




- @Jason_Orton
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
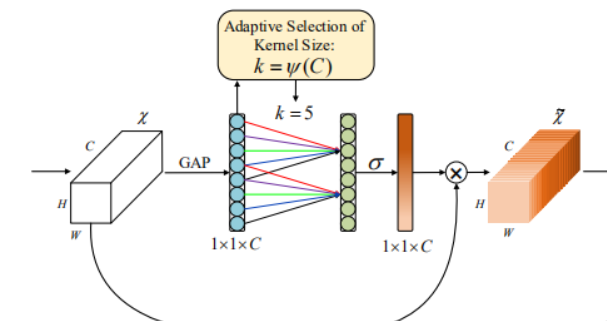
注意力机制(Attention Mechanism)是近年来在深度学习中非常流行的一种技术,特别是在自然语言处理(NLP)、计算机视觉等任务中,具有显著的效果。它的核心思想是模仿人类在处理信息时的注意力分配方式,根据不同部分的重要性给予不同的关注程度。
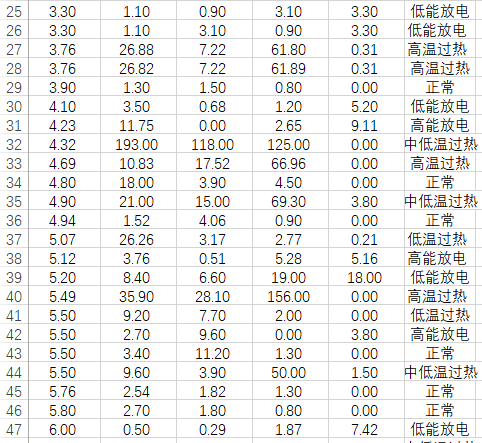
本人自己整理过的数据集,共748组数据,包含8种故障类型(含正常):数据获取跳转最后一行。数据有论文来源,现在下单另外加送两篇含有故障数据的论文(与这748组不重复)
生成对抗网络(GAN)是一种深度学习框架,由两个神经网络模型组成:生成器(Generator)和判别器(Discriminator)。这两个网络以对抗的方式进行训练,生成器的目标是生成尽可能真实的样本,而判别器则尝试区分生成样本和真实样本。生成对抗网络(GAN)以其强大的生成能力和灵活性,推动了人工智能领域的革命,特别是在图像生成、数据增强和文本生成等方面展现出了巨大的潜力。

生成对抗网络(GAN)是一种深度学习框架,由两个神经网络模型组成:生成器(Generator)和判别器(Discriminator)。这两个网络以对抗的方式进行训练,生成器的目标是生成尽可能真实的样本,而判别器则尝试区分生成样本和真实样本。生成对抗网络(GAN)以其强大的生成能力和灵活性,推动了人工智能领域的革命,特别是在图像生成、数据增强和文本生成等方面展现出了巨大的潜力。
本人自己整理过的数据集,共748组数据,包含8种故障类型(含正常):数据获取跳转最后一行。数据有论文来源,现在下单另外加送两篇含有故障数据的论文(与这748组不重复)
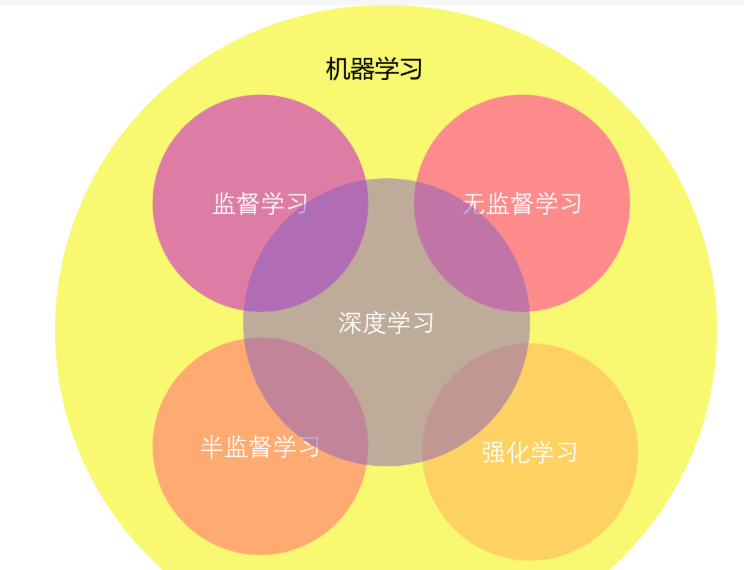
强化学习是一种通过智能体(Agent)与环境(Environment)互动并根据获得的奖励(Reward)来进行学习的机器学习方法。与监督学习不同,强化学习没有明确的标签数据,而是依赖智能体通过探索(exploration)和利用(exploitation)来学习最优策略。强化学习作为一种重要的机器学习方法,正在改变我们与环境互动的方式。它不仅在理论研究中具有深远的影响,在实际应用中也展现了巨大的
生成对抗网络(GAN)是一种深度学习框架,由两个神经网络模型组成:生成器(Generator)和判别器(Discriminator)。这两个网络以对抗的方式进行训练,生成器的目标是生成尽可能真实的样本,而判别器则尝试区分生成样本和真实样本。生成对抗网络(GAN)以其强大的生成能力和灵活性,推动了人工智能领域的革命,特别是在图像生成、数据增强和文本生成等方面展现出了巨大的潜力。
决策树(Decision Tree)是一种基于树形结构的机器学习算法,适用于分类和回归任务。其核心思想是通过一系列的规则判断,将数据集不断划分,最终形成一棵树状结构,从而实现预测目标。在决策树中,每个内部节点表示一个特征,每个分支代表一个特征的取值,每个叶子节点对应一个类别或预测值。决策树的目标是构建一棵能够有效区分不同类别的树,并在测试数据上保持较好的泛化能力。决策树是一种经典的机器学习算法,适
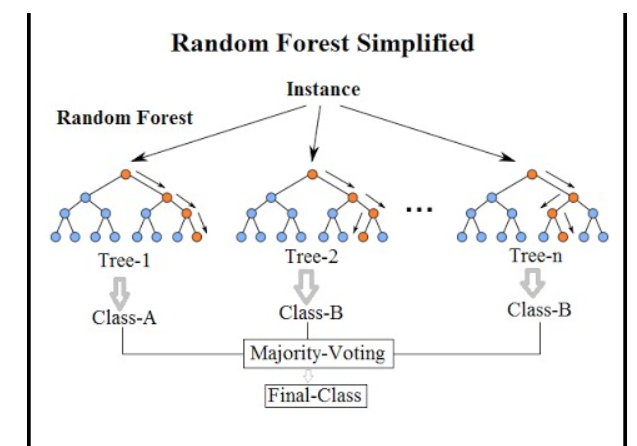
简单来说,随机森林是一种由多个决策树(Decision Tree)组成的集成学习方法。每一棵决策树都是对数据集进行特征选择和划分的“模型”,但单棵树的预测结果可能会存在较大的误差。而通过组合多棵决策树的预测结果,随机森林能够提高整体模型的准确性和鲁棒性。总的来说,随机森林作为一种集成学习模型,凭借其强大的预测能力、较低的过拟合风险和良好的适应性,已经成为数据科学领域中重要的工具之一。无论是在医疗、
目的:降维,减少数据的维度,同时保留尽可能多的原始数据的方差。标准化数据:为了使每个特征对总的方差贡献相似,通常需要对数据进行标准化处理。计算协方差矩阵:确定数据集中特征之间的协方差。计算特征值和特征向量:从协方差矩阵中提取特征值和特征向量。选择主成分:选择前k个特征向量(主成分),对应的特征值最大,这些主成分解释了数据中最多的方差。转换数据:将原始数据投影到选定的主成分上,得到降维后的数据。
