




- @DataSourceAI
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
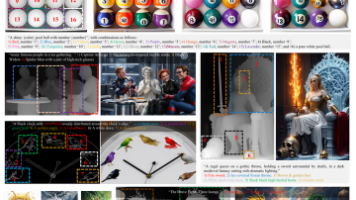
图像条件生成方法,如深度和Canny条件方法,已在精确图像合成方面展现出卓越能力。然而,现有模型仍难以准确控制多个实例(或区域)的内容。即使是像FLUX和3DIS这样的先进模型也面临挑战,例如实例之间的属性泄漏,这限制了用户的控制能力。为解决这些问题,我们引入了DreamRenderer,这是一种基于FLUX模型的无训练方法。DreamRenderer使用户能够通过边界框或掩码控制每个实例的内容,
弥合不同模态之间的差距是跨模态生成的核心。传统方法将文本模态视为一种条件信号,逐步引导从高斯噪声到目标图像模态的去噪过程,而我们探索了一种更简单的范式——通过流匹配在文本和图像模态之间直接转换。这需要将两种模态投影到一个共享的潜在空间中,但由于它们本质上的不同表示方式,这带来了重大挑战:文本具有高度语义性,被编码为一维标记,而图像在空间上存在冗余,以二维潜在嵌入的形式表示。

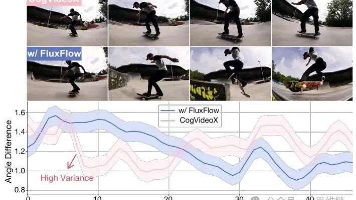
追求逼真的视频生成面临着一个关键困境:虽然空间合成(例如,StableDiffusion系列、基于自回归(AR)的方法)已经实现了显著的保真度,但确保时间质量仍然是一个难以实现的目标。现代视频生成器,无论是扩散模型还是自回归模型,经常生成存在时间伪影的序列,例如闪烁的纹理、不连续的运动轨迹或重复的动态,这暴露了它们无法稳健地建模时间关系的问题(见图1)。图2. 使用VBench指标对VideoCr
我们提出了UniFluid,这是一个统一的自回归框架,用于利用连续视觉标记进行联合视觉生成和理解。我们的统一自回归架构处理多模态图像和文本输入,为文本生成离散标记,为图像生成连续标记。我们发现,虽然图像生成和理解任务之间存在内在的权衡,但经过精心调整的训练方案可以使它们相互促进。通过选择合适的损失平衡权重,统一模型在这两个任务上取得的结果与单任务基线相当或更优。此外,我们证明了在训练过程中采用更强

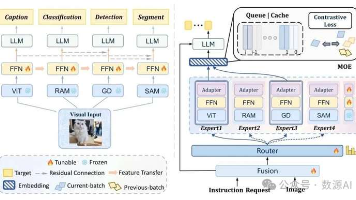
基于专家混合(Mixture-of-Experts,MoE)架构的视觉语言模型(Vision-Language Models,VLMs)已成为多模态理解领域的关键范式,为整合视觉和语言信息提供了强大的框架。然而,任务的复杂性和多样性不断增加,在协调异构视觉专家之间的负载平衡方面带来了重大挑战,因为优化一个专家的性能往往会损害其他专家的能力。为了解决任务异构性和专家负载不平衡的问题,我们提出了阿斯特
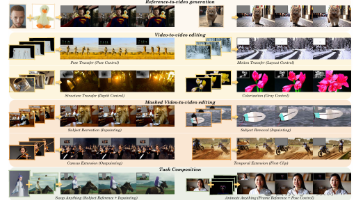
扩散变换器(Diffusion Transformer)在生成高质量图像和视频方面展现出了强大的能力和可扩展性。进一步追求生成和编辑任务的统一,在图像内容创作领域取得了显著进展。然而,由于对时间和空间动态一致性的内在要求,实现视频合成的统一方法仍然具有挑战性。我们推出了VACE,它使用户能够在一个集创作与编辑功能于一体的框架内执行视频任务。这些任务包括参考到视频生成、视频到视频编辑以及掩码视频到视
尽管音频驱动视频生成技术最近取得了进展,但现有方法大多专注于驱动面部动作,导致头部和身体动态不协调。进一步而言,生成与给定音频精确唇形同步且具有细腻伴随语音手势的整体人体视频是理想的,但也具有挑战性。在这项工作中,我们提出了AudCast,这是一个采用级联扩散变压器(DiTs)范式的通用音频驱动人体视频生成框架,它基于参考图像和给定音频合成整体人体视频。1) 首先,我们提出了一种基于音频条件的整体

当前的视频生成基础模型主要专注于文本到视频的任务,对细粒度视频内容创作的控制能力有限。尽管基于适配器的方法(如ControlNet)能够通过最少的微调实现额外的控制,但在整合多个条件时会遇到挑战,包括:独立训练的适配器之间的分支冲突、导致计算成本增加的参数冗余,以及与全量微调相比表现欠佳。为应对这些挑战,我们引入了FullDiT,这是一个用于视频生成的统一基础模型,它通过统一的全注意力机制无缝整合

基于专家混合(Mixture-of-Experts,MoE)架构的视觉语言模型(Vision-Language Models,VLMs)已成为多模态理解领域的关键范式,为整合视觉和语言信息提供了强大的框架。然而,任务的复杂性和多样性不断增加,在协调异构视觉专家之间的负载平衡方面带来了重大挑战,因为优化一个专家的性能往往会损害其他专家的能力。为了解决任务异构性和专家负载不平衡的问题,我们提出了阿斯特
流式运动生成旨在逐步合成人体运动,同时动态适应在线文本输入并保持语义连贯性。以流式方式生成逼真且多样的人体运动对于各种实时应用(如视频游戏、动画和机器人技术)至关重要。流式运动生成由于两个基本要求而面临重大挑战。首先,该框架必须在保持在线响应的同时逐步处理顺序到达的文本输入。其次,模型应能够通过有效地将历史信息与传入的文本条件相结合,连续合成表现出上下文一致性的运动序列,确保渐进式文本语义与跨长时
