




- @Springfield3006
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
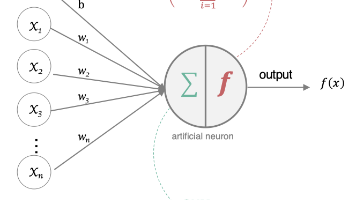
人工神经网络(ANN)是一种基于生物神经元结构的计算模型,通过多层非线性变换实现复杂模式学习。其核心由输入层、隐藏层和输出层组成,每层神经元通过加权求和和激活函数处理信息。前向传播过程将输入数据逐层转换为预测输出,反向传播则通过梯度下降优化网络参数。以包含1个隐藏层的网络为例,详细展示了从单个神经元计算到完整网络前向传播和反向传播的数学过程,包括权值更新和误差反向传递机制。这种结构使ANN能够有效
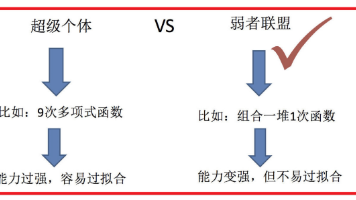
AI 目标是让机器具人类智能,ML 是实现路径(从数据学规律),DL 是 ML 分支(用多层网络处理高维数据),三者呈 AI>ML>DL 层级。发展依赖数据(决定上限)、算法(提取规律)、算力(GPU/TPU 加速)。数据由样本、特征(预测依据)、标签(目标)构成,需划训练 / 测试集防过拟合。特征工程含提取、归一化 / 标准化预处理、降维及交叉 / 多项式组合。模型需平衡复杂度防过拟合 / 欠拟
集成学习通过组合多个弱学习器提升模型性能,主要分为三类方法: Bagging(并行集成) 如随机森林,通过有放回抽样生成多个训练集 独立训练模型后平权投票 示例:贷款分类问题中,3棵决策树投票预测结果 Boosting(串行集成) 如AdaBoost,迭代训练并调整样本权重 错误样本权重增加,优秀模型获得更高投票权 示例:两轮迭代后加权投票预测贷款审批 Stacking(层级集成) 第一层基模型生
模型压缩技术概述与量化原理 模型压缩技术旨在减少深度学习模型的参数量和计算复杂度,使其能够在资源受限设备上高效部署。主要方法包括剪枝、量化、知识蒸馏和低秩分解。其中量化技术通过将高精度浮点数(如float32)转换为低精度整数(如int8),显著减小模型体积并提升推理速度。量化过程涉及缩放因子和零点的计算,通过数学映射实现浮点数到整数的转换,同时保持较小的精度损失。PyTorch和TensorFl

摘要:NLP模型评估指标是技术落地的关键,不同任务需适配不同指标。二分类任务基于混淆矩阵,衍生出准确率、精确率、召回率和F1-Score四大指标,各有适用场景:准确率适用于均衡数据,精确率关注预测准确性(如垃圾邮件过滤),召回率强调覆盖完整性(如疾病诊断),F1-Score平衡两者(如简历筛选)。文本生成任务则使用BLEU(机器翻译)、ROUGE(摘要生成)等专用指标。指标选择直接影响业务价值,需
BERT模型是NLP领域的里程碑,由Google AI在2018年提出。它采用双向Transformer架构,通过MLM和NSP预训练任务实现上下文理解,在11项NLP任务中刷新SOTA。与单向GPT不同,BERT更适合语义理解任务(如分类、问答)。后续变体如轻量化的AlBERT、优化的RoBERTa和中文适配的MacBERT进一步提升了性能。BERT的"预训练+微调"模式极大
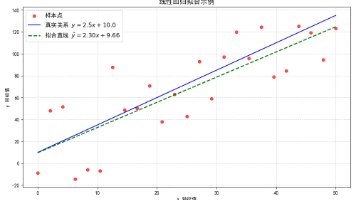
线性回归是一种通过回归方程建模自变量与因变量线性关系的分析方法。一元线性回归表达式为y=kx+b,多元线性回归为y=w₁x₁+w₂x₂+...+wₙxₙ+b。通过最小化均方误差(MSE)可以找到最佳参数。以房屋面积预测价格为例,当k=2、b=0时,回归曲线完全拟合样本数据(MSE=0)。测试新数据(75,145)时,预测值150与真实值145的误差(MSE=25)揭示了模型的泛化能力。该示例展示了
摘要: 本文系统解析了循环神经网络(RNN)及其改进模型LSTM的核心机制与应用。传统RNN通过循环记忆结构处理序列数据,但存在梯度消失问题。LSTM引入遗忘门、输入门、输出门和细胞状态四大机制,有效解决了长期依赖问题。文章详细对比了RNN与LSTM的数学表达、PyTorch实现及计算示例,并通过人名特征提取案例演示了RNN的时序计算过程。RNN适用于语音识别、文本分类等场景,而LSTM在长序列任
人工神经网络(ANN)是一种基于生物神经元结构的计算模型,通过多层非线性变换实现复杂模式学习。其核心由输入层、隐藏层和输出层组成,每层神经元通过加权求和和激活函数处理信息。前向传播过程将输入数据逐层转换为预测输出,反向传播则通过梯度下降优化网络参数。以包含1个隐藏层的网络为例,详细展示了从单个神经元计算到完整网络前向传播和反向传播的数学过程,包括权值更新和误差反向传递机制。这种结构使ANN能够有效
AI 目标是让机器具人类智能,ML 是实现路径(从数据学规律),DL 是 ML 分支(用多层网络处理高维数据),三者呈 AI>ML>DL 层级。发展依赖数据(决定上限)、算法(提取规律)、算力(GPU/TPU 加速)。数据由样本、特征(预测依据)、标签(目标)构成,需划训练 / 测试集防过拟合。特征工程含提取、归一化 / 标准化预处理、降维及交叉 / 多项式组合。模型需平衡复杂度防过拟合 / 欠拟