




- @L888666Q
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
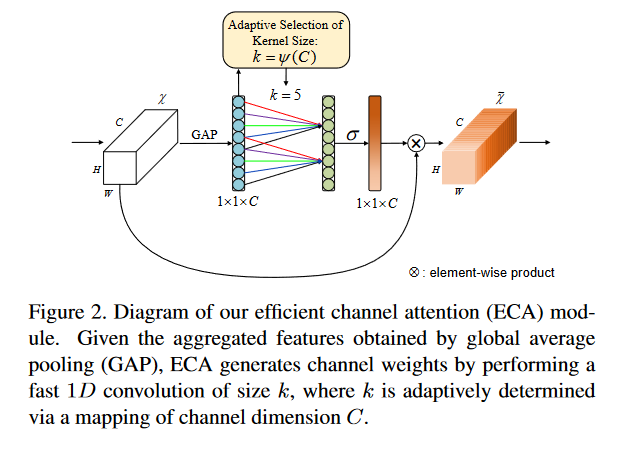
SENet采用的 降维操作 会对通道注意力的预测产生 负面影响,且获取依赖关系效率低且不必要 ;基于此,提出了一种针对CNN的高效通道注意力(ECA)模块,避免了降维,有效地实现了 跨通道交互 ;
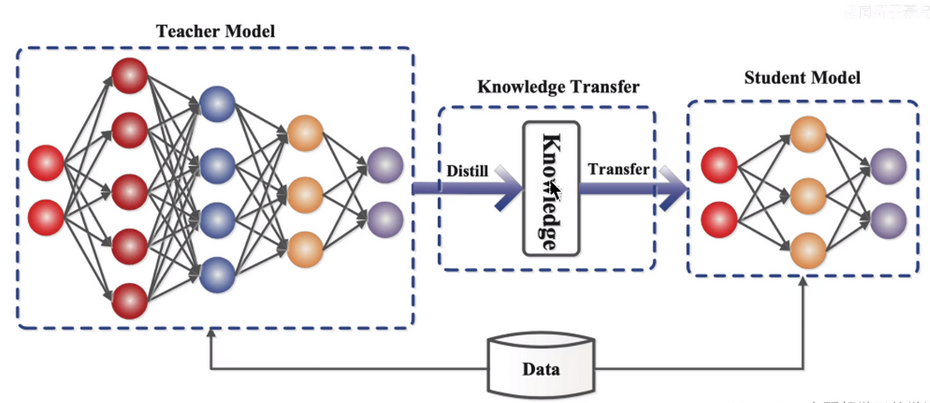
知识蒸馏的算法理论,就是将庞大的教师模型的重要的东西让学生模型来逼近和训练,让参数量少的学生模型能够和教师模型的效果差不多,或者比老师模型效果更好。
神经网络特意用随机性来保证,能通过有效学习得到问题的近似函数。采用随机性的原因是:用它的机器学习算法,要比不用它的效果更好。在神经网络中,最常见的随机性包含以下几个地方:初始化的随机性,比如权值正则化的随机性,比如dropout层的随机性,比如词嵌入最优化的随机性,比如随机优化

W:输入特征图的宽,H:输入特征图的高,K:卷积核宽和高,Ppadding(需要填充的0的个数),N:卷积核的个数,S:步长width_out:卷积后输出特征图的的宽,height_out:卷积后输出特征图的高。

知识蒸馏的算法理论,就是将庞大的教师模型的重要的东西让学生模型来逼近和训练,让参数量少的学生模型能够和教师模型的效果差不多,或者比老师模型效果更好。
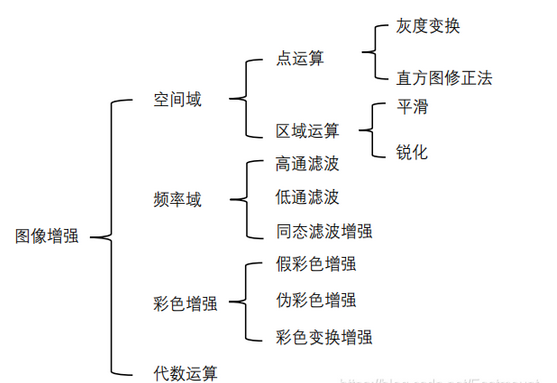
直方图均衡化是图像处理领域中利用图像直方图对对比度进行调整的方法。通过这种方法,亮度可以更好地在直方图上分布。这样就可以用于增强局部的对比度而不影响整体的对比度,直方图均衡化通过有效地扩展常用的亮度来实现这种功能。全局直方图均衡该方法主要优点是算法简单、速度块、可自动曾倩图像;缺点是对噪声敏感、细节信息容易丢失,在某些结果区域产生过增强的问题。局部直方图均衡该方法优点是局部自适应,可最大限度的增强
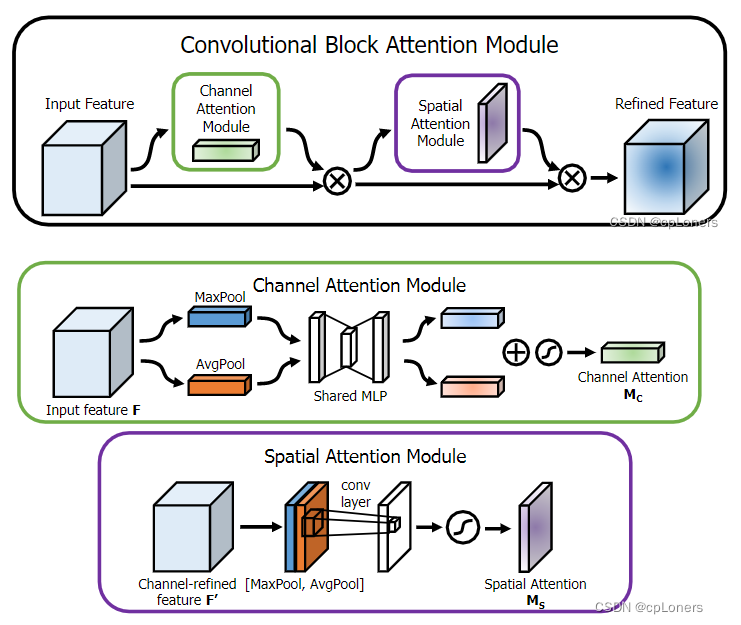
常用的注意力机制多为SE Attention和CBAM Attention。它们基本都可以当成一个简单的网络。例如SE注意力机制,它主要就是由两个全连接层组成,这就是一个简单的MLP模型,只是它的输出变了样。所以,在我们把注意力机制加入主干网络里时,所选注意力机制的复杂程度也是我们要考虑的一个方面,因为增加注意力机制,也变相的增加了我们网络的深度,大小。
神经网络特意用随机性来保证,能通过有效学习得到问题的近似函数。采用随机性的原因是:用它的机器学习算法,要比不用它的效果更好。在神经网络中,最常见的随机性包含以下几个地方:初始化的随机性,比如权值正则化的随机性,比如dropout层的随机性,比如词嵌入最优化的随机性,比如随机优化
知识蒸馏的算法理论,就是将庞大的教师模型的重要的东西让学生模型来逼近和训练,让参数量少的学生模型能够和教师模型的效果差不多,或者比老师模型效果更好。
首先对于每个像素(i, j),计算以(i, j)为中心的2H2W的矩形区域内图像1和图像2之间的差值之和,并对计算面积(400)以及对图像边界进行了一定的限制判断,然后将差值之和均值的最小值将其作为最佳匹配位置。最后,函数根据最佳匹配位置计算出图像2相对于图像1的平移量(dx,dy)和距离(distance)。
