




- @2302_80236633
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
策略是一个函数,它将状态映射到动作的概率分布。用数学符号表示为πa∣s\pi(a|s)πa∣s,其中sss表示状态,aaa表示动作,πa∣s\pi(a|s)πa∣s表示在状态sss下选择动作aaa的概率。策略决定了智能体在环境中如何行动,从而影响其获得的奖励和最终的学习效果。确定性策略(Deterministic Policy):对于每个状态sss,策略π\piπ映射到一个唯一确定的动作aaa,即
PPO(Proximal Policy Optimization,近端策略优化)算法是一种在强化学习领域广泛应用的策略优化算法。它在2017年由John Schulman等人提出,是TRPO(Trust Region Policy Optimization,信任域策略优化)算法的改进版本,旨在解决TRPO计算复杂度高、实现困难的问题,同时保持良好的性能。PPO算法在许多实际应用中表现出色,尤其是在
本文详细介绍了深度学习中的三种主要并行策略——数据并行、流水并行和张量并行。每种策略都有其独特的原理、优点、缺点和适用场景。通过对比分析,本文展示了如何结合这些策略实现混合并行,以优化大规模模型训练的效率和资源利用。
是一种用于深度学习的,是LayerNorm(层归一化)的一种改进。它通过计算输入数据的,避免了传统归一化方法中均值和方差的计算。
PPO(Proximal Policy Optimization,近端策略优化)算法是一种在强化学习领域广泛应用的策略优化算法。它在2017年由John Schulman等人提出,是TRPO(Trust Region Policy Optimization,信任域策略优化)算法的改进版本,旨在解决TRPO计算复杂度高、实现困难的问题,同时保持良好的性能。PPO算法在许多实际应用中表现出色,尤其是在
本文为人工智能考核试卷,包含基础简答题和基础公式推导题两部分。简答题涵盖矩阵运算、损失函数选择、激活函数特性、过拟合与正则化、反向传播优化、模型评估方法及医疗诊断模型评估指标(精度与召回率)的应用分析。公式推导题要求详细描述单层前馈神经网络的前向传播过程(含ReLU和Sigmoid激活函数)、交叉熵损失函数定义、反向传播梯度计算(包括权重更新公式),以及梯度下降法的实现步骤。试题全面考察了矩阵操作
困惑度是基于语言模型的概率分布计算的,它衡量的是模型对一个给定文本序列的困惑程度。具体来说,困惑度是模型对文本序列的预测概率的倒数的几何平均值。
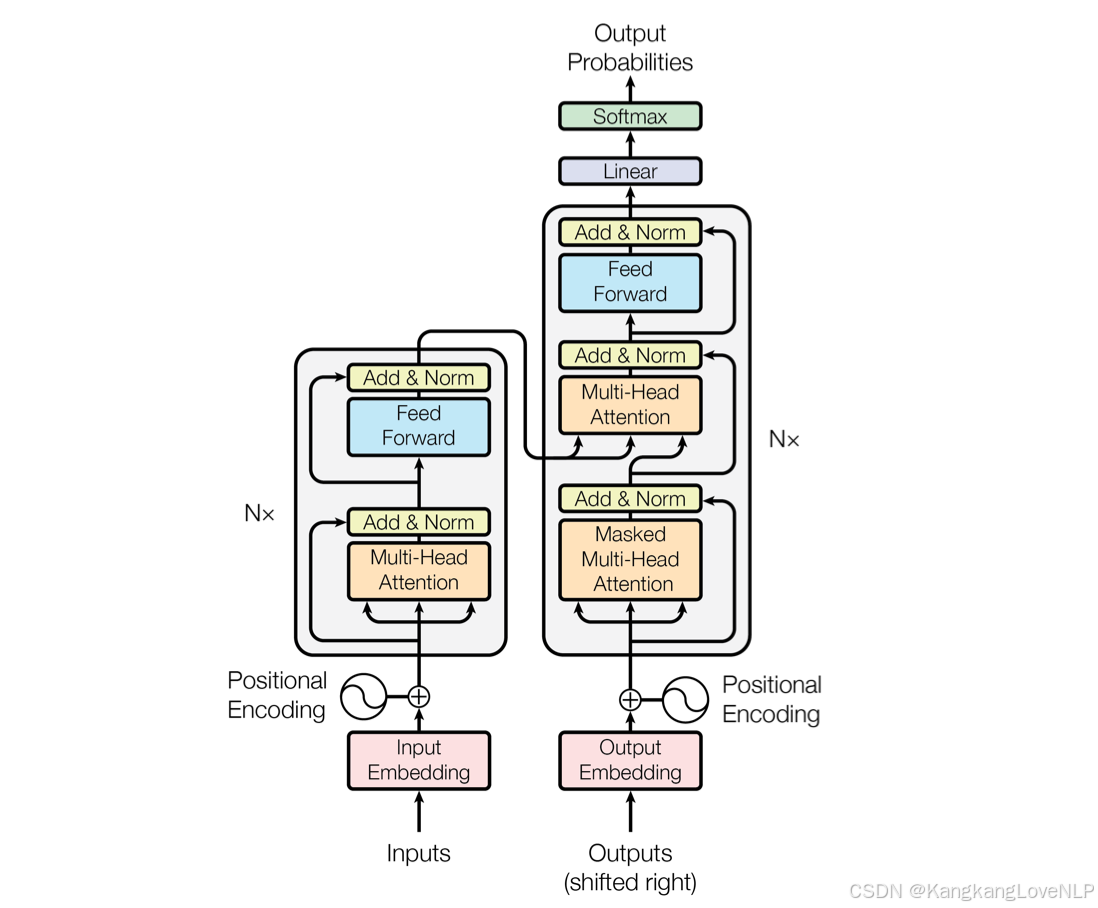
仅仅使用pytorch来手撕transformer架构(1):位置编码的类的实现和向前传播最适合小白入门的Transformer介绍仅仅使用pytorch来手撕transformer架构(2):多头注意力MultiHeadAttention类的实现和向前传播仅仅使用pytorch来手撕transformer架构(3):编码器模块和编码器类的实现和向前传播话不多说,直接上代码一. 的结构1.的结构T
一是性能差异特性架构复杂度高,包含编码器和解码器中,仅编码器中,仅解码器参数效率较低,需同时训练编码器和解码器高,专注于输入编码高,专注于输出生成生成能力强,适合序列到序列任务弱,无法直接生成文本强,适合创造性写作理解能力强,能捕捉输入输出的复杂关系强,双向编码弱,单向生成训练难度高,需要大量数据和计算资源中中二是应用场景应用场景机器翻译✔️✖️✔️文本摘要✔️✖️✔️文本分类✖️✔️✖️情感分析
是一种用于深度学习的,是LayerNorm(层归一化)的一种改进。它通过计算输入数据的,避免了传统归一化方法中均值和方差的计算。