




- @Mrxiao_bo
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
聊到上线,方向变了——而且是合理地变。这东西要长期挂公网给人用,Node 那套部署还得装运行时、起进程、配守护、挂了得拉起。我后端本就是 Java,干脆整体落到 Spring Boot 3.3.5 + Java 17:打成单个可执行 jar,配多阶段 Dockerfile(maven 先构建、产物塞进 jre 运行镜像),一拉即起,前置Nginx 反代 + Let’s Encrypt 自动签证书。
绕回开头那个"读档键"。跑完这一圈,我的判断是:CubeSandbox 确实把"给运行中的 Agent 沙箱做存档、读档、分身"这件事,做成了一行 SDK 就能调的能力,底层用 Rust + KVM + XFS reflink 把它做得够快够便宜。对做 Agent 平台、Code Interpreter、或者 RL 训练采样的人来说,这套"快照 / 回滚 / 克隆"是实打实能省事的——尤其那个"退

绕回开头那个"读档键"。跑完这一圈,我的判断是:CubeSandbox 确实把"给运行中的 Agent 沙箱做存档、读档、分身"这件事,做成了一行 SDK 就能调的能力,底层用 Rust + KVM + XFS reflink 把它做得够快够便宜。对做 Agent 平台、Code Interpreter、或者 RL 训练采样的人来说,这套"快照 / 回滚 / 克隆"是实打实能省事的——尤其那个"退
还在为"这代码在我电脑上能跑"抓狂?VSCode Remote-SSH就像给IDE装了"任意门"——在本地窗口编辑远程服务器的代码,用Windows电脑调试Linux环境,甚至直接操作WSL子系统
做有声书的朋友是不是总遇到:用EasyVoice生成了自然的AI语音,想让团队成员一起试听调整,却只能导出音频文件发群里?本地部署虽然能保护文本版权,但“文件传输”让协作变成“版本灾难”📄。别慌,内网穿透来帮忙,让你的EasyVoice变成“云端配音棚”,团队实时试听修改,有声内容创作从此“安全又高效”!EasyVoice的核心功能就像“私人配音演员”,支持20+种音色(新闻播报/情感朗读/动漫
把智能体能力接进鸿蒙应用时,最容易走偏的一步,是先做一个聊天框。输入框、发送按钮、气泡列表,看起来很快能跑起来,但联调时真正需要看的并不是一句回复,而是任务现在处在哪个阶段:服务是否在线、模型识别出了什么意图、准备调用哪个工具、是否需要确认、失败时错误落在哪里。这次做的是一个更偏工程侧的 Agent 工作台。页面不追求复杂交互,只保留几个必要对象:本机 Agent Gateway、ArkUI 消息
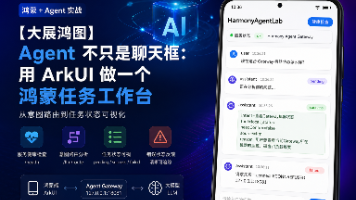
把智能体能力接进鸿蒙应用时,最容易走偏的一步,是先做一个聊天框。输入框、发送按钮、气泡列表,看起来很快能跑起来,但联调时真正需要看的并不是一句回复,而是任务现在处在哪个阶段:服务是否在线、模型识别出了什么意图、准备调用哪个工具、是否需要确认、失败时错误落在哪里。这次做的是一个更偏工程侧的 Agent 工作台。页面不追求复杂交互,只保留几个必要对象:本机 Agent Gateway、ArkUI 消息
聊到上线,方向变了——而且是合理地变。这东西要长期挂公网给人用,Node 那套部署还得装运行时、起进程、配守护、挂了得拉起。我后端本就是 Java,干脆整体落到 Spring Boot 3.3.5 + Java 17:打成单个可执行 jar,配多阶段 Dockerfile(maven 先构建、产物塞进 jre 运行镜像),一拉即起,前置Nginx 反代 + Let’s Encrypt 自动签证书。
2026年4月16日,Anthropic正式发布了旗下最新旗舰模型——。Opus 4.7定价与Opus 4.6持平,但由于新版分词器的调整,实际输入消耗的token可能增长0%–35%;加之思考强度高于前代,输出token的消耗也会有所增加。因此综合来看,,这一点在上量前需提前评估。本指南将系统介绍Claude Opus 4.7的使用方法、核心升级点,以及如何将它的新能力落地到你的日常工作中。

最近帮一家能源企业做数字化转型咨询的时候,他们的CTO跟我吐槽:"我们现在的数据库架构就像一个补丁摞补丁的老房子,MySQL存元数据、Redis做缓存、HBase存历史数据,还要维护Kafka做数据流转。每次出问题,光是定位问题就要跨好几个团队。"这个场景听起来是不是很熟悉?在大数据时代,特别是物联网、工业互联网领域,时序数据的爆发式增长让传统的数据库架构越来越力不从心。今天我想从大数据的角度,聊
