




- @2301_79982543
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
第一章 实验背景与研究目的1.1 实验宏观背景随着信息技术的飞速发展,现代教育机构与各类商业实体一样,积累了海量的用户(学生)行为数据。这些数据不仅包括静态的人口统计学特征(如性别、生源地),更涵盖了高频的动态时间序列数据(如每日校园卡消费流水、门禁考勤打卡记录、多频次学业测评成绩)。从商业数据分析的视角来看,学校、电商平台与内容分发网络(如短视频平台)在底层逻辑上具有高度的同构性:其核心要素均可
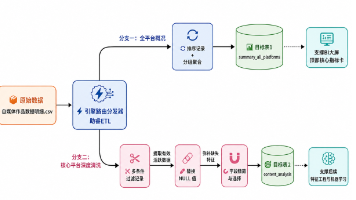
可视化分层设计逻辑先宏观大盘指标卡建立整体认知,再排名找差距,标题图表定位核心原因,趋势图补充时间维度规律,形成完整数据故事线;量化对比是 BI 核心价值不只用绝对值对比,新增 “流量提升倍率” 消除平台基础流量差距,跨平台标题效果对比更公平客观;多表数据集分工明确三张预处理数据表各司其职:汇总表做大盘、明细表做排名趋势、关键词统计表做标题效果分析,数据不重复加工;交互式看板优势图表联动筛选实现数
谁懂大数据人做完数据清洗又遇新难题!好不容易把 B 站、CSDN 作品脏数据处理干净,看着一堆纯文本标题干瞪眼,想搞清楚什么标题更容易爆、哪些关键词拉高互动,总不能手动一条条标记统计吧?这次实训直接解锁完整流水线,不用手写复杂 Python、SQL,拖拽组件就能把文字标题变成可对比的数字指标,精准扒出平台流量关键词,作业直接拿高分,运营人拿来做选题复盘也巨好用!
谁懂大数据专业实训人的崩溃!!拿到全班多平台自媒体汇总 CSV 原始数据,当场头皮发麻,一堆脏数据堆在一起,完全没法直接做可视化、算互动指标,手动整理至少耗一下午,踩坑踩麻了才摸透这套,不用写代码,拖拽组件就能一次性产出两张标准数据表,老师看了直接夸逻辑到位,干货全给你们扒明白!
看完这三套完整实战流程,相信大家已经彻底掌握零代码 ETL 抽取三大主流文件的核心玩法了!从最简单的文件读取、字段筛选,到进阶的日期计算、数据分级,整套流程贴合企业真实数据处理场景,也是数据分析师、数据开发入门的必备技能。ETL 本身并不复杂,尤其是可视化零代码平台,核心就是选对组件 + 配对参数 + 核对格式。前期多留意分隔符、编码、表头这些细节,就能避开 80% 的坑。大家可以跟着教程一步步复
在前序教程中,我们已经完成了浏览器市场分析大屏的静态布局搭建,各类柱状图、饼图、折线图、指标卡组件全部摆放就位,但此时图表仅展示模拟数据,无法对接真实业务数据库。本次实验承接静态布局成果,核心使用助睿 Max 专属蓝图编辑器,打通 MySQL 私有数据库与大屏组件的数据流,让所有图表自动加载、动态展示真实统计数据,实现从 “静态看板” 到 “实时数据大屏” 的蜕变。数据源连接失败:核对 MySQL
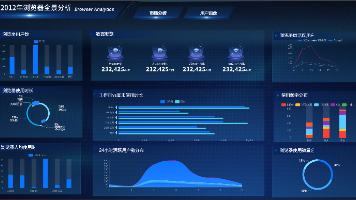
还在苦恼做数据可视化要学 Python、ECharts?小白零基础、经管 / 计算机实训、职场数据分析党看这一篇就够!本次教程依托助睿 Uniplore 助睿数智平台 + Max 数据大屏,完整复刻「2012 年浏览器全景分析大屏」,从空白画布→背景美化→标题导航→9 大业务模块逐个落地,保姆级拆分每一步点击位置、参数、图片链接、配色代码,照着操作就能做出商用级炫酷数据大屏。
本次实验基于上一轮已经完成K-Means聚类、标注好考勤群体分类的学生考勤主题标签表,摒弃笼统的全员数据分析,专项聚焦纪律高危型学生群体。通过多维度可视化探索,深度剖析该群体的违纪特征、人群分布、高发场景,精准定位校园考勤管理的薄弱环节。最终为学校开展精准德育干预、重点学生整治、班风学风优化、精细化校园管理,提供真实、客观、可视化的数据支撑,彻底解决传统管理盲目、低效、无依据的痛点。
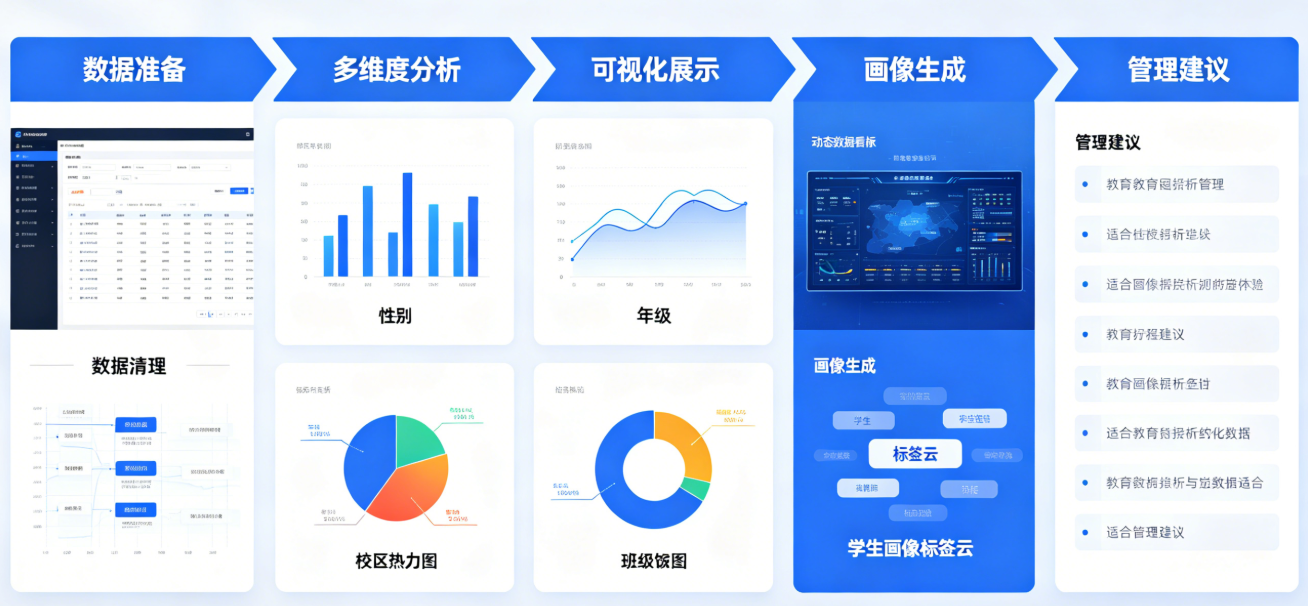
本次实验依托Uniplore助睿零代码大数据平台,完整复刻了数据预处理—AI聚类建模—可视化分析—业务画像解读—标签迭代更新的工业级数据挖掘全流程。区别于传统人工统计的主观化、低效化弊端,借助K-Means聚类算法实现了学生考勤行为的客观、智能分群,依托标准化的考勤特征数据,保障了聚类结果的稳定性、准确性和可解释性。通过BI可视化拆解,成功将抽象的算法聚类结果转化为贴合校园管理场景的三类学生画像,
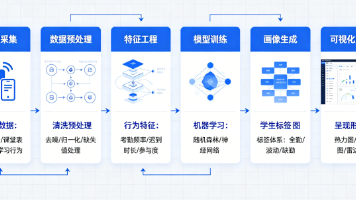
本次实验依托Uniplore助睿零代码大数据平台,完整复刻了数据预处理—AI聚类建模—可视化分析—业务画像解读—标签迭代更新的工业级数据挖掘全流程。区别于传统人工统计的主观化、低效化弊端,借助K-Means聚类算法实现了学生考勤行为的客观、智能分群,依托标准化的考勤特征数据,保障了聚类结果的稳定性、准确性和可解释性。通过BI可视化拆解,成功将抽象的算法聚类结果转化为贴合校园管理场景的三类学生画像,