- @YG15165
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
以下修改的配置文件均在目录下一、Hadoop入门 1 、常用端口号hadoop3.xHDFS NameNode 内部通常端口:8020/9000/9820HDFS NameNode 对用户的查询端口:9870Yarn查看任务运行情况的:8088历史服务器:19888hadoop2.xHDFS NameNode 内部通常端口:8020/9000HDFS NameNode 对用户的查询端口:50070
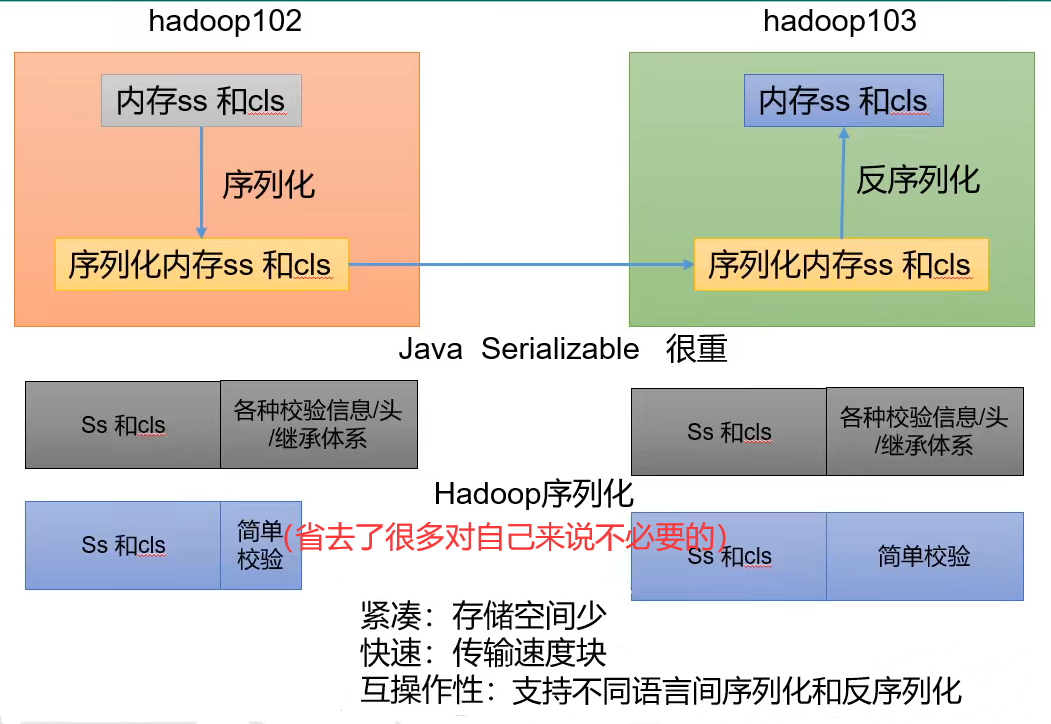
Kafka传统定义:是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。发布/订阅模式:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息Kafka最新定义:是一个开源的分布式事件流平台 (Event StreamingPlatform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任

数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的:工作流定时调度器如果把数据看作图书馆里的书,我们希望看到它们在书架上分门别类地放置;如果把数据看作城市的建筑,我们希望城市规划布局合理;
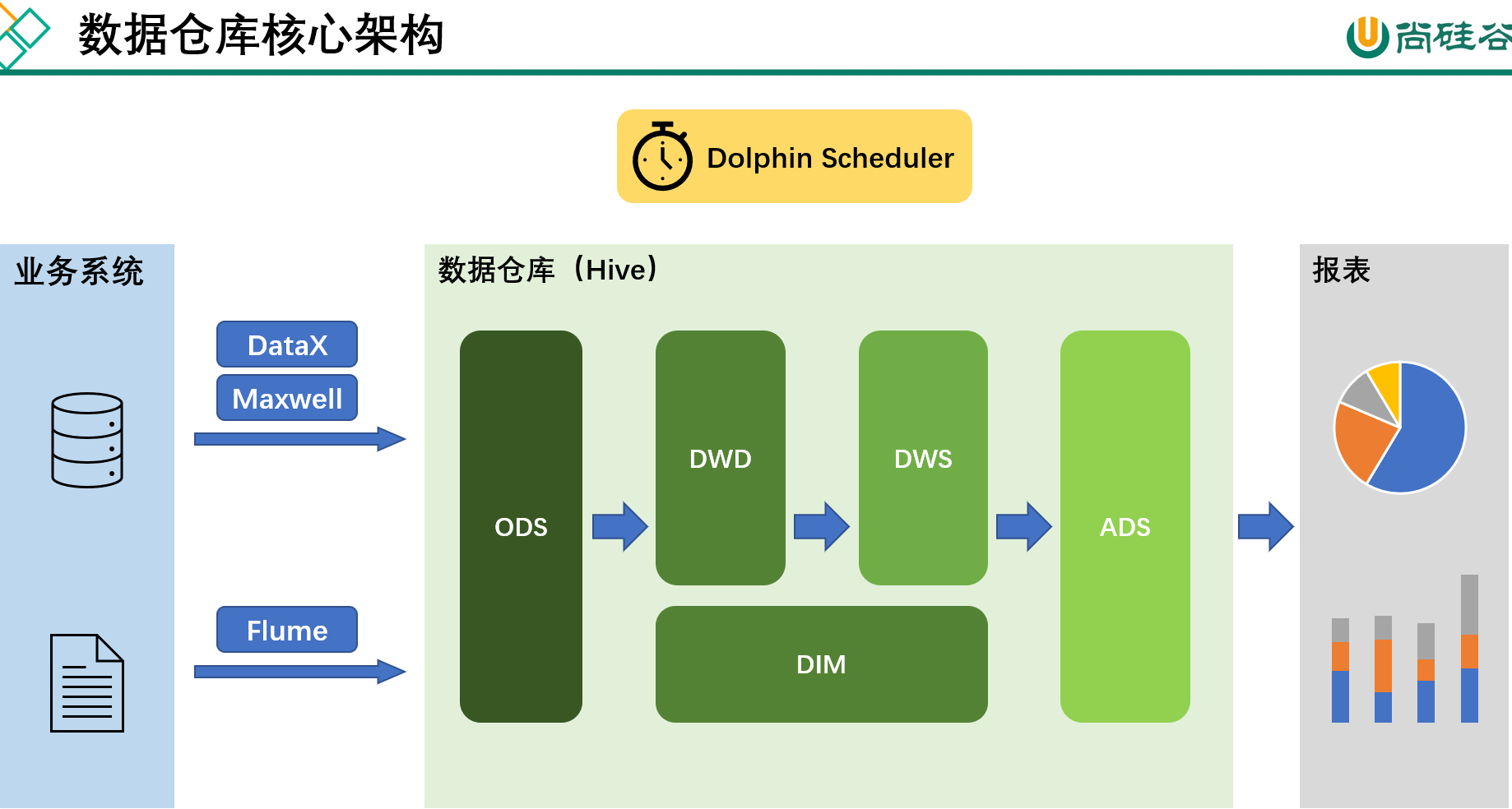
🔨数据仓库是为企业制定决策,提供数据支持的。可以帮助企业改进业务流程、提高产品质量等。🔨数据仓库的输入数据通常包括:业务数据(响应要快)、用户行为数据和爬虫数据等业务数据:就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在 MySQL、Oracle 等数据库中用户行为数据:用户在使

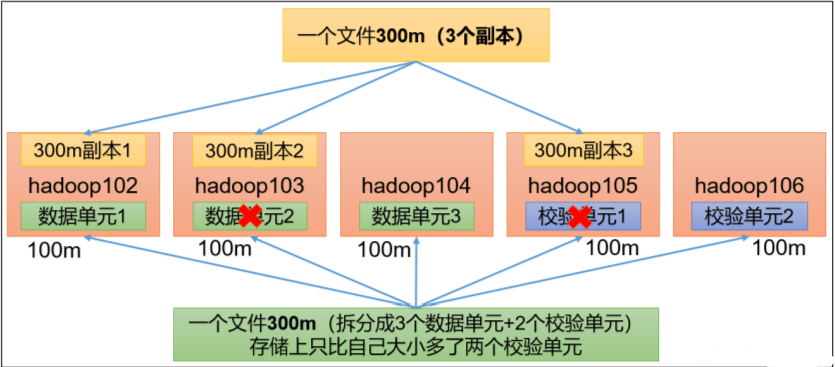
大数据解决的无非是海量数据的采集、存储、计算,Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。flume能保证数据的可靠性,但不能保证数据的重复性Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS✍出bug多看看flume目录下的flume`.log文件查看错误信息,问问al轻松解决!?

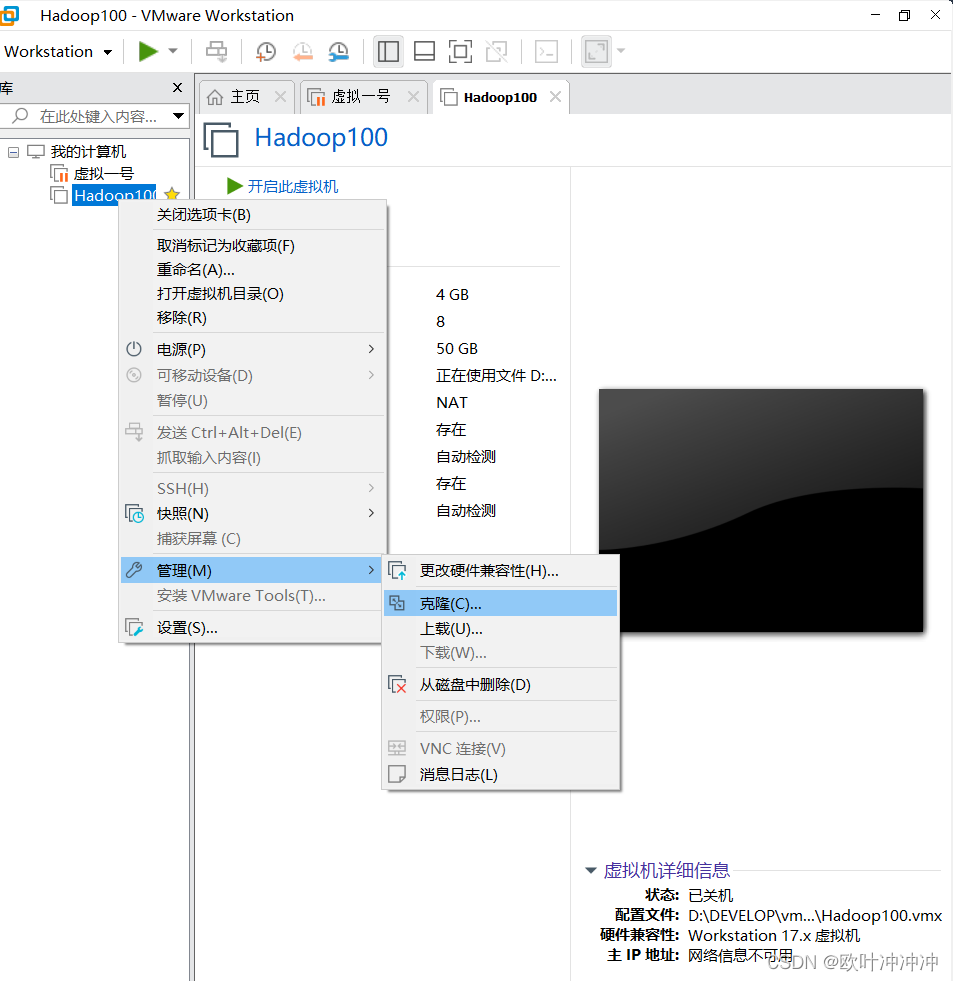
首先准备好工具。下载好最新的VMware Workstation,CentorOS 7运行Linux,建议Linux桌面标准版,且创建好一个用户模板机一定要按照步骤做好准备,避免遗漏,否则一台一台改超级麻烦。搭建hadoop运行环境!!
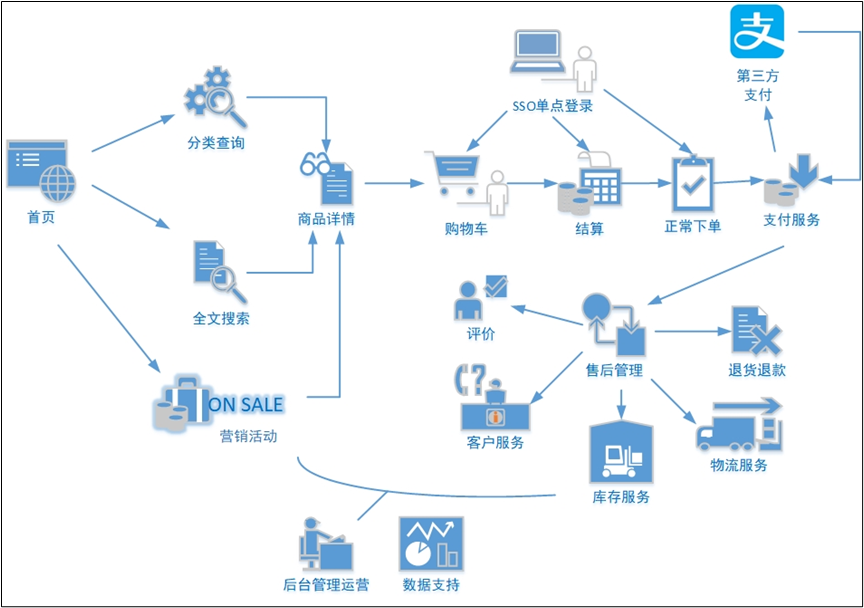
紧接上一篇👉点击前往数仓准备工作🔨电商的业务流程可以以一个普通用户的浏览足迹为例进行说明,用户点开电商首页开始浏览,可能会通过分类查询也可能通过全文搜索寻找自己中意的商品,这些商品都是存储在后台的管理系统中的当用户寻找到自己中意的商品,可能会想要购买,将商品添加到购物车后发现需要登录,登录后对商品进行结算,这时候购物车的管理和商品订单信息的生成都会对业务数据库产生影响,会生成相应的订单数据和支
Hadoop 运行模式包括:本地模式、伪分布式模式以及完全分布式模式了解更多详情👉hadoop官方网站过知识点时只有多敲多练测试案例才能找到学习过程中的bug,yarn相关操作要在hadoop103上进行…完全分布模式的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。在所有的主机上安装JDK和Hadoop,组成相互连通的网络。hadoop运行在多台机器上面,称之为hadoop集群。✍下一
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能👉点击前往查看源码✍简单了解了DataX的使用方法,全量表数据由DataX从MySQL业务数据库直接同步到HDFS。
MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一是分布式计算框,就是mapreduce,二者缺一不可,也就是说,可以通过mapreduce很容易在hadoop平台上进行分布式的计算编程sftp命令:Windows下登录Hadoop102lcd切换Windows路径,cd切换Linux路径,get下载,put上传🧮MapReduce是一