




- @Bug_makerACE
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文会从基础概念→基础原语→核心进阶原语→大模型训练落地场景,逐层系统讲解,完全贴合新手学习的大模型分布式训练场景。
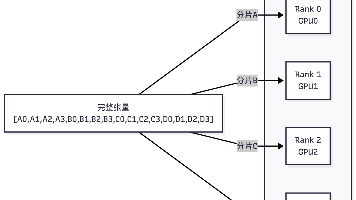
一文读懂LLaMA核心架构之分组查询注意力(Grouped Query Attention)

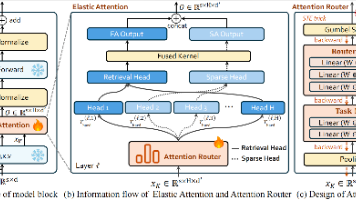
Elastic Attention 是我们在 Dynamic Sparse Attention 方向的一次尝试。通过引入 MoE 路由机制,我们打破了静态稀疏注意力的限制,证明了“动态路由”在 Attention 层同样大有可为。目前代码、模型和论文均已开源,欢迎大家 Star、引用和交流!PaperCodeModel如果你对长文本优化、MoE 架构或底层算子优化感兴趣,欢迎在评论区留言讨论!
一问读懂LLaMA核心架构之SwiGLU激活函数

大模型(LLM)学习路线总结,快速入门大模型,一起成为LLM高手!

一问搞懂LLaMA的架构之旋转编码(RoPE, Rotary Position Embedding)

摘要:大语言模型的数据类型选择直接影响训练效率与推理性能。FP32因显存占用过高逐渐被替代;FP16虽提速但易下溢,需混合精度训练;BF16凭借与FP32相同的数值范围成为当前训练主力;FP8因高效计算成为推理新宠;整数类型(INT8/INT4)适合资源受限场景。未来趋势是动态混合精度,根据模型层级的敏感度差异化选择数据类型,在精度与效率间寻找最优平衡。数据类型演变反映LLM“效率优先”的发展逻辑
含LLaMA论文地址+解读视频+源码地址分享!

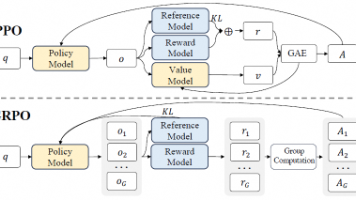
本文围绕 LLM 训练的 PPO、DPO、GRPO 三种算法展开,以 PO 统一视角解析核心逻辑,对比各算法组件、显存压力等差异。
一文读懂LLaMA核心架构之均方根误差标准化RMSNorm(含代码实现)
