




- @Farah_Y
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
反向求导因为反向求导需要记住计算的中间结果,因此消耗资源多。正向求导。

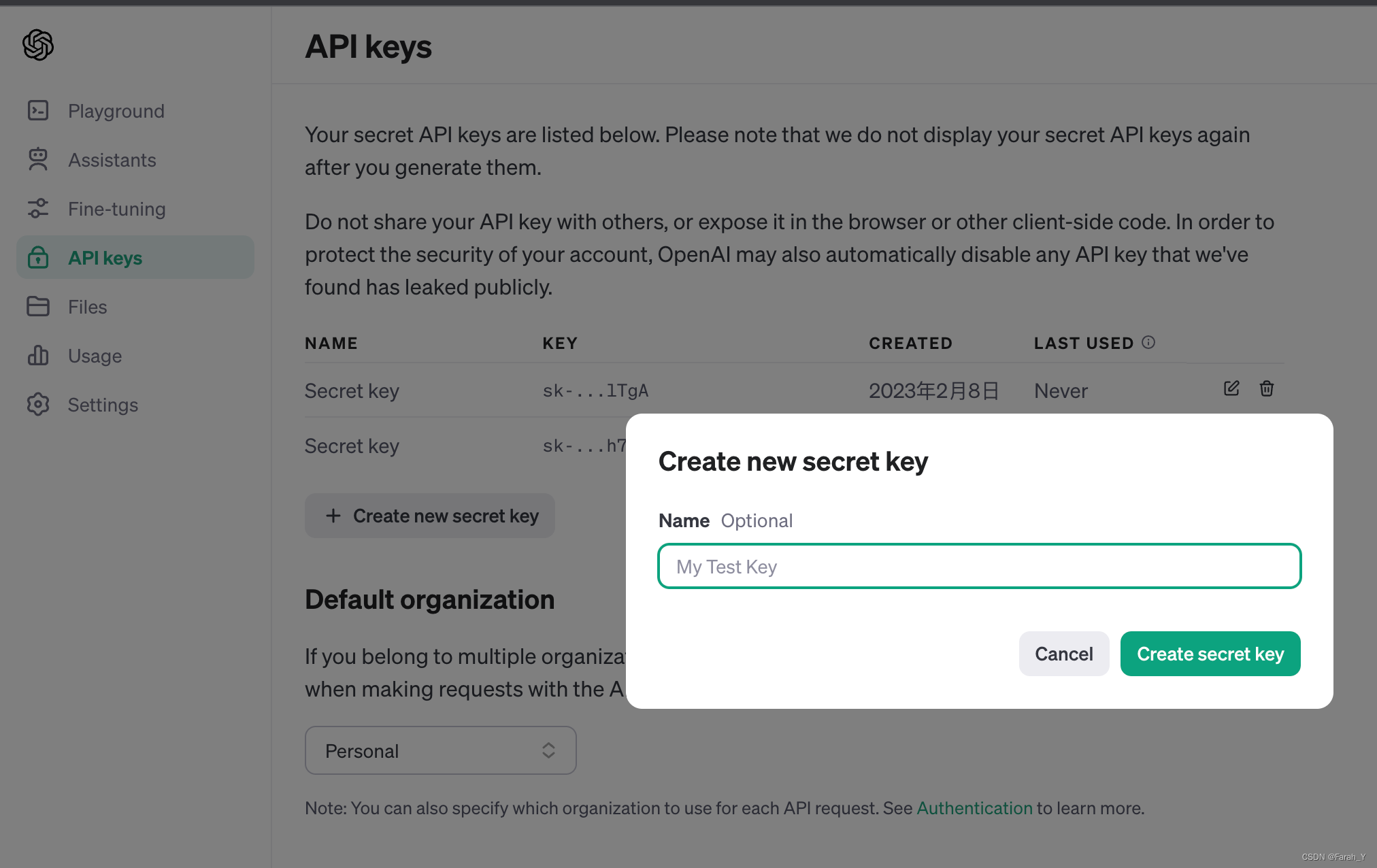
最初是NLP研究中为下游任务设计出来的一种任务专属的输入模板,类似于一种任务对应一种prompt。在ChatGPT推出并获得大量应用之后,开始被推广为给大模型的所有输入。即,每一次访问大模型的输入为一个Prompt,而大模型给我们的返回结果为Completion。
语言建模最早使用统计学习的方法,通过前面的词汇来预测下一个词汇。其在理解复杂语言规则方面存在一定局限性。之后引入了深度学习的思想,使用神经网络模型来更好的捕捉语言中的复杂关系。随着Transformer架构的神经网络模型引入,通过大量的文本数据训练,模型可以深入理解语言规则和模式。同时研究人员发现,随着语言模型规模的扩大,比如增加模型大小和使用更多的训练数据,模型展现出了惊人的能力,也就是大语言模
prompt就是用户与大模型交互输入的代称。和。
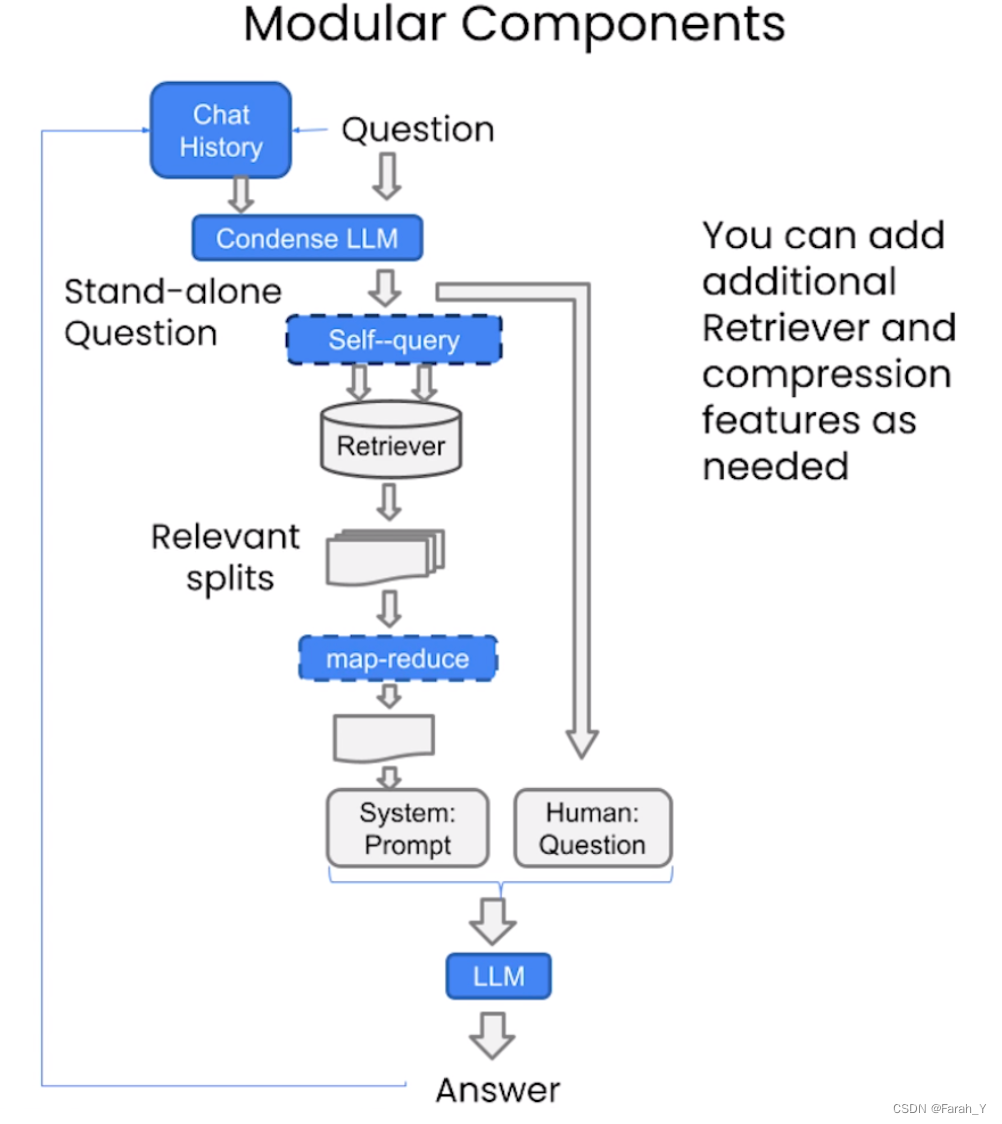
向量数据库是用于高效计算和管理大量向量数据的解决方案。向量数据库是一种专门用于存储和检索向量数据(embedding)的数据库系统。它主要关注的是向量数据的特性和相似性。在向量数据库中,数据被表示为向量形式,每个向量代表一个数据项。这些向量可以是数字、文本、图像或其他类型的数据。向量数据库使用高效的索引和查询算法来加速向量数据的存储和检索过程。Langchain 集成了超过 30 个不同的向量存储
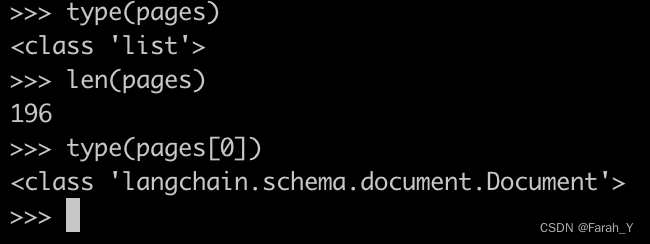
主要学习第四章:多层感知机感知机是一个二分类模型,它的求解算法等价于使用批量大小为1的梯度下降。它不能拟合XOR函数,导致了第一次AI寒冬这个task主要是学习了感知机的原理、代码实现,以及模型的一些有关知识b。
最初是NLP研究中为下游任务设计出来的一种任务专属的输入模板,类似于一种任务对应一种prompt。在ChatGPT推出并获得大量应用之后,开始被推广为给大模型的所有输入。即,每一次访问大模型的输入为一个Prompt,而大模型给我们的返回结果为Completion。
向量数据库是用于高效计算和管理大量向量数据的解决方案。向量数据库是一种专门用于存储和检索向量数据(embedding)的数据库系统。它主要关注的是向量数据的特性和相似性。在向量数据库中,数据被表示为向量形式,每个向量代表一个数据项。这些向量可以是数字、文本、图像或其他类型的数据。向量数据库使用高效的索引和查询算法来加速向量数据的存储和检索过程。Langchain 集成了超过 30 个不同的向量存储
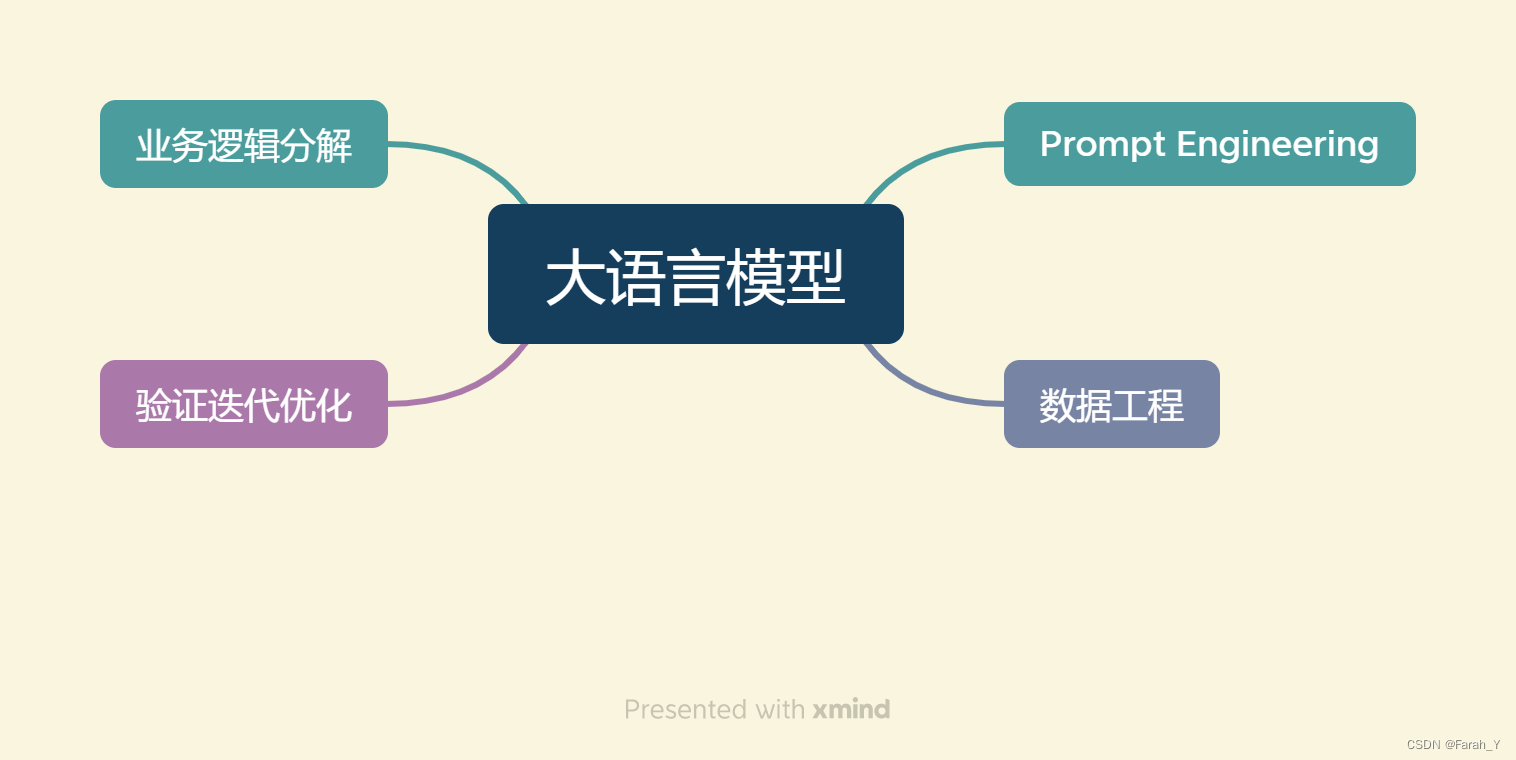
开发以大语言模型为功能核心、通过大语言模型的强大理解能力和生成能力、结合特殊的数据或业务逻辑来提供独特功能的应用称为。开发大模型相关应用,不需要实现大语言模型,而是通过调用API或开源模型来实现核心的理解与生成,通过prompt Enginnering来实现大语言模型的控制。将大模型作为一个调用工具,通过 Prompt Engineering、数据工程、业务逻辑分解等手段来充分发挥大模型能力。大语
最初是NLP研究中为下游任务设计出来的一种任务专属的输入模板,类似于一种任务对应一种prompt。在ChatGPT推出并获得大量应用之后,开始被推广为给大模型的所有输入。即,每一次访问大模型的输入为一个Prompt,而大模型给我们的返回结果为Completion。