




- @Jason_android98
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
工作原因一直想配置一台自己的深度学习工作站服务器,之前自己看完paper想做一些实验或者复现模型的时候只能用自己的日常PC来跑很麻烦…一方面电脑得装双系统,干活的时候就不能用作其他用途了;另一方面,即使是没有使用流程的问题,GTX1080的性能也还是弱了一些,更何况我用的是一个A4迷你机箱,长时间高负载的训练任务也不太可靠。
为了保证框架的可扩展性,MDL对 layer 层进行了抽象,方便框架使用者根据模型的需要,自定义实现特定类型的层,使用 MDL 通过添加不同类型的层实现对更多网络模型的支持,而不需要改动其他位置的代码。一般来说,参数修剪和共享,低秩分解和知识蒸馏方法可以用于全连接层和卷积层的CNN,但另一方面,使用转移/紧凑型卷积核的方法仅支持卷积层。对机器学习模型的训练是一项很重的工作,Core ML 所扮演的
1.实践是检验真理的唯一标准2.无他但手熟尔。
半监督学习通过利用大量无标签数据来训练更精确、更鲁棒的模型,在未来有着重要的研究和应用价值。研究员们期待通过USB这一工作,能够予力学术界和工业界在半监督学习领域取得更大的进展。
在本文中,作者提出了向量量化知识蒸馏(VQ-KD)来训练视觉Transformer预训练的视觉标记器。VQ-KD 离散化连续语义空间,为mask图像建模提供监督,而不是依赖图像像素。语义视觉标记器极大地改进了 BEIT 预训练并显着提高了下游任务的传输性能。此外,引入了 CLStoken预训练机制,以明确鼓励模型生成全局图像表示,缩小补丁级预训练和图像级表示聚合之间的差距。......
大规模的单流预训练在图文检索中表现出显着的性能。遗憾的是,由于注意力层重,它面临着推理效率低的问题。最近,具有高推理效率的 CLIP 和 ALIGN 等双流方法也显示出了可观的性能,但是它们只考虑了两个流之间的实例级对齐(因此仍有改进的空间)。为了克服这些限制,作者提出了一种新的协作双流视觉语言预训练模型,称为 COTS,用于通过增强跨模态交互来进行图像文本检索。除了通过动量对比学习进行实例级对齐
工作原因一直想配置一台自己的深度学习工作站服务器,之前自己看完paper想做一些实验或者复现模型的时候只能用自己的日常PC来跑很麻烦…一方面电脑得装双系统,干活的时候就不能用作其他用途了;另一方面,即使是没有使用流程的问题,GTX1080的性能也还是弱了一些,更何况我用的是一个A4迷你机箱,长时间高负载的训练任务也不太可靠。
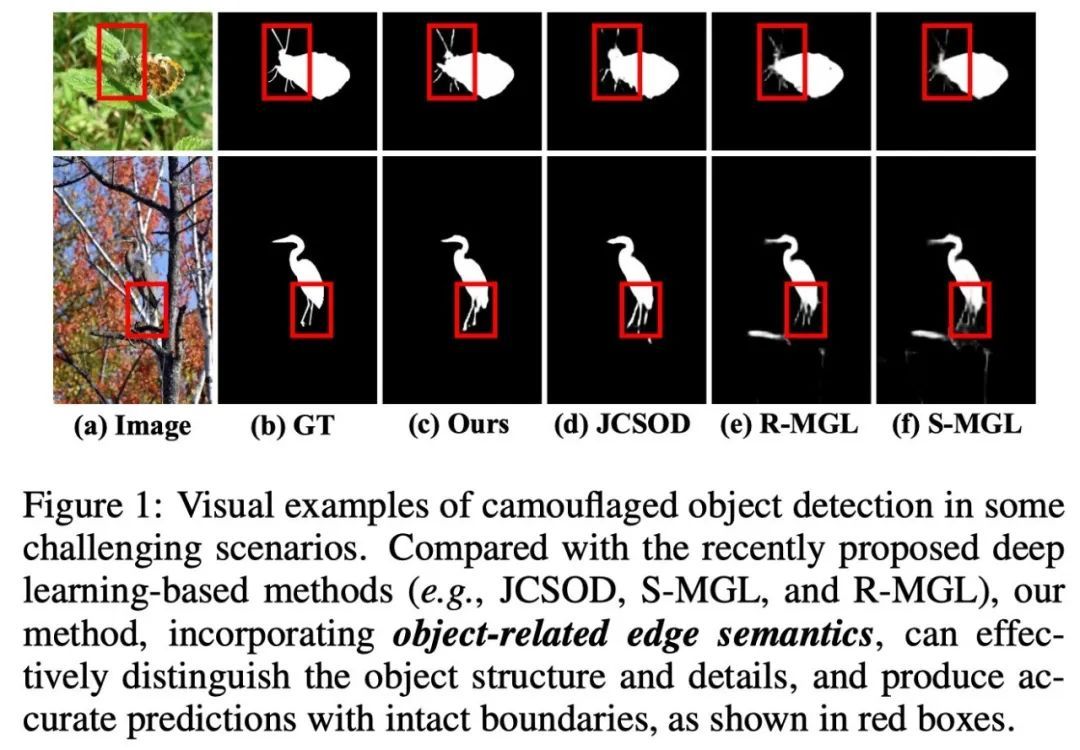
本篇分享IJCAI 2022 论文『Boundary-Guided Camouflaged Object Detection』,内大Ð&石大&UAE提出边界引导的伪装目标检测模型BGNet,性能SOTA!代码已开源!详细信息如下:论文地址:https://arxiv.org/abs/2207.00794代码地址:https://github.com/thograce/B
【写在前面】构建鲁棒的通用对目标测框架需要扩展到更大的标签空间和更大的训练数据集。然而,大规模获取数千个类别的标注成本过高。作者提出了一种新方法,利用最近视觉和语言模型中丰富的语义来定位和分类未标记图像中的对象,有效地生成用于目标检测的伪标签。从通用的和类无关的区域建议(region proposal)机制开始,作者使用视觉和语言模型将图像的每个区域分类为下游任务所需的任何对象类别。作者演示了生成
1.实践是检验真理的唯一标准2.无他但手熟尔。