




- @BigerBang
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
configure要添加下面两个选项。
介绍pytorch模型的保存和加载,包括预训练模型和新定义的模型参数不完全一一对应的情况

开源项目Enhance Agent是一个智能图像处理系统,通过自然语言指令实现图像编辑操作。系统采用多智能体协作架构,能够理解用户的自然语言指令,自动执行相应的图像处理任务。

利用pytorch中的钩子(hook),我们不用改变输入输出中间的网络结构,可以方便的获取、改变网络中间层变量的值和梯度。本篇文章记录了如何利用register_forward_hook(hook)获取pre-trained模型任意层的输出特征图并保存。register_forward_hook(hook)说明Registers a forward hook on the module....
开源项目Enhance Agent是一个智能图像处理系统,通过自然语言指令实现图像编辑操作。系统采用多智能体协作架构,能够理解用户的自然语言指令,自动执行相应的图像处理任务。
记录平常最常用的三个python对象之间的相互转换:numpy,cupy,pytorch三者的ndarray转换
是一个特殊的文件名,用于标识一个 Python 包(package)。在 Python 中,一个包就是一个包含多个模块的文件夹,该文件夹下必须包含一个名为的文件,用于告诉 Python 这是一个包,并且可以在该包中导入其他模块。文件有以下几个常见用途:文件可以包含初始化代码,例如设置模块级别的变量或者执行某些必要的操作。这些初始化代码在导入包时会被自动执行。文件可以控制哪些模块可以被导入。例如,可

ffmpeg将视频解成图片ffmpeg -i test.mp4 -pix_fmt rgb24 %4d.png但是同样的命令,却只能得到整个视频的yuv,无法获得单帧的yuv:ffmpeg -i test.mp4 -pix_fmt yuv420p %4d.yuv后来发现可以通过segment来实现,-segment_time需设置为小于1/fps的数:ffmpeg -i test.mp4 -f se
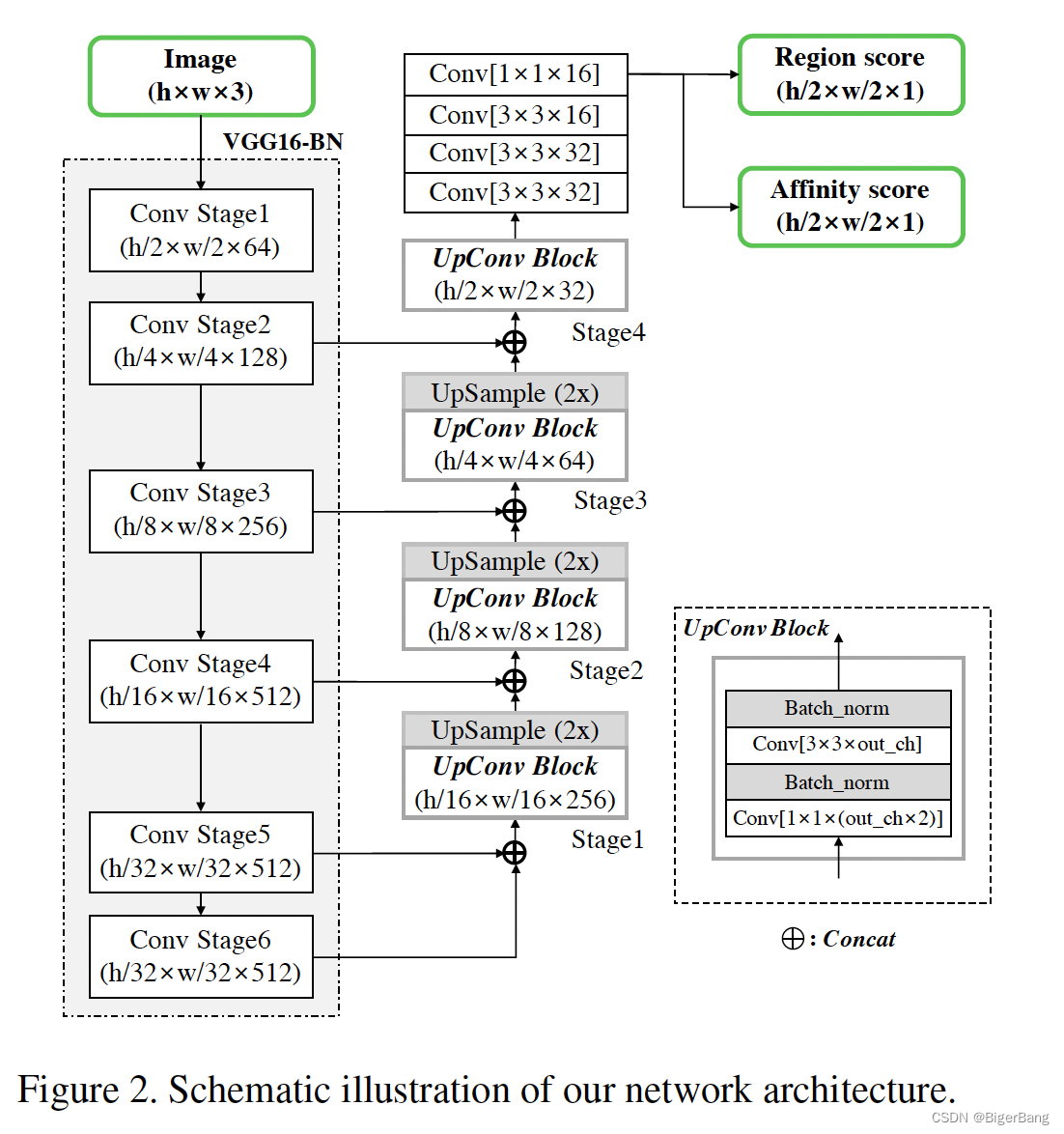
本文讲解了CVPR 2019的一篇文字检测算法《Character Region Awareness for Text Detection》的原理,并给出我使用**C++和TensorRT**重新实现的推理,速度比原版代码快12倍。
记录平常最常用的三个python对象之间的相互转换:numpy,cupy,pytorch三者的ndarray转换