




- @2301_79696294
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
数据名称:北京大学中国商业银行数字化转型指数2010-2021年数据年份:2010-2021年样本数量:2235条数据来源:北京大学数字金融研究中心。
NPP-VIIRS夜间灯光数据(2000-2024年)提供省、市、区县及乡镇四级行政单元的夜间灯光监测指标(均值、总和、最大值、标准差),适用于城市化、能源消耗等研究领域。该数据由NASA和NOAA联合研发,包含部分网络资源和自主研发内容,禁止商用。数据下载地址已提供。
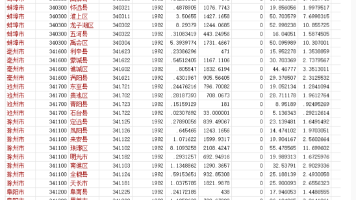
它主要指在电子商务平台上,买家和卖家之间完成的所有交易的总金额,这包括了商品的销售、服务的提供以及数字产品的交易等。因此,GMV指标并不是实际的交易数据,而是基于订单生成的一个统计值。286个地级市2011年到2022年电子商务交易额,参考黄赜琳(2022)方福前(2015)做法,利用地级市快递业务量占本省快递业务量比重做权重将省级数据分解,省级数据来源于中国统计年鉴,2011-2012数据来源于

本文介绍了一个双重机器学习Stata工具包,包含代码、案例数据和配套视频。该工具包集成了6大核心机器学习方法(LassoCV、随机森林、SVM、弹性网络、梯度提升和神经网络),可实现一键切换运行并自动导出回归结果。内容包含完整Stata代码、详细注释和教学视频,适合学术研究和实证分析。资源部分自主研发,部分来源于网络,仅供学习使用,不得商用。数据下载地址:https://download.csdn
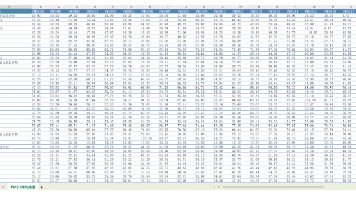
数据名称:342个地级市-PM2.5年均浓度数据数据年份:2000-2024年数据范围:342个城市数据格式:面板数据。
数据来自NCDC的公开FTP服务器ftp://ftp.ncdc.noaa.gov/pub/data/noaa/isd-lite/,本站只选取了中国区域(含港澳台)的观测站点数据,重新按年打包。本次收集到的气象资料为1942-2021全国400多个气象站气候数据,数据来自美国国家气候数据中心(NCDC),整理成EXCEL格式,以供科研工作者方便使用。时间精度:近年的数据大多为3小时数据,少量站点有1

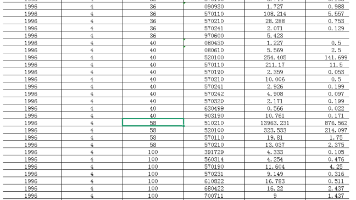
CEPII-BACI是由法国国际经济研究中心开发的全球贸易数据库,覆盖200多国5000多种产品(HS六位码分类),提供1996-2023年数据。该数据库包含贸易价值、数量等指标,支持不同HS编码版本转换分析。数据源自联合国贸易统计,含出口商/进口商流量等信息。资源部分自主研发,部分来自网络,仅供学习使用。文末提供数据下载链接。
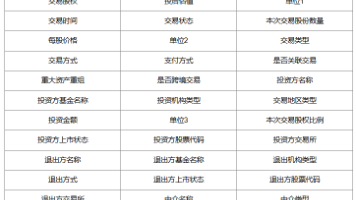
本文介绍了企业投融资事件数据库的基本情况。该数据库包含2000-2025年全国64.78万条企业投融资记录,涵盖企业名称、行业、所在地、交易金额、股权、投资方等关键指标。数据可用于分析企业资金运作、市场活跃度及行业发展趋势。文中提供了数据指标说明和样本概览截图,并强调数据部分自主研发、部分来源于网络,仅供学习使用,不得商用。文末附有数据下载链接。
摘要: 该数据为2025年更新的华证ESG评级得分数据,涵盖2009-2024年A股上市公司,包含5.48万条样本,提供ESG得分年度中位数和均值等指标。数据以Excel格式呈现,可用于学术研究,但禁止商业用途。参考文献为《经济研究》相关论文。数据部分自主研发,部分来源于网络,版权归原作者所有。下载地址已提供。

夜间灯光数据分为两种,分别为 DMSP-OLS和NPP-VIIRS,但由于常用的两种夜间灯光遥感数据(DMSP-OLS和NPP-VIIRS)存在不可比的情况,使得两套数据无法被同时使用,从而限制了夜间灯光数据的可用时间序列长度。夜间灯光数据是一种重要的遥感数据,可以为城市规划、环境监测、经济发展等多个领域提供重要的信息支持。在省级、市级、县级尺度上,夜间灯光数据可以帮助我们了解城市发展、人口分布、
