
写文章




- @RuGe_Lee
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
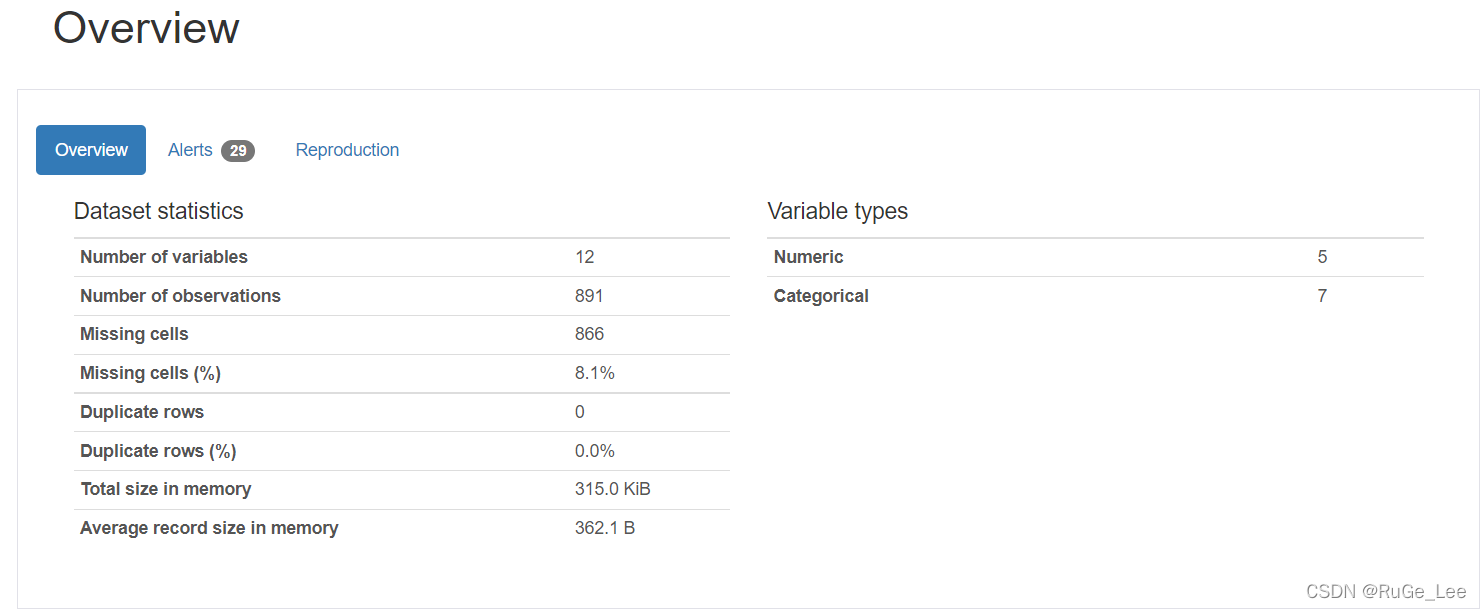
数据集分析工具pandas-profiling进阶:个性化定制配置文件与参数
个性化定制输出报告,一般我们要修改参数或者配置文件。本文介绍了常用的参数,并且修改了配置文件的一部分来演示结果。
目标检测paddlex后使用nms代码优化
改了bug1:当score最大的锚框出现在左上是少统计的bug。bug2:while有时无限循环,加个counter限制最大循环。加了最小准确率的参数,有时候有用。返回结果改成了直接返回bbox和score,避免了index的改动问题。

pandas的DataFrame中出现多数据类型的检查(一列中有多个类型)
在pandas中,如果需要查看column的类型,一般使用df.dtypes方法,它将返回每个列的数据类型。但实践中,有时会出现需要包含多种数据类型的场景,或者dataFrame包含的表格出错,出现了多种数据类型。为了观察dataFrame中的所有类型在列中的分布情况,我们写了对应的检查函数。

IEEE论文搜索多单词关键字/关键词不被拆分的个性化搜索方法(IEEE的自定义搜索)
在IEEE搜索时,在查找关键词时,若选择相关度,被引用量可能很低,反之亦然,所以,我们导出搜索结果后使用pandas进行数据清洗,来解决问题(有代码,有解析)

到底了