




- @2502_94138550
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
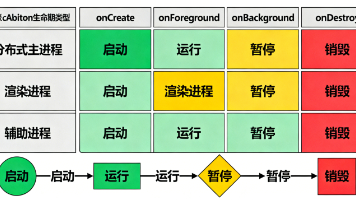
本文探讨了Electron框架在鸿蒙PC终端的适配技术,分析了传统Electron架构与鸿蒙PCElectron适配层的核心差异。传统Electron依赖Chromium和Node.js,而鸿蒙适配层将其替换为方舟渲染引擎和运行时,优化了PC端性能和资源占用。文章详细拆解了调用链路,并通过文件查看器案例展示了开发实践。鸿蒙PCElectron保留了传统API接口,同时新增了PC特有功能,支持多端部

本文深入探讨了Electron框架在鸿蒙PC系统上的渲染优化方案。针对Electron原生渲染引擎与鸿蒙分布式图形子系统的核心冲突,提出了三大优化策略:1)重构渲染管线对接鸿蒙GPU加速通道;2)基于分布式内存池优化图形资源管理;3)智能帧率调控提升渲染稳定性。通过虚拟列表、纹理压缩、多窗口协同等关键技术,显著提升了鸿蒙PC端的渲染性能,使长列表滚动帧率从27fps提升至59fps,内存占用降低5
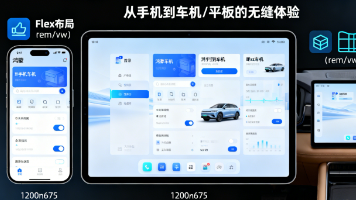
本文探讨了鸿蒙(HarmonyOS)生态下Electron应用的跨设备适配方案。针对手机、平板、车机等不同设备的屏幕尺寸、交互方式和分辨率差异,提出了一套完整的适配策略。核心内容包括:1)采用弹性布局和相对单位实现基础适配;2)通过鸿蒙API和Electron模块获取设备信息;3)针对不同设备特性进行个性化优化;4)提供问题排查方法和调试工具。文章结合代码示例,详细展示了从布局调整到交互适配的完整
鸿蒙Electron是华为针对鸿蒙PC生态推出的跨平台开发方案,基于Electron v34深度改造,让Web开发者能零成本迁移到鸿蒙生态。与标准Electron不同,它去除了Node.js运行时,适配鸿蒙系统API和安全机制,支持鸿蒙应用签名、权限管控等特性。开发者可利用现有Web技术栈快速开发鸿蒙PC应用,并实现跨平台兼容。本文详细介绍了环境搭建步骤、核心功能开发技巧,以及鸿蒙Electron

本文针对鸿蒙Electron开发中的核心痛点,提供了一套完整的进阶解决方案。文章首先详细介绍了如何通过CSS主题配置和组件开发实现原生鸿蒙UI风格,包括系统字体、颜色体系和控件交互。随后深入讲解了Vue3+Vite框架的集成方法与常见兼容性问题处理。在性能优化部分,提供了首屏加载、资源压缩和骨架屏等实战技巧。最后,系统梳理了应用上架流程,包括签名配置、HAP打包和审核要点。全文包含70%的实用代码

本文系统讲解鸿蒙Flutter环境下BLE开发全流程,涵盖环境搭建、设备扫描、连接管理、数据交互等核心功能。重点介绍了Flutter_blue_plus插件的使用,包括设备扫描过滤、GATT服务发现、特征值读写、通知订阅等关键技术实现。同时提供多设备管理、快速重连、低功耗优化等进阶方案,并给出常见问题排查指南。通过完整代码示例展示智能设备控制、温度监测等典型应用场景,为开发者提供HarmonyOS

本文系统讲解鸿蒙Flutter环境下BLE开发全流程,涵盖环境搭建、设备扫描、连接管理、数据交互等核心功能。重点介绍了Flutter_blue_plus插件的使用,包括设备扫描过滤、GATT服务发现、特征值读写、通知订阅等关键技术实现。同时提供多设备管理、快速重连、低功耗优化等进阶方案,并给出常见问题排查指南。通过完整代码示例展示智能设备控制、温度监测等典型应用场景,为开发者提供HarmonyOS
AOE(Auto Optimization Engine)是一种自动优化引擎,专注于搜索深度学习算子的最优执行参数。它支持两种调优模式:遗传算法(GA)模式适合深度优化(30-60分钟),强化学习(RL)模式适合快速迭代(5-15分钟)。AOE可优化tiling参数、循环展开、内存布局等实现细节,但不改变模型数学逻辑。实践表明,在ResNet50等模型上可获得35%的延迟提升。使用时需注意输入sh

本文介绍了GE(Graph Engine)在NPU计算图优化中的关键技术。主要内容包括:1)计算图的表示方式,展示PyTorch模型如何转换为GE内部结构;2)常量折叠优化,将编译时可计算的表达式提前计算;3)公共子表达式消除,避免重复计算;4)算子融合技术,将多个小算子合并减少显存访问;5)内存规划策略,分析tensor生命周期实现显存复用;6)算子调度机制,根据场景选择最优实现。这些优化技术能

本文介绍了昇腾HCCL分布式通信库的核心功能和使用方法。主要内容包括: HCCL初始化配置,支持多机多卡训练环境搭建 AllReduce操作实现全局梯度求和与同步 AllGather用于收集各卡数据并进行拼接 ReduceScatter实现数据分发 Broadcast同步模型权重 点对点通信支持Pipeline并行 文中提供了完整的代码示例,涵盖梯度同步、分布式矩阵计算、模型权重同步等典型场景,并
