在于音频代码的预测方式。

MobileNet网络是由Google团队于2017年提出的专注于移动端、嵌入式或IoT设备的轻量级CNN网络,相比于传统的卷积神经网络,MobileNet网络使用深度可分离卷积(Depthwise Separable Convolution)的思想在准确率小幅度降低的前提下,大大减小了模型参数与运算量。并引入宽度系数 α和分辨率系数 β使模型满足不同应用场景的需求。
