- @2401_84167046
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OpenHarmony暂时还没有中文名字,名字还在申请中。

b. 在平台里应该有开发和生产两套环境;平台要支持Flink基于DAG可视化开发,不像离线分析,有阿里云DataWorks的样板可以参考。DataWorks当时在实时计算这一块也仅支持实时同步。所以这件工作刚开始完全是一个摸着石头过河,心里没底的事情,只能怀着一定有一条路的信念摸索着干下去。经过将近大半年在实际项目中的实践探索,已经找到了一条可行之路,并且已经相对成熟,正在不断完善辅助支撑功能。

北极熊是一款综合性的扫描工具,前期的信息收集我们也提到过,那里我们说它是一款爬虫工具有些片面了,也许是我经常用它来爬虫,其实它也集成了网站检测和漏洞扫描功能,只不过它得一步一步的使用,首先对目标站点进行爬虫,再将爬虫过的结果导入网站检测当中扫描,也可以根据前期信息收集情况,选择对应的选项,提高扫描效率,北极熊扫描器也可以通过网上搜索下载。网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己

人工智能在全球范围内呈爆发式发展,根据麦肯锡全球研究院的预测,AI带来的社会革命,将比工业革命的速度快10倍,规模大300倍,影响几乎大3000倍。从2012年开始,AI算力的提升速度已超过摩尔定律的预测,平均每3-4个月翻一番。这就是人工智能的美好前景!所以我们正式开始我们今天的学习内容。上次博客我们详细的讲解了,阈值分割和滤波的基本知识和相关操作。这里我们继续介绍计算机视觉中的图像形态学-本次

最全的Linux教程,Linux从入门到精通。

本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。但是仅仅是基础的开发环境是不够的,一般来讲,我们还要安装一个叫做Glut的库,这是一个OpenGL的辅助库,可以让我们创建与平台无关的OpenGL窗口。Glut有很多种实现,在这里我用的是freeglut,是我在Fedore 7的源中找到的。当然还有其他的实现。需要《Linux入门到精通》、《linux系统移

先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵

(1)设计思想将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端的来说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级,读性能低了一个数量级。本质是将写入操作全部转化成磁盘的顺序写入,极大地提高了写入

Impala是大数据进行实时交互式分析查询的一个工具,没有依赖MapReduce执行任务,而是将任务分配到各个Impala节点进行计算和汇总,从而避免了MapReduce的启动时间。直接使用内存进行结果的保存减少了读写磁盘的时间。经过以上架构设计Impala的性能比Hive高出10到100倍,非常适用于即席查询和交互式分析场景。
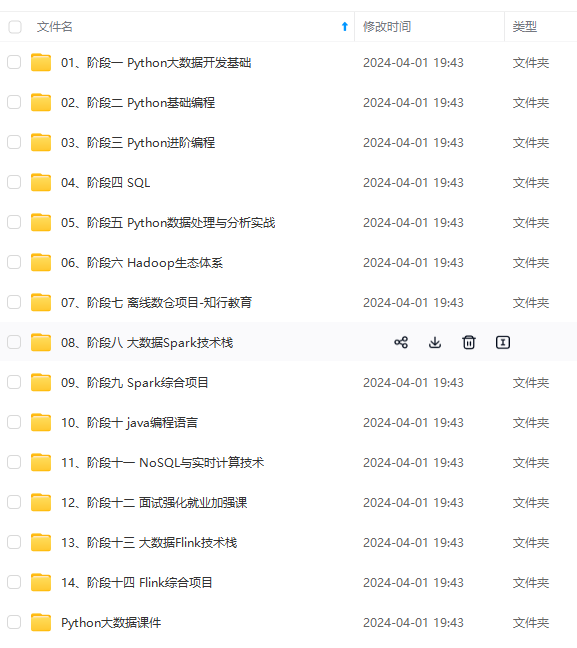
https://github.com/agherzan/meta-raspberrypi这个layer支持多个分支,我们选择一个特定的分支(kirkstone)来进行开发,最好不要用太新的分支,可能会有适配问题。最近到手一个树莓派4B,准备拿来玩一玩,下面记录下使用yocto构建RaspberryPi的镜像并刷写启动的过程。本篇文章为基于raspberrypi 4B单板的yocto实战系列的开篇之