




- @Wayn111
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
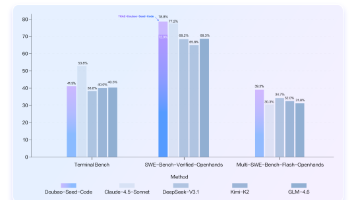
本文介绍了Doubao-Seed-Code模型相比Qwen3-coder等模型的优势:1)具备出色的视觉理解能力,能准确还原图像中的组件结构;2)在多项编程测评中表现优异,排名仅次于Sonnet4.5;3)原生兼容Anthropic API,可无缝替代ClaudeCode;4)提供详细的使用教程,包括安装配置和API调用说明;5)性价比极高,输入输出单价低于行业60%,支持9.9元起的套餐计划,大
欢迎大家参与使用项目,使用中遇到问题欢迎大家提出。我都会一一查看并回复。再附源码地址:https://github.com/wayn111/newbee-mall-pro在线地址:http://121.4.124.33/newbeemall。
欢迎大家使用,这个项目我开源的的,使用中遇到问题可以提交 issue。提交的问题我都会一一查看并回复。

欢迎大家使用,使用中遇到问题可以提交 issue 或者加博主私人微信waynaqua给你解决。
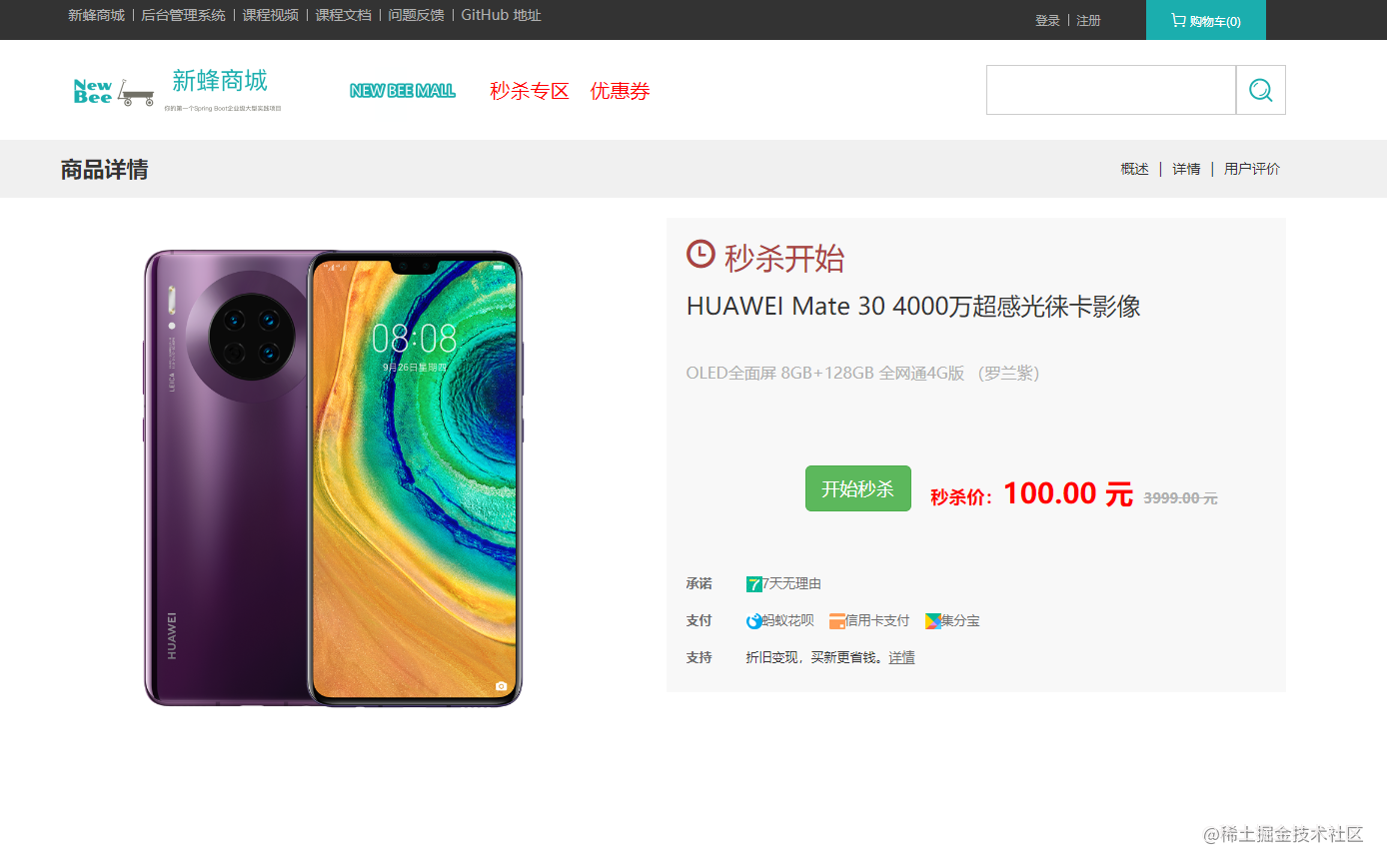
🏬waynboot-mall 是一套全部开源的 H5 商城项目,包含运营后台、H5 商城前台和后端接口三个项目。实现了一套完整的商城业务,有首页展示、商品分类、商品详情、sku 详情、商品搜索、加入购物车、结算下单、支付宝/微信支付/易支付对接、我的订单列表、商品评论等一系列功能 🔥。商城所有项目源码全部开源,绝无套路。
其实本文得核心逻辑有许多都是参考 Redission 客户端而写,对于这些常见得坑点,博主结合自身思考,业界知识总结并自己实现一个分布式锁得工具类。希望大家看了有所收获,对日常业务中 Redis 分布式锁的使用能有更深的理解。
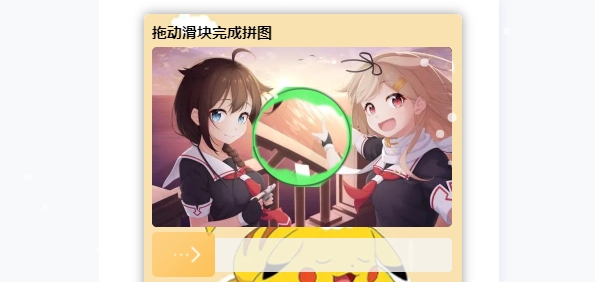
tianai-captcha 简称 tac,是一款集成滑动类、点选类的一款行为验证码,以使用简单、安全性强、界面美观、接入方便,集好看、功能多、安全性强的一款开源行为验证码工具。tianai-captcha 目前支持的行为验证码类型滑块验证码旋转验证码滑动还原验证码文字点选验证码图标验证码语序验证码刮刮乐验证码后面会陆续支持市面上更多好玩的验证码玩法... 敬请期待在线文档:http://doc.
到此,以上这些Java面试学习网站都是非常好的资源,可以帮助大家提高自己的技能和知识水平,应对各种Java面试问题。关注公众号【waynblog】每周分享技术干货、开源项目、实战经验、高效开发工具等,您的关注将是我的更新动力!
tianai-captcha 简称 tac,是一款集成滑动类、点选类的一款行为验证码,以使用简单、安全性强、界面美观、接入方便,集好看、功能多、安全性强的一款开源行为验证码工具。tianai-captcha 目前支持的行为验证码类型滑块验证码旋转验证码滑动还原验证码文字点选验证码图标验证码语序验证码刮刮乐验证码后面会陆续支持市面上更多好玩的验证码玩法... 敬请期待在线文档:http://doc.
🏬waynboot-mall 是一套全部开源的微商城项目,包含三个项目:运营后台、H5 商城和后端接口。实现了一套完整的商城业务,有首页展示、商品分类、商品详情、sku 详情、商品搜索、加入购物车、结算下单、支付宝/微信支付、订单列表、商品评论等一系列功能🔥。商城前后台项目源码全部开源,绝无套路。
