




- @2301_79816842
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
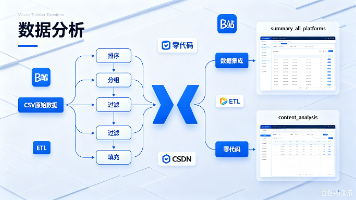
本文针对多平台自媒体运营中数据冗余、缺失及指标异构等问题,依托助睿数智(Uniplore)ETL平台构建了一套零代码数据清洗流水线。实验运用“单源输入、双路分支”架构,通过多条件过滤、空值填充与差异化聚合等操作,对周期内原始交互数据进行预处理,成功输出“全平台概况汇总”与“有效内容明细”两张标准宽表。该研究规范了异构数据融合路径,排除了低质量数据干扰,为后续大屏可视化与特征挖掘奠定了坚实基座。
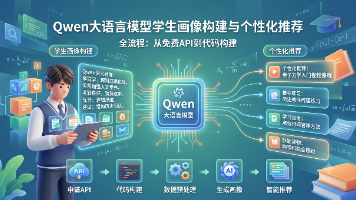
本实验针对教育大数据分析,详细展示了基于通义千问(Qwen)大模型的学生画像与推荐系统构建全流程。相比传统规则打标签存在维度孤立、区分度极低等局限,大模型能够深度整合多源异构数据,将零散的数值转化为具备推理逻辑和“教育温度”的自然语言画像,实现了从“机械贴标签”到“全息写描述”的语义跃升。在应用端,实验构建了优势互补的混合推荐引擎:利用协同过滤(CF)实现基于历史成绩的高精度提分推荐,同时结合基于
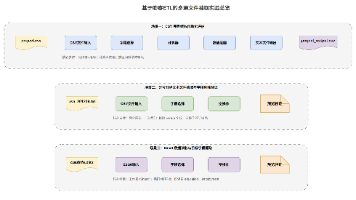
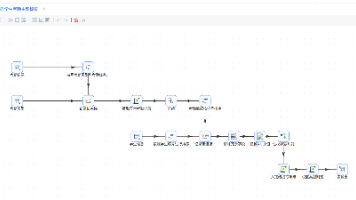
本实验基于助睿ETL一站式零代码平台,针对企业数据集成中常见的多源文件抽取难题,系统实践了CSV、分号分隔文本及Excel三类异构数据的接入与预处理。实验围绕三个典型场景展开:利用“CSV文件输入”结合计算器与数值范围组件,自动评估项目工期与绩效;通过灵活配置分隔符解析文本文件,并借助字段选择与空操作组件验证数据剔除与链路连通性;使用Excel输入组件指定工作表与编码,精准提取关键特征字段。全程无
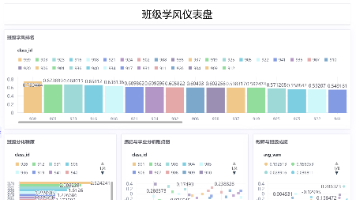
针对传统班级评价“唯分数论”的滞后性与盲区,构建了融合学业、纪律、师资稳定及学生保留等13维指标的加权评价模型。通过数据映射、Min‑Max学期标准化与加权评分,结合K‑Means生态聚类、VAM增值评价,生成班级综合学风画像。系统输出横向排名、纵向趋势及交互式诊断面板,为校长、年级组长、班主任三级决策提供精准分层预警与改进方向。
本次实验包含两个连贯的数据挖掘实验,依托助睿数智Uniplore零代码平台完成。第一部分为学生用户画像-考勤主题扩展标签构建,利用K-Means无监督聚类算法,以学生在校迟到、早退、请假、校服违规四类考勤行为数据为特征维度,对全体学生进行自动化人群分群,生成标准化学生考勤分类标签,完成原始数据表的标签扩充;第二部分为学生用户画像-考勤画像可视化分析。
本文在助睿数智(Uniplore)平台上探索更复杂的ETL场景——学生考勤画像标签构建。实验整合考勤流水、类型字典、学生信息三张表,通过9种组件类型共16个组件的编排,完成多表关联、JavaScript行为标记、分组聚合、维度衍生和标准化输出,最终生成包含年级、校区、住校状态等维度及四类行为指标的标签宽表。本教程适合有一定基础、希望进阶掌握零代码ETL的读者参考
最近在学习数据分析时,接触到了一个很有意思的概念——ETL。可能很多刚入门的同学会问:ETL到底是个啥?E(Extract,抽取):从各种数据源中把数据取出来T(Transform,转换):对数据进行清洗、计算、关联等加工处理L(Load,加载):把处理好的数据存到目标位置举个生活中的例子,就像做菜:先把菜从冰箱拿出来(Extract),然后洗菜切菜炒菜(Transform),最后装盘上桌(Loa
本研究基于某校全寄宿制高中46万余条消费记录,采用"双层筛选模型"从1,730名学生中精准识别出130名核心困难学生(占全校7.5%),并通过孤立森林交叉验证(重叠率43.08%),验证了识别结果的稳健性。从"经验判断"到"数据驱动",从"统一发放"到"分层滴灌",教育大数据正在让校园资助工作变得更精准、更有温度。本文构建的双层筛选模型和三层资助体系,仅是一个起点。我们相信,每一份助学金都应当精准