




- @Cayyyy
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
GitHub 仓库:https://github.com/AstrBotDevs/AstrBotAstrBot 是一个专为 AI 大模型设计的开源聊天机器人框架,它让你可以轻松地把ChatGPT、DeepSeek、Claude 等 AI接入到 QQ、企业微信、Discord 等各种聊天平台。🤖原生支持主流 AI 模型:DeepSeek、OpenAI、Claude、GLM、通义千问等开箱即用🔌丰
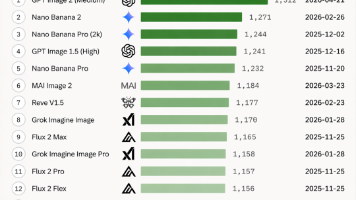
AI绘图新标杆GPT-image-2正式发布,彻底解决了中文文案生成扭曲的行业难题,超越Nano Banana 2成为新一代SOTA模型。该模型通过浏览器插件DeepSider提供免费使用,支持快速生成逼真的直播间截图、电商海报、科研绘图等各类场景内容,细节处理媲美专业设计。其强大的世界知识库支持复杂构图逻辑,从手稿到皮克斯风格都能精准还原,现已广泛应用于各行业工作流。用户无需专业背景,通过简单文
本文介绍了如何利用魔珐星云SDK和Claude Code快速开发交互型AI家电导购数字人产品。该方案解决了传统数字人部署成本高、交互延迟等问题,具备500ms实时响应、递进式追问、多终端适配等优势。文章详细演示了从注册账号、环境配置到代码生成的完整流程,10分钟即可打造具备真人导购逻辑的MVP产品。该方案支持家电选购、售后服务等多种场景,为创业者提供了低门槛、高商业价值的AI数字人解决方案。
本文介绍了如何利用魔珐星云(Embodia AI)的端渲染与端侧解算技术,为国产大模型(如DeepSeek、Qwen)构建具象化数字人交互方案。传统数字人方案存在延迟高、音画不同步、成本高昂等问题,而魔珐星云通过参数流架构,将3D渲染与动作解算迁移至本地设备,仅需传输轻量化控制参数,实现毫秒级响应。文章结合Demo展示了该技术在潮玩风格"小悟空"数字人中的应用,通过端到端集成,显著提升了交互自然度
本文介绍了如何利用魔珐星云(Embodia AI)的端渲染与端侧解算技术,为国产大模型(如DeepSeek、Qwen)构建具象化数字人交互方案。传统数字人方案存在延迟高、音画不同步、成本高昂等问题,而魔珐星云通过参数流架构,将3D渲染与动作解算迁移至本地设备,仅需传输轻量化控制参数,实现毫秒级响应。文章结合Demo展示了该技术在潮玩风格"小悟空"数字人中的应用,通过端到端集成,显著提升了交互自然度
本文介绍了如何利用魔珐星云(Embodia AI)的端渲染与端侧解算技术,为国产大模型(如DeepSeek、Qwen)构建具象化数字人交互方案。传统数字人方案存在延迟高、音画不同步、成本高昂等问题,而魔珐星云通过参数流架构,将3D渲染与动作解算迁移至本地设备,仅需传输轻量化控制参数,实现毫秒级响应。文章结合Demo展示了该技术在潮玩风格"小悟空"数字人中的应用,通过端到端集成,显著提升了交互自然度
商汤科技推出的SenseNova U1多模态大模型实现了原生图文交错生成能力的突破性进展。该模型采用NEO-unify端到端架构,彻底解决了传统AI生成中文乱码的痛点,支持高密度中文排版和商业级图文设计。测试显示,U1在三大场景表现优异:1)结构化数据与高密度图表双向无损互转,实现印刷级清晰度;2)基于物理规律的深度图像编辑,材质替换后仍保持自然光影效果;3)长上下文多模态编排,可生成连贯的图文故

商汤科技推出的SenseNova U1多模态大模型实现了原生图文交错生成能力的突破性进展。该模型采用NEO-unify端到端架构,彻底解决了传统AI生成中文乱码的痛点,支持高密度中文排版和商业级图文设计。测试显示,U1在三大场景表现优异:1)结构化数据与高密度图表双向无损互转,实现印刷级清晰度;2)基于物理规律的深度图像编辑,材质替换后仍保持自然光影效果;3)长上下文多模态编排,可生成连贯的图文故
本文介绍了如何利用魔珐星云SDK和Claude Code快速开发交互型AI家电导购数字人产品。该方案解决了传统数字人部署成本高、交互延迟等问题,具备500ms实时响应、递进式追问、多终端适配等优势。文章详细演示了从注册账号、环境配置到代码生成的完整流程,10分钟即可打造具备真人导购逻辑的MVP产品。该方案支持家电选购、售后服务等多种场景,为创业者提供了低门槛、高商业价值的AI数字人解决方案。
文章摘要 本文探讨了AR眼镜在饮食健康管理中的应用潜力。随着大健康意识觉醒,传统手机App记录饮食存在高交互摩擦力、认知偏差和高放弃率等问题。Rokid灵珠AR眼镜作为"数字化假体",通过第一视角感知、抬头显示和双手解放等特性,结合多模态大模型技术,为解决这些问题提供了新方案。文章详细介绍了"热量猎手"智能体的开发过程,包括深度集成的硬件生态、多模态大模型底
