- @2501_93059031
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了一个基于"3+1+2"架构的中医药知识系统,包含网站端、大屏端和管理端三前端,统一后端服务,以及Neo4j图数据库和MySQL关系型数据库。系统核心功能包括中医药知识图谱构建、个性化推荐算法、多条件药方查询、药材百科和可视化分析等。采用Vue3+SpringBoot技术栈,通过数据采集、清洗和知识图谱构建,实现药材-功效-病症的多维关联和智能推荐。系统特色在于交互式可
本系统采用Java语言开发,基于SpringBoot框架构建的垃圾分类管理平台。使用MySQL数据库存储数据,采用SpringBoot+Maven技术架构。系统功能完善,界面简洁,适合作为计算机专业毕业设计、Java课程设计及学习参考项目。
本项目开发了一个基于Web技术的校园二手交易平台,采用前后端分离架构。前端使用Vue.js+Element UI,后端采用Spring Boot+MyBatis Plus等技术栈,具备商品发布、搜索、推荐、交易等核心功能。系统特色包括协同过滤推荐算法、Elasticsearch全文检索等,具有模块化设计、文档齐全、部署简便等优势。适用于毕业设计、课程实践或技术学习,覆盖主流Web开发技术点,并提供
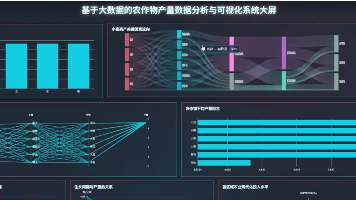
本文介绍了一个基于Python和大数据技术的农作物产量数据分析与可视化系统。系统采用Spark、Hadoop、Django、Vue和Echarts等技术框架,MySQL数据库,PyCharm开发环境。该系统针对农业生产面临的挑战,通过大数据分析和机器学习算法挖掘历史产量数据中的规律,提供五大维度的分析功能,包括地理环境、农业生产措施、作物种类、气候条件及多维模式挖掘。系统利用Hadoop存储数据,
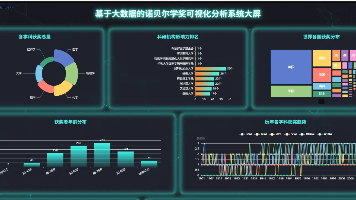
摘要:本文介绍了一个基于Python开发的诺贝尔奖可视化分析系统,整合Spark、Hadoop、Django等技术框架,对1901年以来的诺贝尔奖数据进行多维度挖掘。系统从时间演变、地理分布等4个维度构建26个分析模块,采用Vue前端和ECharts可视化组件,通过趋势图、热力图等形式直观展示数据分析结果。该项目验证了大数据技术在历史数据分析中的应用价值,为科学史研究提供数据支持,同时作为计算机专
摘要:本文介绍了一个基于Python的智能通信数据分析系统,该系统针对5G网络的海量数据处理需求,融合大数据和机器学习技术,构建了从数据采集到智能决策的完整分析链条。系统采用分布式架构处理TB级数据,运用IsolationForest、LSTM等算法实现网络异常检测(AUC 0.92)和用户行为预测(准确率85%),并通过可视化组件展示分析结果。实际应用表明,该系统可提升42%的故障预测准确率,降
本文介绍了一个基于机器学习的数学成绩预测系统,该系统通过收集和分析学生多维度学习数据(考试成绩、课堂参与度、作业完成情况等),利用特征工程和多种算法(线性回归、随机森林、XGBoost、神经网络)构建预测模型。系统提供可视化预测结果,支持教学干预、个性化学习和教育管理决策。采用Python技术栈实现,具有预测准确度高、交互友好、支持增量学习等优势。
摘要:本设计构建了一个基于深度学习的中文文本情感分析系统,采用BiLSTM+Attention架构,集成BERT等预训练模型,实现社交媒体、电商平台等场景下的情感倾向识别。系统包含数据采集、模型训练和应用三大模块,创新性地开发了中文特有词典、表情转换器和分层注意力机制。技术指标达到85%分类准确率和50ms/条的推理速度,支持舆情监控、产品分析等应用场景,具备500+并发处理能力。

本文介绍了一款基于人脸识别技术的智能考勤管理系统设计方案。系统采用前后端分离架构,后端使用SpringBoot+MyBatis框架,前端基于Vue.js开发,集成百度AI人脸识别API实现身份验证。系统包含管理员和学生两大模块,支持学生信息管理、课程管理、选课管理、人脸考勤、请假审批等功能,识别准确率达98.5%。特别适用于高校考勤、企业培训等场景,具有教育场景适配性强、隐私保护完善、模块化易扩展
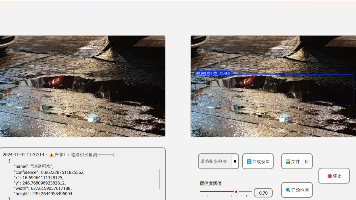
道路裂缝检测对交通安全和维护成本至关重要。数据显示,80%道路损坏始于微小裂缝,早期修复可节省30-40%成本。智能检测技术经历了人工目检、图像处理到深度学习的演进,最新YOLO算法准确率达98.2%。本数据集包含5,466张高分辨率图像,覆盖多种道路病害类型,实际应用中识别准确率92.4%,处理速度0.2秒/张。定期检测可延长路面寿命8-10年,显著降低事故风险和维护支出。