




- @Kakaxiii
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
部分内容参考文档:https://blog.csdn.net/sinat_28461591/article/details/147031798。
近年来,人工智能应用,尤其是生成式大型语言模型,在医学领域蓬勃发展。本研究对的生成式大型语言模型(LLM)——ChatGPT-4o(OpenAI)、Grok-3(xAI)、Gemini-2.0 Flash(Google)和DeepSeek-V3(DeepSeek)——进行了结构化的比较分析,以评估它们在。方法:我们通过分阶段、逐步增加的复杂度案例来评估模型的医学知识回忆和临床推理能力,并由专家评分
LightRAG 定制化抽取及neo4j导入
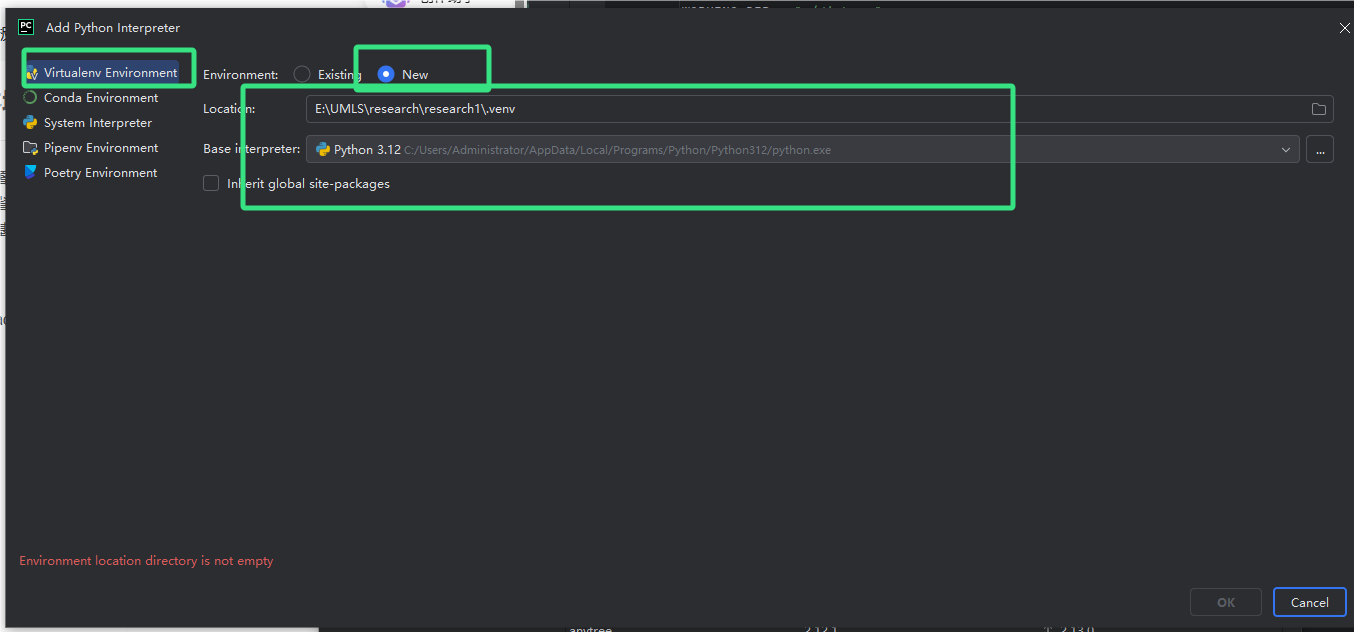
之前在服务器部署neo4j失败,无奈只能在本地部署,导致后期所有使用的知识图谱数据都存在本地,这里为了节省时间,先在本地安装LigthRAG完成整个实验流程,后续在学习各种服务器部署和端口调用。从基础和简单的部分先做起来吧。
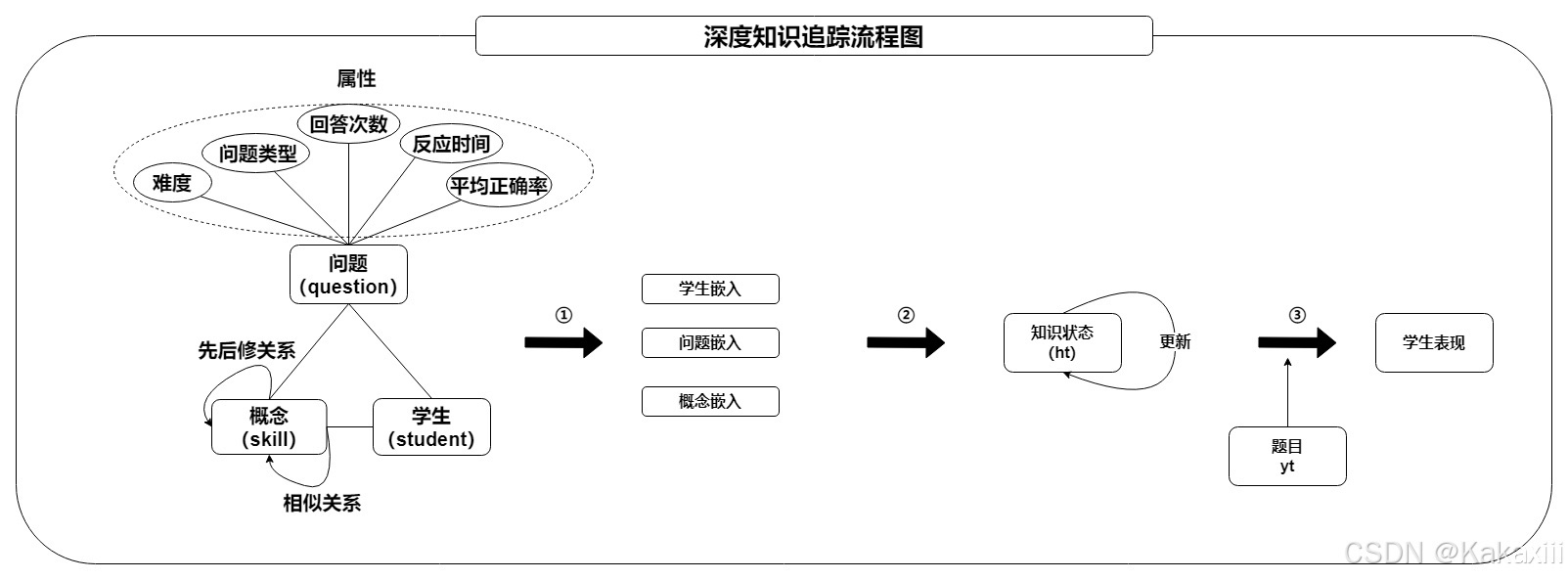
初始化一个知识状态的隐藏层,通过问题-答案的序列,去更新这个隐藏层状态的参数,最后,将预测问题输入,输出答案结果。相关模型基本介绍DKT利用LSTM层对学生的知识状态进行编码,以预测学生的反应表现。DKT+引入正则解决重构和不一致预测的问题。DKTF模拟了学生的遗忘行为。KQN使用学生知识状态编码器和技能编码器通过点积来预测学生的反应表现。DKVMN设计一个静态密钥矩阵来存储不同知识中心之间的关系
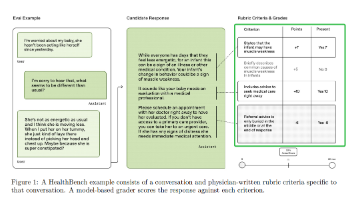
OpenAI推出HealthBench医疗评估系统,旨在全面测试大语言模型在医疗场景中的表现。该基准包含5000个模拟真实医疗对话,由262名国际医生设计48562个评估维度,涵盖临床准确性、沟通质量等关键指标。研究发现,2025年模型表现已接近或超越部分医生水平,但在跨地区医疗适配、信息完整性等方面仍有提升空间。HealthBench采用开放式评估方式,更贴近实际医疗互动,为AI医疗应用提供了更
NLM于1986年开始了UMLS(Unified Medical Language Systems:一体化医学语言系统)的研究与应用,其目的是实现跨语言和跨数据库的情报检索。UMLS由四部分组成:超级叙词表、语义网络、情报源图谱和专家词典。超级叙词表是UMLS的核心部分,它收录了生物医学领域60多种词表和分类表中的语词,对于这些来源各异的语词,超级叙词表保留了它们在原来叙词表中的意义、关系等,并以

初始化一个知识状态的隐藏层,通过问题-答案的序列,去更新这个隐藏层状态的参数,最后,将预测问题输入,输出答案结果。相关模型基本介绍DKT利用LSTM层对学生的知识状态进行编码,以预测学生的反应表现。DKT+引入正则解决重构和不一致预测的问题。DKTF模拟了学生的遗忘行为。KQN使用学生知识状态编码器和技能编码器通过点积来预测学生的反应表现。DKVMN设计一个静态密钥矩阵来存储不同知识中心之间的关系