




- @Willen_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
遇到的问题,就是 GPU driver 以及cuda都装完了,pytorch装完之后想试试代码。结果报错,raise AssertionError(“Torch not compiled with CUDA enabled”)。
ImportError: libSM.so.6: cannot open shared object file: No such file or directory转自:https://www.cnblogs.com/haiyang21/p/11210038.html错误Traceback (most recent call last):File "<stdin>", line 1,
遇到的问题,就是 GPU driver 以及cuda都装完了,pytorch装完之后想试试代码。结果报错,raise AssertionError(“Torch not compiled with CUDA enabled”)。
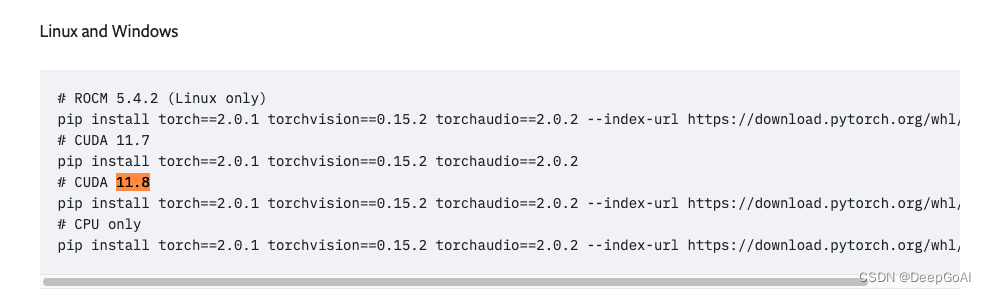
这样的问题往往都是版本不匹配导致的pytorch的版本,mmcv的版本和cuda 的版本 (nvcc -V) 要一致。首先上pytorch官网看看。cuda和pytorch的版本:可以通过这里查找对应匹配的版本下载mmcv按照官网给的配置去设置各个版本,基本上就没问题。
tensorflow安装和版本选择版本选择看这里https://blog.csdn.net/qiancaobaicheng/article/details/95226499安装看这里安装anaconda,然后用python的pip可以安装特定版本的tensorflow,如:pip install tensorflow-gpu==1.4.0-i https://pypi....
实现在服务器重启后自动启动docker服务以及容器(类似于守护进程服务)。重启启动docker服务systemctl enable docker.service重启启动docker容器启动时候使用 --restart=always参数。docker run -dit \--restart=always \#配置为自动重启--name nginx \--network host \nginx已经启动
Docker Error loading config file XXX.dockerconfig.json permission denied和 Docker Got permissiondenied 的 解决1.如果是 ==》Error loading config file XXX.dockerconfig.json - stat /home/XXX/.docker/config.json:
pycharm + docker 远程调试容器内程序一、首先假设你已启动了一个docker容器,并在启动时将容器的22端口映射到宿主机的10022端口启动示例:nvidia-docker run -it -p 5000:80 -p 10022:22 -v ~/longlongaaago/workspace/docker:/root/workspace --name "longlonga...
强化学习On-policy vs Off-policy这里我们讲讲强化学习中on-policy和off-policy的区别。实际上这个区别非常简单,就是说如果算法在更新它的policy的时候,它是依赖于前面的Q value function的话,那么它就是on-policy的。反之如果它是依赖于随机的一个输入或者人为的操控,那么它就是一个off policy的。具体来说就是由于在算法更新我们val
强化学习On-policy vs Off-policy这里我们讲讲强化学习中on-policy和off-policy的区别。实际上这个区别非常简单,就是说如果算法在更新它的policy的时候,它是依赖于前面的Q value function的话,那么它就是on-policy的。反之如果它是依赖于随机的一个输入或者人为的操控,那么它就是一个off policy的。具体来说就是由于在算法更新我们val