
写文章




- @2401_85782600
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
关于领导力的5大模型
领导”并非单纯等同于管理,发挥领导力有助于实现组织和团队的高速发展。本文将介绍关于领导力的5大模型。一起来看看吧。“领导”并非单纯地等同于“管理”。彼得·德鲁克认为:管理是把事情做好,领导力是做正确的事情。只有两者有效结合起来,才能够发挥出巨大的效用,实现组织和团队的高速发展。本文将介绍关于领导力的5大模型。

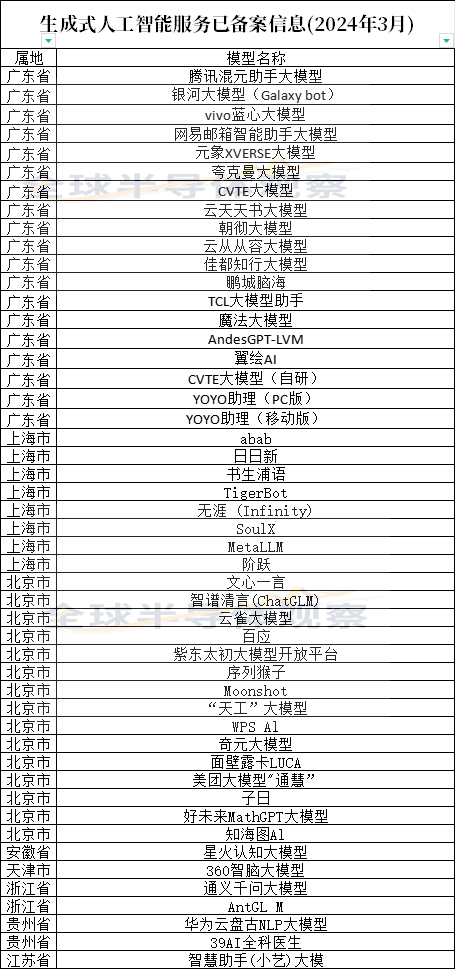
117家“大模型”成功备案,这个风口你能错过吗?
近日,国家互联网信息办公室发布《生成式人工智能服务已备案信息》的公告,显示已有117家“大模型”成功备案。此前,人民网也发布了2024中国AI大模型产业发展报告发布,对我国AI大模型面临的挑战和发展趋势进行了说明。公告显示,截止2024年3月,已经有117家“大模型”成功备案。其中北上广大模型共计94个,北京地区占据51个,上海有24个,广东19个。目前大模型备案名单并未公示,全球半导体观察根据各
关于领导力的5大模型
领导”并非单纯等同于管理,发挥领导力有助于实现组织和团队的高速发展。本文将介绍关于领导力的5大模型。一起来看看吧。“领导”并非单纯地等同于“管理”。彼得·德鲁克认为:管理是把事情做好,领导力是做正确的事情。只有两者有效结合起来,才能够发挥出巨大的效用,实现组织和团队的高速发展。本文将介绍关于领导力的5大模型。
关于领导力的5大模型
领导”并非单纯等同于管理,发挥领导力有助于实现组织和团队的高速发展。本文将介绍关于领导力的5大模型。一起来看看吧。“领导”并非单纯地等同于“管理”。彼得·德鲁克认为:管理是把事情做好,领导力是做正确的事情。只有两者有效结合起来,才能够发挥出巨大的效用,实现组织和团队的高速发展。本文将介绍关于领导力的5大模型。
到底了