- @colus_SEU
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
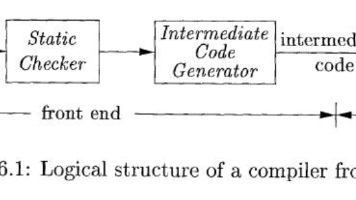
摘要:中间代码在编译过程中扮演关键角色,作为连接编译器前端和后端的桥梁。它具有促进可移植性和优化两大核心作用,使编译器能支持多源语言和目标平台。三地址码是最主要的中间表示形式,包含九种基本指令类型,采用四元组、三元组等数据结构存储。文章详细阐述了表达式、数组、类型检查和控制流语句的翻译方法,比较了跳转编码和回填编码两种策略。通过具体示例展示了布尔表达式和循环语句的中间代码生成过程,揭示了回填机制如
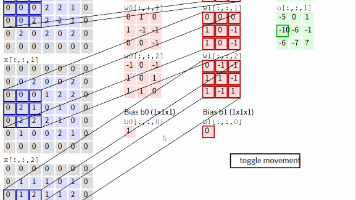
本文介绍了CNN中的卷积运算原理及特点。首先阐述了单通道和多通道输入时的卷积计算方法,说明了feature map的生成过程,并解释了步长对输出尺寸的影响。其次详细分析了三种卷积模式(Full、Same、Valid)的区别及其输出尺寸的计算公式,指出卷积核通常为奇数的原因。最后总结了卷积运算的三个重要特点:局部感受野、参数共享和参数数量减少,这些特性使CNN相比全连接网络具有显著优势。通过具体示例
线性回归模型形式简单,可解释性强,有着大量的理论支撑,但是在实际问题中,很多关系往往不能用线性模型简单地概括。因此需要引入非线性回归模型。对于一些典型的非线性回归模型,通过变量代换,我们可以将其转化为线性回归模型来解决。通常多项式回归模型函数的形式为:为了方便表达,我们可以将上式写为矩阵形式:即:是预测值向量,包含所有样本的预测结果。 是设计矩阵,每一行对应一个样本的特征值及其高次幂。 是参数向量
本文系统介绍了三种正则化线性回归方法:岭回归、套索回归和弹性网络。岭回归通过L2正则化解决多重共线性问题,套索回归通过L1正则化实现特征选择,而弹性网络结合两者优势,同时具备组相似性和稀疏性。文章详细推导了各类方法的数学原理,比较了其几何差异和特性,并通过Python代码实现验证了不同正则化参数对模型性能的影响。实验结果表明,正则化方法能有效控制模型复杂度,其中弹性网络在处理高维相关数据时表现最佳
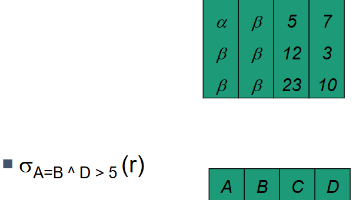
关系模式是关系的型(Type)关系名:表的唯一标识(如STUDENT属性集:表的列及其数据类型(如学号 CHAR(7)完整性约束:主键、外键、域约束等。形式化表示U属性集合(如D:属性对应的域(如SNO的域是7位数字)。DOM:属性到域的映射(如F:属性间的函数依赖(如PK:主键(如SNO键类型定义示例(STUDENT表)特点超键能唯一标识行的属性组合(含冗余){SNO}{ID}不要求最小性候选键
本文系统介绍了计算机网络的基本概念与技术。首先阐述了因特网的定义,包括其物理构成、服务模式和协议体系。随后详细解析了网络边缘的端系统、接入网技术和物理媒介,以及网络核心的分组交换与电路交换原理。文章还深入探讨了网络性能指标如时延、吞吐量、丢包率等,并分析了信号传输过程中的失真问题与信道容量限制。最后,通过对比OSI七层模型与TCP/IP四层模型,揭示了计算机网络的分层架构思想。全文从多维度构建了对
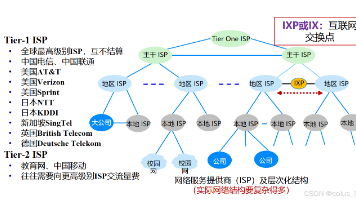
关系模式是关系的型(Type)关系名:表的唯一标识(如STUDENT属性集:表的列及其数据类型(如学号 CHAR(7)完整性约束:主键、外键、域约束等。形式化表示U属性集合(如D:属性对应的域(如SNO的域是7位数字)。DOM:属性到域的映射(如F:属性间的函数依赖(如PK:主键(如SNO键类型定义示例(STUDENT表)特点超键能唯一标识行的属性组合(含冗余){SNO}{ID}不要求最小性候选键
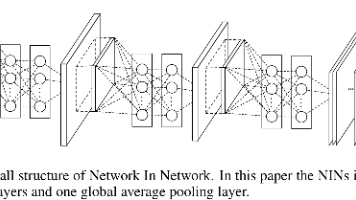
摘要:NiN(Network in Network)是2014年提出的一种创新卷积神经网络结构,旨在解决传统CNN的局限性。其核心创新包括:1)MLP卷积层,通过1x1卷积增强局部特征提取能力;2)全局平均池化替代全连接层,大幅减少参数量。相比AlexNet等传统网络,NiN在保持高表达能力的同时显著提升了参数效率。PyTorch实现显示,该结构在CIFAR-10等任务上表现优异,证明了其设计的前
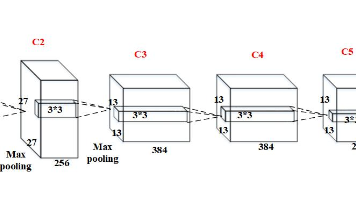
AlexNet是2012年提出的里程碑式卷积神经网络,在ImageNet竞赛中以15.3%的错误率远超传统方法。其创新包括:使用ReLU激活函数缓解梯度消失;采用Dropout和数据增强防止过拟合;首次利用GPU加速训练。该网络包含5个卷积层和3个全连接层,通过重叠池化提升特征不变性。实验表明,在Fashion-MNIST和CIFAR-10数据集上,带动量优化的SGD表现最佳,测试准确率分别达91
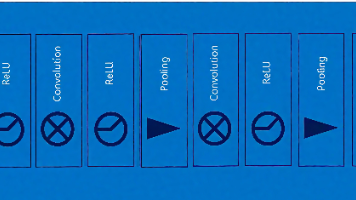
卷积神经网络(CNN)是一种专为处理网格结构数据(如图像)设计的深度学习模型,其核心优势在于局部连接、权值共享和池化操作。相比全连接网络,CNN通过局部感受野提取层次化特征,显著减少参数数量并保持空间信息。关键组件包括卷积层(特征提取)、ReLU激活函数(引入非线性)、池化层(信息压缩)和全连接层(分类)。CNN的发展始于1998年LeNet-5的提出,2012年AlexNet在ImageNet竞