




- @Waitind_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
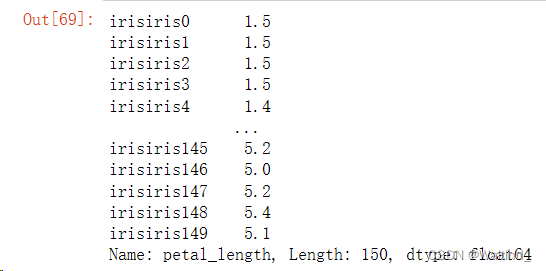
DataFrame 中设置特定的值为学生数组(None 在 Python 中通常表示 NoneType 类型,但在 pandas 中它代表 NaN,即 Not a Number,表示缺失值)。DataFrame 的前 3 行(包含第 1 行、第 2 行和第 3 行),以及所有列,并将这些行的所有值设置为 None。指定了填充缺失值的方法为 “backfill” 或 “bfill”,这是一种向前填充
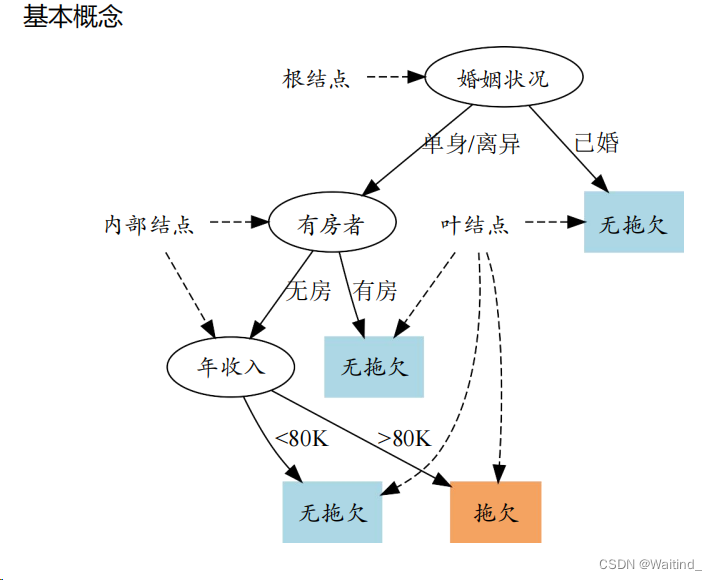
随机森林就像这个情况。它是由很多棵决策树组成的,每棵决策树都是用来解决同一个问题的,但是每棵树都是在一个不同的数据集上训练的,就像你向不同的人询问路线。你可以问很多当地人,每个当地人可能会给你一个不同的答案,有的可能会告诉你走这条路,有的可能会告诉你走那条路。在机器学习中,后剪枝是在模型训练完成,生成了一个完整的模型之后,通过评估每个节点的性能,去除那些对预测任务没有实际帮助的部分,从而简化模型。
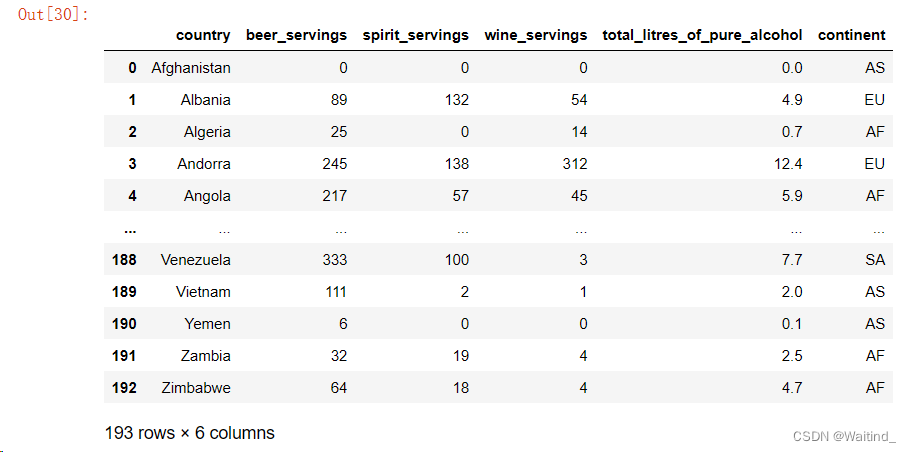
mean’ 函数计算平均值,‘max’ 函数找到每个组中的最大值,而 ‘min’ 函数找到每个组中的最小值。这意味着数据将根据不同的大陆进行划分,每个大陆的数据将被视为一个组。这意味着数据将根据不同的大陆进行划分,每个大陆的数据将被视为一个组。这意味着数据将根据不同的大陆进行划分,每个大陆的数据将被视为一个组。这意味着数据将根据不同的大陆进行划分,每个大陆的数据将被视为一个组。: 这部分指定了要对
k折交叉验证(k-fold cross-validation)是一种评估机器学习模型性能的方法,它通过将训练集分成 k 个大小相等的子集(折叠或折数),然后选择 k-1 个子集作为训练集,剩下的一个子集作为验证集(或测试集),对模型进行 k 次这样的迭代。每次迭代都会评估模型的性能,并使用所有 k 次评估的平均性能来代表模型的整体性能。训练集的每条记录用于训练的次数相同,并且恰好被检验一次。
DataFrame 中设置特定的值为学生数组(None 在 Python 中通常表示 NoneType 类型,但在 pandas 中它代表 NaN,即 Not a Number,表示缺失值)。DataFrame 的前 3 行(包含第 1 行、第 2 行和第 3 行),以及所有列,并将这些行的所有值设置为 None。指定了填充缺失值的方法为 “backfill” 或 “bfill”,这是一种向前填充
在单链接聚类中,两个聚类之间的链接距离是两个聚类中最接近的两个点的距离。在方阵中,行和列都代表城市,对角线上的元素是城市与自己之间的距离,非对角线上的元素是城市之间的距离。‘average’(平均链接):平均链接聚类中,两个聚类之间的链接距离是所有成对点的距离的平均值。‘complete’(完全链接):与单链接方法相反,完全链接聚类中,两个聚类之间的链接距离是两个聚类中最远的两个点的距离。K均值聚
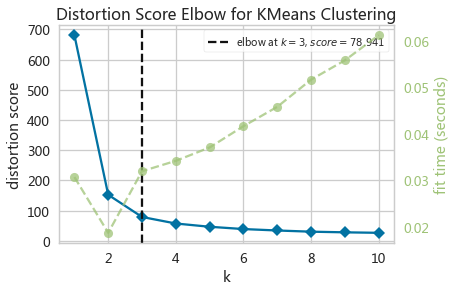
【代码】数分一般步骤——数据清洗/预处理。

k折交叉验证(k-fold cross-validation)是一种评估机器学习模型性能的方法,它通过将训练集分成 k 个大小相等的子集(折叠或折数),然后选择 k-1 个子集作为训练集,剩下的一个子集作为验证集(或测试集),对模型进行 k 次这样的迭代。每次迭代都会评估模型的性能,并使用所有 k 次评估的平均性能来代表模型的整体性能。训练集的每条记录用于训练的次数相同,并且恰好被检验一次。
DataFrame 中设置特定的值为学生数组(None 在 Python 中通常表示 NoneType 类型,但在 pandas 中它代表 NaN,即 Not a Number,表示缺失值)。DataFrame 的前 3 行(包含第 1 行、第 2 行和第 3 行),以及所有列,并将这些行的所有值设置为 None。指定了填充缺失值的方法为 “backfill” 或 “bfill”,这是一种向前填充