




- @SoulmateY
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Stable Baselines3 (SB3) 是一个强化学习的开源库,基于 PyTorch 框架构建。它是 Stable Baselines 项目的继任者,旨在提供一组可靠且经过良好测试的RL算法实现,便于研究和应用。StableBaseline3主要被应用于机器人控制、游戏AI、自动驾驶、金融交易等领域。你可以使用sb3快速进行模型训练,同时使用SwanLab进行实验跟踪与可视化。
HuggingFace 的 Transformers 是目前最流行的深度学习训框架之一(100k+ Star),现在主流的大语言模型(LLaMa系列、Qwen系列、ChatGLM系列等)、自然语言处理模型(Bert系列)等,都在使用Transformers来进行预训练、微调和推理。
TRL是一个领先的Python库,旨在通过监督微调(SFT)、近端策略优化(PPO)和直接偏好优化(DPO)等先进技术,对基础模型进行训练后优化。TRL 建立在 🤗 Transformers 生态系统之上,支持多种模型架构和模态,并且能够在各种硬件配置上进行扩展。你可以使用Trl快速进行模型训练,同时使用SwanLab进行实验跟踪与可视化。是适配于Transformers的日志记录类。

🚀 DQN实战:3分钟极速训练倒立摆控制模型 | 附完整代码+可视化训练;📌 核心技术亮点:DQN双剑合璧:融合深度神经网络与Q-Learning,通过经验回放打破数据关联性,目标网络稳定训练过程,解决高维状态空间难题;CartPole极简环境:4维状态空间+2个离散动作,完美契合入门级深度强化学习实战(附环境配置指南)
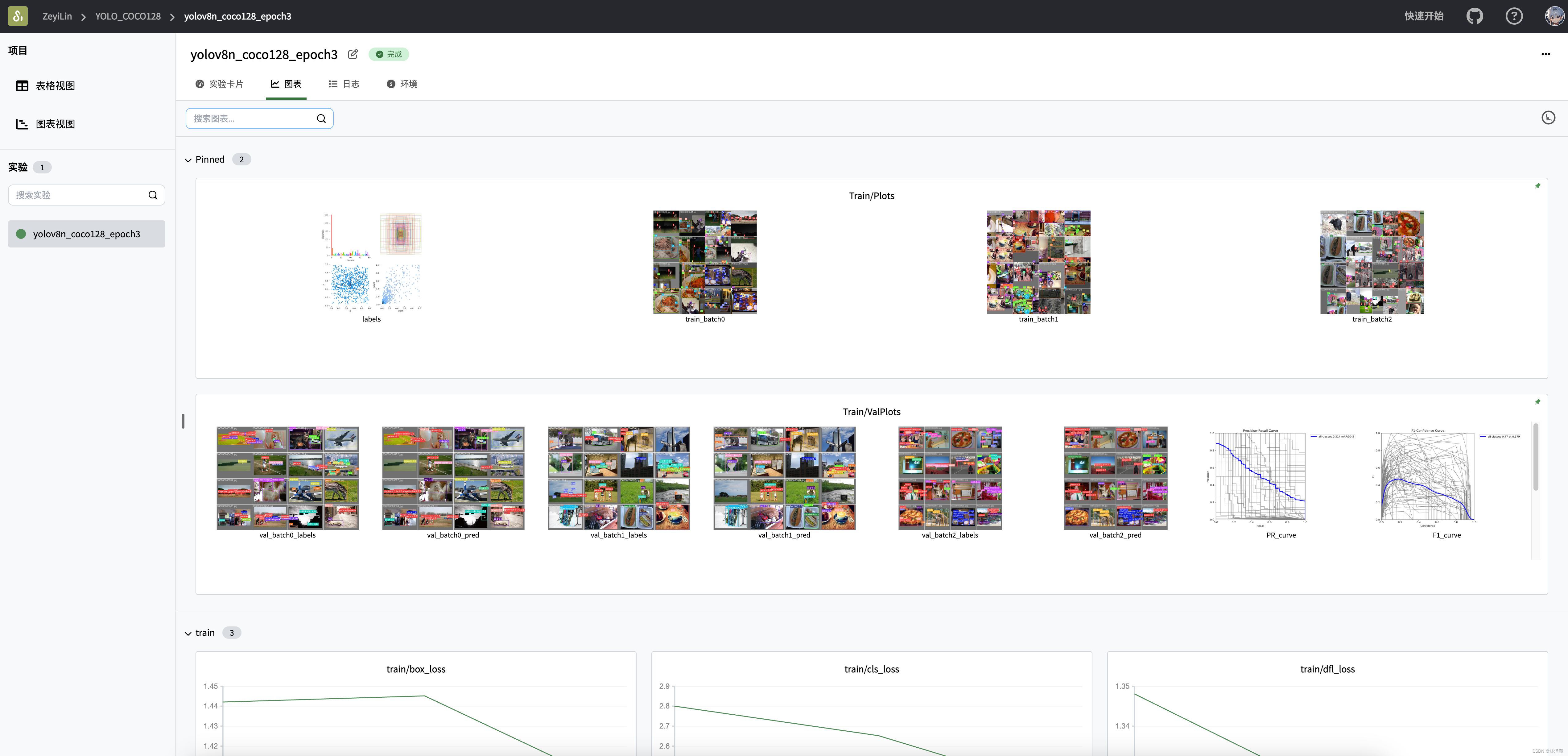
Ultralytics是YOLO官方团队推出的CV训练与推理框架,不仅支持目标检测任务,还支持分割、姿态识别、分类等更多任务。是一个深度学习实验管理与训练可视化工具,由西安电子科技大学团队打造,融合了Weights & Biases与Tensorboard的特点,能够方便地进行 训练可视化、多实验对比、超参数记录、大型实验管理和团队协作,并支持用网页链接的方式分享你的实验。你可以使用Ultraly
DiffSynth Studio是推出的一个开源的扩散模型引擎,专注于图像与视频的风格迁移与生成任务。它通过优化架构设计(如文本编码器、UNet、VAE 等组件),在保持与开源社区模型兼容性的同时,显著提升计算性能,为用户提供高效、灵活的创作工具。DiffSynth Studio 支持多种扩散模型,包括 Wan-Video、StepVideo、HunyuanVideo、CogVideoX、FLUX

探索如何将HuggingFace的Transformers框架与SwanLab无缝结合,实现高效的模型训练与实验管理!Transformers是当前最流行的深度学习框架之一,广泛应用于大语言模型(如LLaMa、Qwen、ChatGLM)和自然语言处理模型(如Bert)的预训练、微调和推理。而SwanLab则是一款强大的实验管理与可视化工具,结合了Weights & Biases和TensorBoa

verl是一个灵活、高效且可用于生产环境的强化学习(RL)训练框架,专为大型语言模型(LLMs)的后训练设计。它由字节跳动火山引擎团队开源,是HybridFlow论文的开源实现。verl目前已经被很多优秀的项目采用,如TinyZeroRAGENLogic R1等。verl 具有以下特点,使其灵活且易于使用:易于扩展的多样化 RL 算法:Hybrid 编程模型结合了单控制器和多控制器范式的优点,能够

探索如何利用 Modelscope Swift 和 SwanLab 进行高效的模型训练与实验跟踪!Swift 是 ModelScope 社区推出的强大框架,支持 450+ 大型语言模型和 150+ 多模态模型的训练、微调、推理与部署。无论是轻量级技术如 LoRA、QLoRA、LongLoRA,还是人工对齐方法如 DPO、PPO、ORPO,Swift 都能轻松应对。
(SD1.5)是由Stability AI在2022年8月22日开源的文生图模型,是SD最经典也是社区最活跃的模型之一。以SD1.5作为预训练模型,在火影忍者数据集上微调一个火影风格的文生图模型(非Lora方式),是学习的入门任务。显存要求 22GB左右在本文中,我们会使用模型在数据集上做训练,同时使用监控训练过程、评估模型效果。
