




- @Antai_ZHU
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
原文链接:Pytorch库的基本架构介绍很多同学说每次使用PyTorch时都需要导入很多模块,非常混乱,今天我就将PyTorch常用的模块做一个总结梳理。首先要说明的是PyTorch这是torch的Python版本,所以导入的是torch而不是Pytorch:import torch1 运行基础torch.tensor:基础数据结构torch.autograd:自动微分模块2 torch.util

你知道y=kx+b,你就知道了为什么神经网络可以(理论上)拟合任何函数。

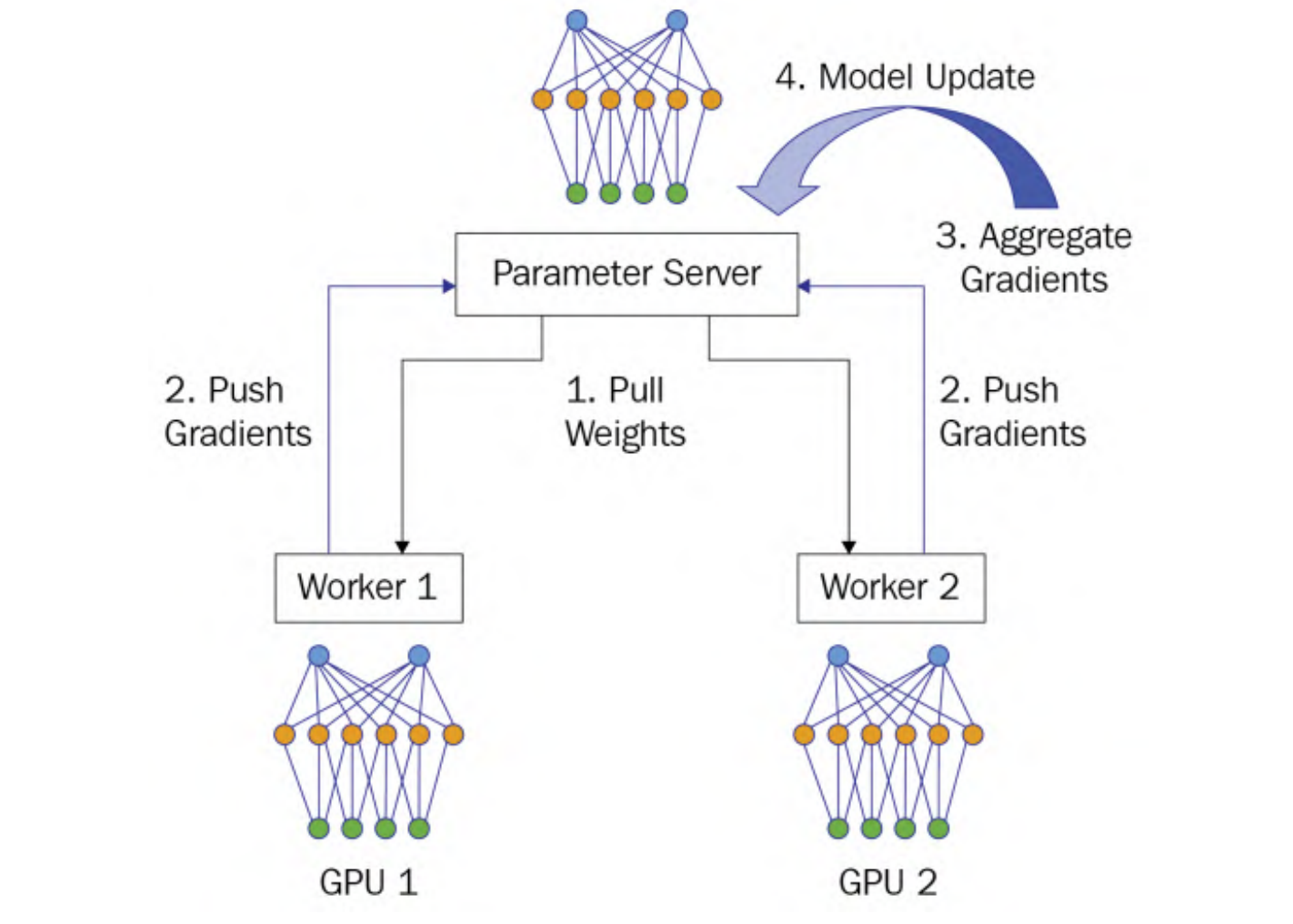
在DP中,每个GPU上都拷贝一份完整的模型,每个GPU上处理batch的一部分数据,所有GPU算出来的梯度传到master进行累加后,再传回各GPU用于更新参数DDP通过定义网络环拓扑的方式,将通讯压力均衡地分到每个GPU上,使得跨机器的数据并行(DDP)得以高效实现DP和DDP的总通讯量相同,但因负载不均的原因,DP需要耗费更多的时间搬运数据最后请大家记住Ring-AllReduce的方法,因为
AI因你而升温,记得加星标哦!大家好,我是泰哥。最近《人工智能训练师国家职业技能标准》(文末复制链接下载)发布后被刷屏,我就网上热门观点与大家分享,同时谈谈我个人的看法。原文链接:新发布的《人工智能训练师国家职业技能标准》该如何解读?01 作者:桔了个仔你属于什么级别《人工智能训练师技能标准》一共18页,大家可以直接跳到最后两页,它把把人工智能训练师分为了五级,大家可以看看自己所拥有的技能属于哪级

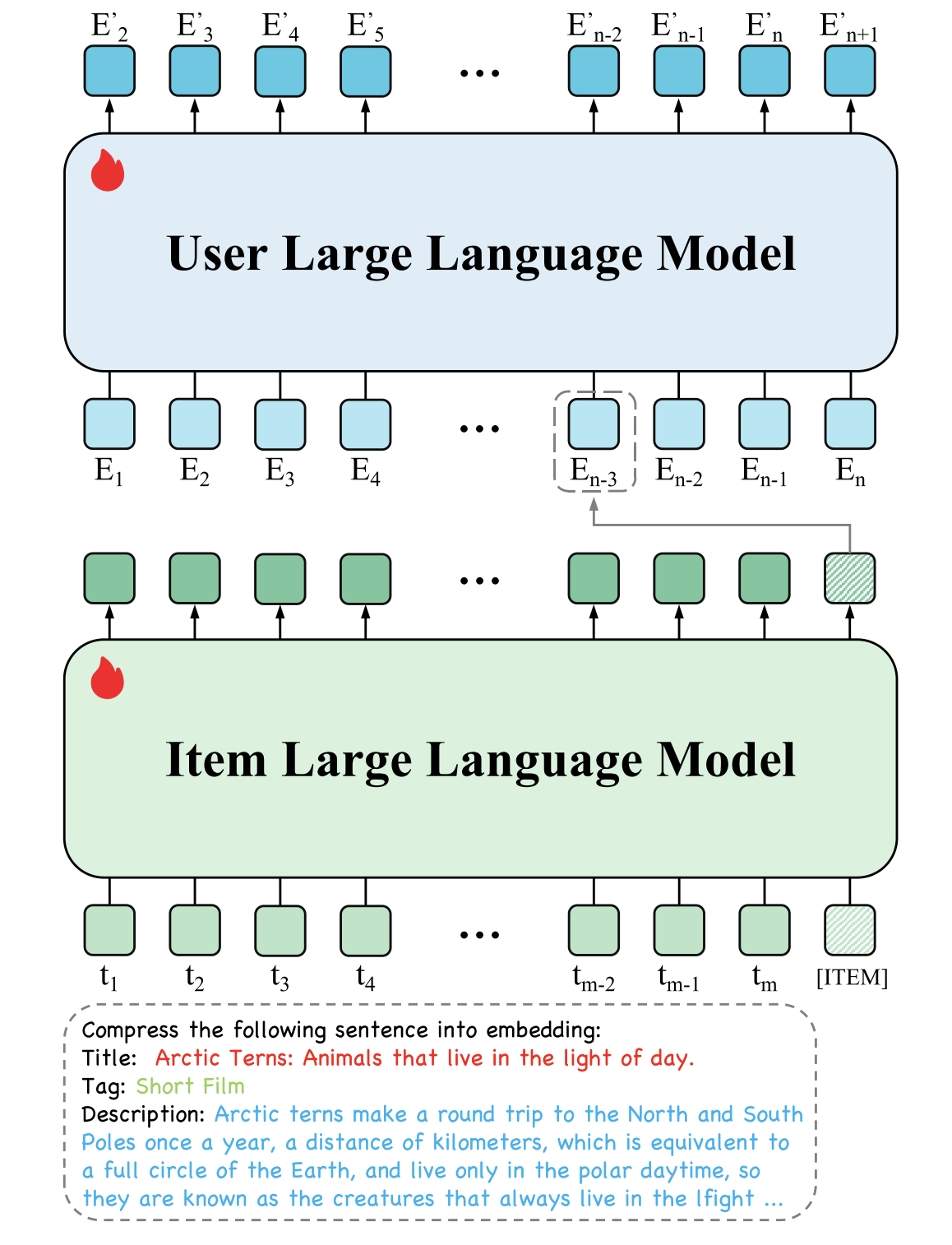
字节前几天2024年9年19日公开发布的论文《HLLM:通过分层大型语言模型增强基于物品和用户模型的序列推荐效果》。文字、图片、音频、视频这四大类信息载体,在生产端都已被AI生成赋能助力,再往前一步,一定需要一个更强势的、更有效率的推荐分发机制。因为只有分发到位,才会激发更多的供给生产…
AI因你而升温,记得加个星标哦!:直接选择概率最高的单词。这种方法简单高效,但是可能会导致生成的文本过于单调和重复。:是对贪心策略一个改进。思路也很简单,就是稍微放宽一些考察的范围。在每一个时间步,不再只保留当前分数最高的1个输出,而是保留num_beams个。当num_beams=1时集束搜索就退化成了贪心搜索。:按照概率分布随机选择一个单词。这种方法可以增加生成的多样性,但是可能会导致生成的文

GPipe需要等所有的microbatch前向传播完成后,才会开始反向传播。PipeDream则是当一个microbatch的前向传播完成后,立即进入反向传播阶段。理论上,反向传播完成后就可以丢弃掉对应microbatch缓存的激活。由于PipeDream的反向传播完成的要比GPipe早,因此也会减少显存的需求。GPipe与PipeDream主要差别是在梯度更新上,Gpipe是最后同步一次更新的,

原文链接:为什么线代在人工智能中被广泛应用?大家好,我是泰哥。在机器学习建模过程中,经常会使用矩阵运算以提升效率,在深度学习中,往往会涉及矩阵的集合运算,就是三维或四维数据的计算。它们的基础就是线性代数理论,而线代基础的核心又是矩阵,矩阵的本质其实是线性方程!是不是很神奇?本文首先介绍矩阵的构造,然后详解矩阵的运算与本质意义。一、矩阵形变的构造矩阵的形变与构造的方法与二维张量的方法相同。# 创建一
AI因你而升温,记得加星标哦!大家好,我是泰哥。本文可谓是千呼万唤使出来,很多同学问我,AI方向的知识多而杂,哪些该重点学习?学习路径又是怎么样的呢?今天,我将自己的学习路径及我所参考的资料全部免费分享出来,愿大家的AI学习进阶之路上多一些“温度”。学习途径在我学习人工智能的过程中,主要有以下两个途径:首先是B站。我将所有知识点所推荐的视频链接直接贴设为了超链接,点击可直达教程。第二是书籍。视频的

AI因你而升温,记得加星标哦!大家好,我是泰哥。最近《人工智能训练师国家职业技能标准》(文末复制链接下载)发布后被刷屏,我就网上热门观点与大家分享,同时谈谈我个人的看法。原文链接:新发布的《人工智能训练师国家职业技能标准》该如何解读?01 作者:桔了个仔你属于什么级别《人工智能训练师技能标准》一共18页,大家可以直接跳到最后两页,它把把人工智能训练师分为了五级,大家可以看看自己所拥有的技能属于哪级