




- @AnameJL
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
安装达梦数据库准备工作软件准备达梦iso镜像DM8-ARM版,提取码d821检查GLIB版本[root@t01 ~]# strings /usr/lib64/libstdc++.so.6|grep GLIBCXXGLIBCXX_3.4GLIBCXX_3.4.1GLIBCXX_3.4.2GLIBCXX_3.4.3GLIBCXX_3.4.4GLIBCXX_3.4.5GLIBCXX_3.4.6GLIBC
Ketlle提供了hadoop集群的连接配置模块,在配置“Hadoop cluster”之前要做一些准备工作,将集群中的相关配置文件复制到kettle中的目录中,替换掉原目录中的文件。 1. 需要的配置文件:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、hbase-site.xml、hive-site.xml,这些配置文件
在本地调试运行spark程序时,报错Exception in thread “main” java.lang.NoClassDefFoundError: org/apache/spark/SparkConf,这个错误就是程序在运行时找不到类Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/Spar
sqoop数据导入
恢复注册表 如果我们不小心将注册表中的exe删除后,这个时候不管打开什么软件都需我们自己进行指定才能打开使用,这样是及其麻烦的,而且在删除掉.exe之后,原来能在“运行”中搜索的执行文件也都无法执行了,比如果原来我们能直接在运行中执行"regedit"命令就可以进入注册表,但是删除掉exe之后通过这种方式是无法进入的,或者是通过C:\Windows\regedit.exe,或者是通过C:\Win
order by的使用及讲解1. order by的使用大家都清楚在hive中order by是用来排序的,使用语法如下SELECT * FROM tab_name ORDER BY column_name;在使用order by的时候默认是按照升序进行排序的(ASC),字符串类型就是按照字典顺序进行排序的,数值类型就是按照数值的大小进行排序的具体列子如下:表中数据:goodsgtypeprice
KETTLE中的值映射的使用用法一:生成新的一列,并且根据自己的需求,将对应值进行更改在整个转换流程中添加一个”值映射”双击”值映射”,在”值映射”配置窗口中进行配置进行参数配置,配置讲解如下:”使用字段选择”:选择好自己需要更改值的字段名(color);”目标字段名”:就是所要生成新的一列的字段名(new_color);“不匹配时的默认值”:就是所选择的”使用字段名”的列中的值在没有匹配到的时候
DolphinScheduler调度工具安装部署
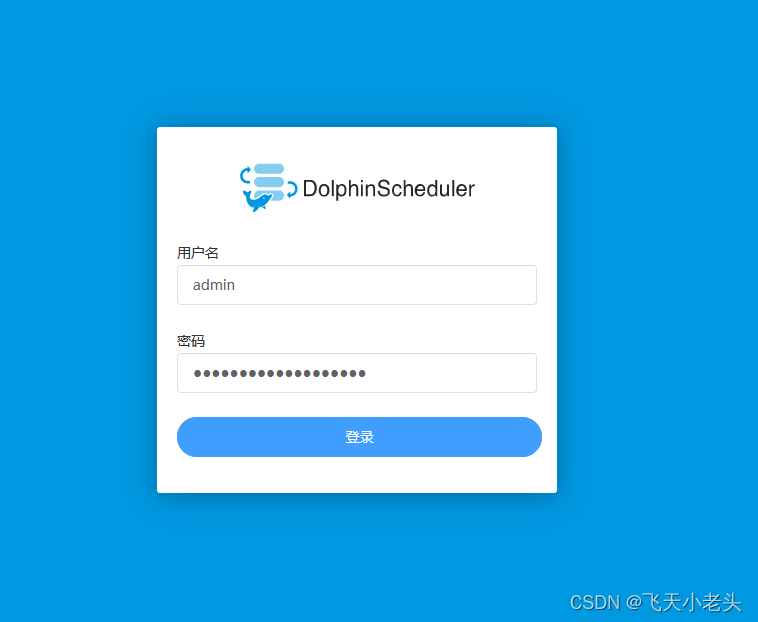
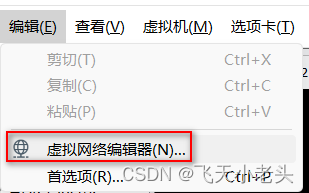
想使用电脑A连接电脑B中的虚拟机有两种方式(这里说的都是windows环境,并且都在A和B在同一网络环境下)后面就一直点击下一步,最后起个名字就可以了,这里就不截图了,到这里就可以了.7. 选择桥接模式的网卡(因为我这里连接的WIFI)9. 更改虚拟的IP地址,保证和主机统一网关和网段。不知道选什么网卡可以在windows中看。到这里就完成了,可以尝试一下其他终端能否。8. 将虚拟机更改为桥接模式
在linux系统中,有些时候会发现内存资源或磁盘资源紧张,但是通过产看内存使用或磁盘使用的命令又没有办法找到问题所在,这个时候就可以通过lsof -n | grep delete命令查看,有哪些文件已经被删除掉,但是进程还在占用空间,我遇到的情况就是linux根目录下磁盘空间一直处于饱和状态,该节点的内存使用情况也是一直飘红,在该节点部署java项目时,一直报该节点磁盘空间不足的问题。通过ls