- @MyScale_VectorDB
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:OriginHub MyScale基于ClickHouse构建,将SQL与向量搜索结合,支持复杂AI查询。文章介绍了高级SQL技术,包括通用表达式(CTE)、子查询和表连接,并通过示例展示如何在MyScale中应用这些技术处理向量数据。重点演示了使用CTE简化向量查询、通过子查询优化连接操作的方法,说明如何高效执行结构化数据和向量数据的联合分析。这些技术增强了数据分析能力,使复杂的高维数据查

摘要:AI时代的数据治理范式转变 传统数据治理体系正面临挑战,因为AI成为数据的第一消费者。本文指出当前企业面临的核心矛盾:沿用为人设计的数据治理方式服务AI系统导致效果不佳。通过对比分析传统数据治理与AI数据准备的差异,提出数据工作应从治理转向为模型准备数据的新范式。 关键转变包括:目标从数据是否合规转向能否被模型理解使用;数据形态从结构化表格转向向量化语义表示;文章介绍了DataFlow系统的

摘要:Text2SQL技术面临模型生成SQL不可执行、复杂查询效果差等实际问题,其核心难点在于如何教会模型在真实数据库上正确生成SQL。DataFlow的Text2SQL Pipeline通过数据生成与过滤、训练数据构建和难度分类三阶段流程,确保产出高质量、可验证的训练数据。该系统支持优化现有数据或从零合成数据两种模式,并提供详细的配置教程,包括环境准备、数据库设置等实践指导,最终实现稳定生成可用
知识图谱作为大模型时代的关键基础设施,通过结构化实体、关系和三元组来解决信息过载与语义鸿沟问题。它不仅能显式表达实体间的确定关系,还能为AI系统提供可推理、可解释的知识基础。相比单纯依赖向量检索和大模型,知识图谱引入了逻辑约束和事实校验能力,有效减少"幻觉"问题。尤其在复杂问答和决策支持场景中,知识图谱通过结构化增强(GraphRAG)成为大模型的高质量"外部显存&q

摘要 人工智能技术正在重塑数据库管理领域(AI4DB),传统方法在查询优化、索引推荐等方面已展现潜力,但面临动态适应性差、泛化能力有限、运维成本高等瓶颈。大语言模型(LLM)的兴起为数据库管理带来新机遇,其强大的语言理解、推理和泛化能力推动系统向"以意图为中心"演进。LLM4DB框架包含五大核心组件:检索增强生成(RAG)、领域特定微调、提示管理、智能体和向量数据库,协同实现智

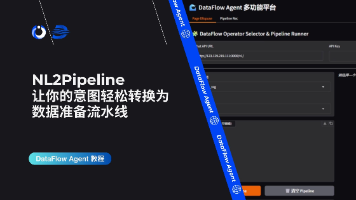
本文介绍了DataFlow-Agent框架中的NL2Pipeline功能,它能够将自然语言描述的数据处理需求自动转化为可执行的DataFlow Pipeline。NL2Pipeline通过多轮对话理解用户意图,拆解任务并映射到现有算子,生成推荐流程并支持自动调试。文章详细展示了两种使用方式:自定义手动编排和Agent自动推荐模式,包括环境部署、参数配置和Pipeline执行全过程。该系统旨在帮助工
本篇,我们将深入探讨 决定 RAG 检索质量与效率的核心组件——向量搜索(Vector Search),并结合 OriginHub MyScale AI 数据库的能力,展示在高级 RAG 系统中如何构建更强大的语义检索引擎。
摘要:OriginHub MyScale基于ClickHouse构建,将SQL与向量搜索结合,支持复杂AI查询。文章介绍了高级SQL技术,包括通用表达式(CTE)、子查询和表连接,并通过示例展示如何在MyScale中应用这些技术处理向量数据。重点演示了使用CTE简化向量查询、通过子查询优化连接操作的方法,说明如何高效执行结构化数据和向量数据的联合分析。这些技术增强了数据分析能力,使复杂的高维数据查
分块是优化 RAG 的基础步骤,目标是将长文档拆分为 LLM 可处理的“小单元”。这些分块在嵌入后存入向量数据库,应用在查询时通过“相似度检索”快速找回最相关的内容。
DataFlow 是一款开源模型数据准备框架,专为大模型自动化、体系化输出高质量数据。本文旨在提供安装部署 DataFlow 的最佳实践。