




- @chenyuhao2024
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文分三大模块:认识大语言模型、提示词编写、嵌入模型。大语言模型依托神经网络与海量参数,以预测下一词为核心,通过自监督、半监督学习习得语言规律,具备规模大、通用性强、可自然交互等特点。提示词工程包含CO-STAR框架、少样本提示、思维链、零样本推理、自我批判迭代五种方法,可组合使用优化AI输出。嵌入模型为表示型模型,把文本等信息转为语义向量,落地于语义搜索、RAG、推荐系统、异常检测,并介绍了多款
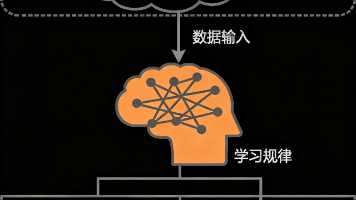
本文分三大模块:认识大语言模型、提示词编写、嵌入模型。大语言模型依托神经网络与海量参数,以预测下一词为核心,通过自监督、半监督学习习得语言规律,具备规模大、通用性强、可自然交互等特点。提示词工程包含CO-STAR框架、少样本提示、思维链、零样本推理、自我批判迭代五种方法,可组合使用优化AI输出。嵌入模型为表示型模型,把文本等信息转为语义向量,落地于语义搜索、RAG、推荐系统、异常检测,并介绍了多款
本文介绍了二叉搜索树(BST)的基本概念及其C++实现。BST是一种高效的数据结构,具有O(logn)的平均查找、插入和删除效率。文章详细讲解了BST的节点结构设计,以及插入、查找、删除和中序遍历等核心操作的实现方法,包括递归和非递归版本。特别针对删除操作,分析了三种不同情况的处理逻辑。此外,还介绍了BST的两种应用模型:K模型(纯键值)和KV模型(键值对),并提供了字典查询和统计功能的完整代码示

承接上文,讲完了结构体我们就得来讲讲位段。位段(Bit Field)已经涉及是C/C++语言中的一种数据结构,它允许你在结构体或联合体中定义特定宽度的字段。位段的主要用途是节省内存空间,特别是在嵌入式系统或对内存使用有严格限制的应用中。什么是位段位段的声明和结构是类似的,有两个不同:1.位段的成员必须是 int、unsigned int 或signed int。2.位段的成员名后边有一个冒号和一个

本文详细探讨了Linux进程管理的核心机制,包括fork函数原理、进程终止、进程等待和程序替换。fork通过写时拷贝技术高效创建子进程,父子进程共享代码但独立执行。进程终止需关注退出码和僵尸状态处理,wait/waitpid函数用于父进程回收子进程资源。程序替换函数族(execl/execv等)允许子进程运行全新程序,通过重建页表映射实现进程分离。文章通过代码示例演示了非阻塞等待、状态码检查等技术

本文摘要: C++11新特性lambda表达式和智能指针详解。lambda表达式通过匿名函数简化代码,支持捕获外部变量,底层实现为仿函数类。智能指针包括unique_ptr(禁止拷贝)、shared_ptr(引用计数)和weak_ptr(解决循环引用),基于RAII思想自动管理资源。shared_ptr存在线程安全和循环引用问题,可通过加锁和weak_ptr解决。文章还介绍了定制删除器处理特殊内存

为解决这个问题,我们在 map 和 set 这两个容器层,分别实现了仿函数 MapKeyOfT 和 SetKeyOfT,并将它们传递给红黑树的 KeyOfT 模板参数。,无法直接判断模板参数 T 具体是单纯的键类型 K(如:set 的场景 ),还是键值对类型 pair<K, V>(如:map 的场景 )这样一颗红黑树,既能适配 set 的 “纯 key 搜索场景”,也能适配 map 的 “key/

还是用原本视频的例子最为贴近来解释关于广播的矩阵算法。这是一个不同食物(每 100g)中不同营养成分的卡路里含量表格,表格为 3 行 4 列,列表示不同的食物种类,从左至右依次为苹果,牛肉,鸡蛋,土豆。行表示不同的营养成分,从上到下依次为碳水化合物,蛋白质,脂肪。那么,我们现在想要计算不同食物中不同营养成分中的卡路里百分比。 现在计算苹果中的碳水化合物卡路里百分比含量,首先计算苹果(100g)中三

可以知道的一个使用 sigmoid 函数和机器学习问题是,在这个区域,也就是这个 sigmoid 函数的梯度会接近零,所以学习的速度会变得非常缓慢,因为当你实现梯度下降以及梯度接近零的时候,参数会更新的很慢,所以学习的速率也会变的很慢,而通过改变这个被叫做激活函数的东西,神经网络换用这一个函数,叫做 ReLU 的函数(修正线性单元),ReLU 它的梯度对于所有输入的负值都是零,因此梯度更加不会趋向

来了来了,这道题才是值得我们奇思妙想的题,链接在下面。看完题目一脸懵吗,没关系,我们还得看示例还是一脸懵怎么办??两个链表相交的方式有几种?我们再来仔细看一下这道题这里我们就看到了,可能出现三种形式的相交,那我们就要在想一下,这三种情况下,我们应该怎么去判断这两个链表是相交的。为什么是找地址而不是比值呢?好了,那我们来试试看,能不能用双指针法来解决,但是你会很直观发现不可行,因为链表长度是不相同的
