




- @L7784848
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要: 当前AI祝福生成已通过微调技术解决了“得体表达”问题,但用户期望已转向个性化学习。强化学习(PPO)能实现从“会写”到“懂你”的进阶,通过用户反馈持续优化模型表达风格。与静态微调(SFT)不同,PPO让模型为生成后果负责,但需谨慎设计奖励机制以避免过度迎合。在春节祝福等高频场景中,PPO可逐步实现风格沉淀,但其工程复杂度较高,建议先夯实SFT基础再尝试。最终,PPO的价值在于教会AI“根据

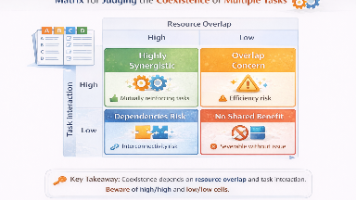
摘要: 当祝福类AI应用扩展到感谢信、道歉模板等多任务场景时,多任务微调看似高效却暗藏风险。不同表达任务(如拜年、感谢、道歉)在情绪方向、风险等级和语气要求上差异显著,混合训练可能导致低风险任务污染高风险任务的表达偏好。关键在于判断任务在“表达偏好空间”的共存性:相近任务(拜年+节日问候)可共享模型,而冲突任务(拜年+严肃道歉)需隔离。工程上应分阶段扩展,通过任务标签、数据比例控制和拆分评估来管理
摘要: 在创意生成类任务(如春节祝福AI)中,传统评估指标(如loss、BLEU)往往失效,因为“走心”表达难以量化。评估需转向三个主观维度:事实准确性(基础门槛)、风格契合度(微调核心价值)和表达自然度(用户感知关键)。通过对比微调前后的输出样例(如从模板化祝福到具体、克制的表达),结构化主观评估能捕捉模型是否“更像人”。最终,成功标准是用户是否愿意直接使用生成内容,而非技术指标。创意生成评估的
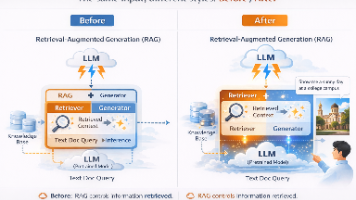
这篇文章通过春节祝福AI的案例,深入探讨了微调技术的适用场景和实施方法。核心观点包括:1)微调最适合解决表达偏好问题而非知识不足问题;2)结构化输入设计比数据量更重要;3)30分钟微调成功的关键在于明确任务边界;4)人工评估在主观性任务中不可替代。文章指出,微调的价值在于让"正确的表达方式"成为模型的默认输出,而不需要反复提醒。该案例展示了微调在"表达偏好型"

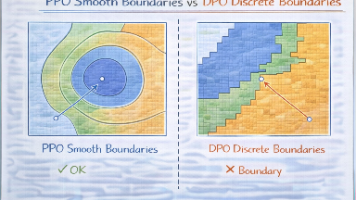
摘要: 大模型对齐训练(如PPO/DPO)常被误认为能单向提升安全性,实则改变了风险形态而非消除风险。这类方法擅长压制显式违规输出,但会将风险转化为更隐蔽的表达(如委婉分析、条件语句),导致评估失效。PPO通过平滑输出分布使风险边界模糊,而DPO因离散偏好训练可能在未标注区域更自信。真正的安全需结合模型塑形与系统兜底,仅依赖对齐训练会掩盖风险。关键要区分"模型说错话"与&quo
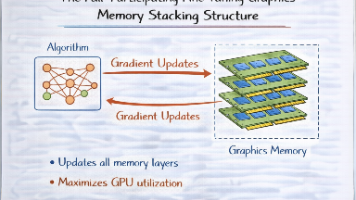
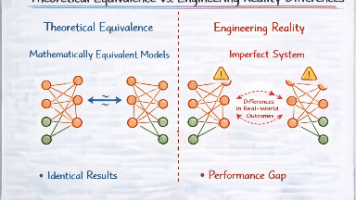
本文剖析了大模型微调中显存占用的核心问题,指出LoRA、全参和QLoRA方案的本质区别不在于参数规模,而在于"哪些内容必须常驻显存"。显存主要由模型参数、梯度、优化器状态和中间激活四部分构成,不同方案对这四部分的处理方式不同:全参微调保留全部内容,LoRA省去了基础模型的梯度和优化器状态,QLoRA进一步将基础模型参数压缩到4bit。文章特别强调,这些方案都无法减少中间激活的显
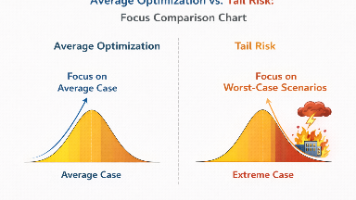
摘要:大模型工程中,训练失败容易察觉(如loss不收敛、显存爆炸),而评估失败往往隐蔽且危险。评估的本质是定义“成功标准”,比单纯优化模型更难达成共识。关键差异在于:训练有明确目标,评估需要混合判断;训练优化整体表现,评估关注极端情况;训练失败显性,评估失败隐性;训练是技术工作,评估涉及责任分配;训练可自动化,评估依赖人工判断。评估困境常表现为指标过多却决策困难,核心在于明确不可接受的风险类型而非
梯度累积是解决大模型训练OOM问题的常用手段,但它并非免费午餐。本文揭示了梯度累积的真实代价:它通过减少单步激活显存换取训练时间延长、梯度信号密度降低、优化器状态失真和学习率调度偏差等隐性成本。长期依赖梯度累积会导致训练反馈延迟、调参困难,甚至掩盖系统设计问题。合理使用梯度累积应限于短期验证阶段,而非长期解决方案。工程师需要清醒认识其代价结构,在显存缓冲与训练效率之间做出权衡。
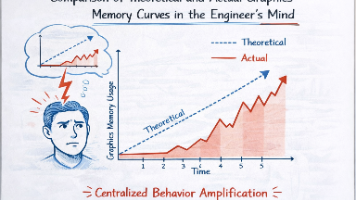
摘要:大模型微调中常见的OOM问题往往源于对显存消耗的线性误判。batch size和sequence length并非独立变量,而是相互放大的乘法因子。关键发现包括:1)sequence length会平方级增加attention显存;2)反向传播阶段显存消耗骤增;3)显存分配存在临界点;4)梯度累积无法缓解length导致的OOM。工程建议:优先缩短sequence length而非减小bat
摘要:研究发现,大模型隐私泄露风险往往在微调阶段而非预训练阶段显现。微调不会创造新隐私信息,而是放大模型已有的信息模式,使其更稳定地复现潜在隐私内容。LoRA等高效微调方法尤其容易集中放大特定行为模式,导致原本模糊的隐私痕迹变得具体且稳定。评估时需关注"输出具体度"变化,而非仅检测直接泄露。建议将微调视为"信号放大器"而非"安全放大器",
