




- @2501_92856799
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
网页语音识别系统实现摘要 本文介绍了一个基于阿里云通义千问音频模型的网页语音识别系统实现方案。系统采用现代前端技术构建,包含以下核心功能: 美观的用户界面,采用渐变背景和卡片式布局 实时音频可视化功能,通过动态条形图展示声音波形 语音录制控制按钮(开始/停止录音) 与阿里云API的集成,实现语音到文本的转换 系统使用HTML、CSS和JavaScript构建,采用响应式设计和现代UI元素,包括:
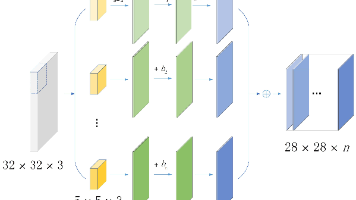
文生图模型(如Stable Diffusion)通过潜在扩散模型(LDM)架构实现了参数效率突破:1)将图像压缩到低维潜在空间(64x64x4),显著降低计算复杂度;2)采用交叉注意力机制实现文本-图像深度融合;3)结合感知损失进行多层级优化。相比万亿参数的GPT-4,文生图模型仅需8.9亿参数即可生成高质量图像,其优势源于:输入空间维度低(文本32k vs 图像64x64)、注意力机制优化及预训
2025年全球开源大模型格局发生显著转变:中国开源模型集体崛起(如MiniMax-M2、GLM4.6等),在性能、社区和应用层面取得突破;而西方开源模型(如Llama系列)活力减弱。这一变化源于中国技术的实质性进步、开发者生态的活跃及丰富应用场景的推动。同时,开源定义演变("源码可用但商用受限"新模式)和专业化小模型兴起成为新趋势。尽管开源模型进步明显,但闭源模型在性能和企业适
本文探讨了AI技术如何变革软件开发流程,重点分析了自动化代码生成、低代码开发平台和智能优化三大领域。在代码生成方面,基于Transformer架构的大模型(如Codex)能够根据自然语言描述生成功能代码,准确率超过65%。低代码平台通过可视化编程引擎和自动表单生成系统,将UI操作转换为代码抽象语法树,显著降低开发门槛。文章还展示了代码质量评估模型和智能补全系统的实现原理,通过数学公式和代码示例详细

本文介绍了一个完整的AI图片生成器项目,包含美观的前端界面和Spring Boot后端API实现。前端部分采用响应式设计,支持暗夜/明亮模式切换,提供模型选择、提示词输入、尺寸调整等参数设置功能,以及图片预览和放大查看功能。后端API负责处理图像生成请求,项目展示了如何构建一个功能完善的AI图像生成应用。
本文探讨了AI技术如何变革软件开发流程,重点分析了自动化代码生成、低代码开发平台和智能优化三大领域。在代码生成方面,基于Transformer架构的大模型(如Codex)能够根据自然语言描述生成功能代码,准确率超过65%。低代码平台通过可视化编程引擎和自动表单生成系统,将UI操作转换为代码抽象语法树,显著降低开发门槛。文章还展示了代码质量评估模型和智能补全系统的实现原理,通过数学公式和代码示例详细
2025年全球开源大模型格局发生显著转变:中国开源模型集体崛起(如MiniMax-M2、GLM4.6等),在性能、社区和应用层面取得突破;而西方开源模型(如Llama系列)活力减弱。这一变化源于中国技术的实质性进步、开发者生态的活跃及丰富应用场景的推动。同时,开源定义演变("源码可用但商用受限"新模式)和专业化小模型兴起成为新趋势。尽管开源模型进步明显,但闭源模型在性能和企业适
2025年全球开源大模型格局发生显著转变:中国开源模型集体崛起(如MiniMax-M2、GLM4.6等),在性能、社区和应用层面取得突破;而西方开源模型(如Llama系列)活力减弱。这一变化源于中国技术的实质性进步、开发者生态的活跃及丰富应用场景的推动。同时,开源定义演变("源码可用但商用受限"新模式)和专业化小模型兴起成为新趋势。尽管开源模型进步明显,但闭源模型在性能和企业适
人工智能开发正经历着前所未有的变革,从传统的特征工程和模型设计转向以数据为中心、端到端的深度学习范式。作为一名从业者,我在多年的AI开发实践中积累了大量经验教训,本文将系统性地分享从数据准备到模型部署的全流程实战经验,帮助开发者避开常见陷阱,提升开发效率。随着Transformer架构的出现,AI模型的能力边界被大幅扩展,但同时也带来了新的挑战:模型复杂度增加、计算资源需求增长、部署难度加大。本文