




- @2301_79601111
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
原文为:ReAct Synergizing Reasoning and Acting in Language Models 本文为大致框架梳理,欢迎交流。
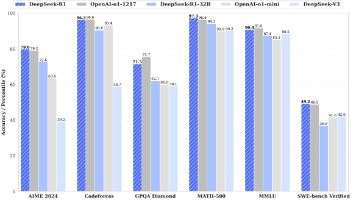
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning论文阅读,自留使用,欢迎交流
网上有些代码的例子的库已经更新了组织结构,导入的时候有点麻烦要改一下。
不足:每个 worker 必须同时存储并运行的各个 micro-batch 的激活值,导致流水线第一阶段的激活内存与单个 mirco-batch 的总激活内存大致相同。流水线并行的核心思想是:在模型并行的基础上,进一步引入数据并行的办法(将模型的各层划分为可以并行处理的阶段),即把原先的数据再划分成若干个batch,送入GPU进行训练。优势:流水线并行减少的显存与流水线的阶段数成正比,这使模型的大
训练集和测试集的用户id没有重复,也就是测试集里面的用户模型是没有见过的训练集中用户最少的点击文章数是2, 而测试集里面用户最少的点击文章数是1用户对于文章存在重复点击的情况, 但这个都存在于训练集里面同一用户的点击环境存在不唯一的情况,后面做这部分特征的时候可以采用统计特征用户点击文章的次数有很大的区分度,后面可以根据这个制作衡量用户活跃度的特征文章被用户点击的次数也有很大的区分度,后面可以根据
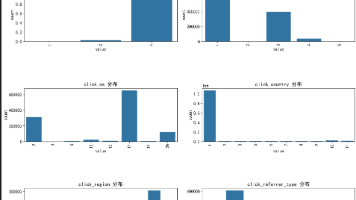
训练集和测试集的用户id没有重复,也就是测试集里面的用户模型是没有见过的训练集中用户最少的点击文章数是2, 而测试集里面用户最少的点击文章数是1用户对于文章存在重复点击的情况, 但这个都存在于训练集里面同一用户的点击环境存在不唯一的情况,后面做这部分特征的时候可以采用统计特征用户点击文章的次数有很大的区分度,后面可以根据这个制作衡量用户活跃度的特征文章被用户点击的次数也有很大的区分度,后面可以根据
不足:每个 worker 必须同时存储并运行的各个 micro-batch 的激活值,导致流水线第一阶段的激活内存与单个 mirco-batch 的总激活内存大致相同。流水线并行的核心思想是:在模型并行的基础上,进一步引入数据并行的办法(将模型的各层划分为可以并行处理的阶段),即把原先的数据再划分成若干个batch,送入GPU进行训练。优势:流水线并行减少的显存与流水线的阶段数成正比,这使模型的大
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning论文阅读,自留使用,欢迎交流
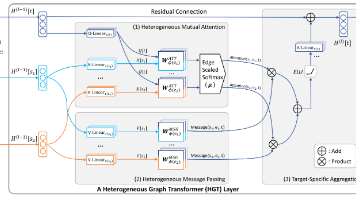
提出异构图 Transformer 模型(HGT)设计元关系感知的异构注意力机制引入相对时间编码提出 HGSampling提出归纳式时间戳分配方法。
训练集和测试集的用户id没有重复,也就是测试集里面的用户模型是没有见过的训练集中用户最少的点击文章数是2, 而测试集里面用户最少的点击文章数是1用户对于文章存在重复点击的情况, 但这个都存在于训练集里面同一用户的点击环境存在不唯一的情况,后面做这部分特征的时候可以采用统计特征用户点击文章的次数有很大的区分度,后面可以根据这个制作衡量用户活跃度的特征文章被用户点击的次数也有很大的区分度,后面可以根据