- @2301_76166241
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在单体应用中,事务管理相对简单,通过数据库的ACID特性(原子性、一致性、隔离性、持久性)来确保数据的一致性。然而,随着业务的发展,系统架构逐渐演变为微服务架构,多个服务之间需要协同工作。这时候,事务管理变得复杂起来,因为数据操作分布在不同的服务和数据库上。
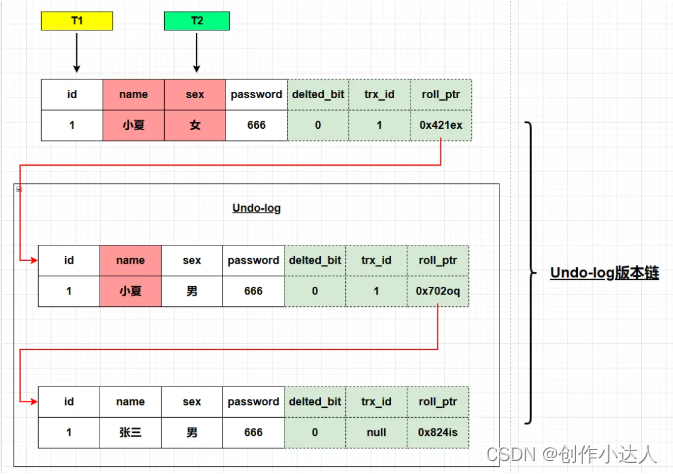
事务是数据库操作的最小工作单元,一组不可再分割的操作集合,是作为单个逻辑工作单元执行的一系列操作。这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行事务具有四个特征,分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),简称为事务的 ACID 特性如何保证事务的 ACID 特性?原子性(Atomicity):事

Invoker是实体域,它是Dubbo的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起invoke调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。在微服务架构中,Dubbo可以作为服务治理的核心框架,通过服务注册中心来实现服务的注册与发现,通过负载均衡策略来实现服务调用的负载均衡。Dubbo的服务治理功能可以实现服务的注册、发现、路由和负载均衡

数据分片是一种将数据分割并存储在多个节点上的技术,可以有效提高系统的扩展性和性能。在Redis中,数据分片主要用于解决单个实例存储容量和性能瓶颈的问题。通过将数据分散存储到多个Redis节点中,可以将负载均衡到不同的服务器上,提高系统的吞吐量和响应速度。
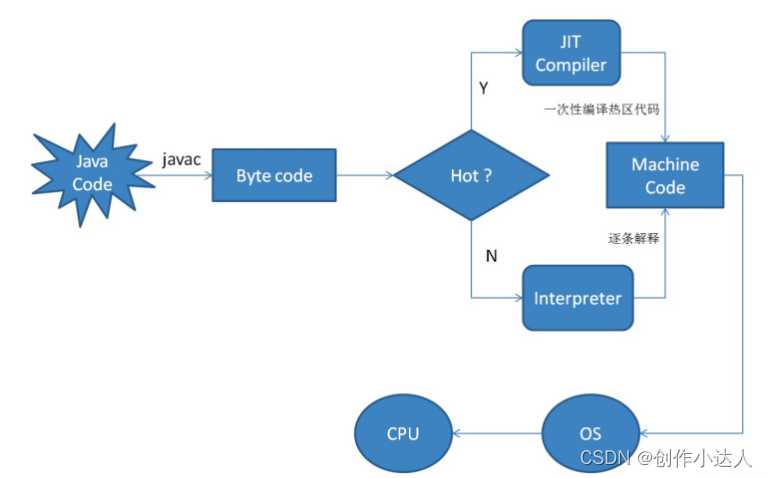
JIT(即时编译)是一种编译技术,它将程序在运行时动态地进行编译,以提高程序的执行效率。JIT编译器将程序的某些部分(通常是热点代码)从解释执行转换为本地机器码,以便直接在CPU上执行,而无需再次解释执行。这种优化技术广泛应用于动态语言、虚拟机和一些解释型语言的执行环境中。我们知道,想要把高级语言转变成计算机认识的机器语言有两种方式,分别是编译和解释,虽然Java转成机器语言的过程中有一个步骤是要
Kafka架构,由多个组件组成,如下图所示:主要会包含:Topic、生产者、消费者、消费组等组件。Broker是Kafka集群中的一个节点,每个节点都是一个独立的Kafka服务器。它负责存储和处理发布到Kafka的消息,消息以主题(topic)的形式进行分类和组织。如下图所示:每个Broker可以承载多个主题的分区(partition),并使用日志文件(log)来持久化存储消息。

在设计与金融场景以及其他要求数据不能丢失的环境中,我们会采用同步方式将数据写入CommitLog。成功执行写入操作后才返回,确保了数据的完整性和安全性。只有在broker的物理存储设备出现故障的情况下,才有可能导致数据丢失。为了提供进一步提高数据的安全性,也可以通过多台服务器进行数据备份。但值得注意的是, 尽管实现了对数据的安全性提升, 使用同步写入CommitLog方式会降低系统的性能到几个数量

kafka重平衡的主要发生在消费者端,重平衡的目的,主要是为了均衡消费者消费kafka的消息而设计的,对于动态加入消费者,减少消费者,以及消息分区变化这些场景中,若不设计消费者重平衡,容易出现某个消费者消费消息出现倾斜的情况,如:某个消费者消费的消息特别多,而某些消费者不消费消息,造成资源的浪费。在上图的基础上,消费者群组处于 PreparingRebalance 状态后,很不幸,没人玩儿了,所有

为了实现消息的顺序消费,可以根据业务需求将相关消息发送到同一个分区,并且使用单个消费者实例来消费该分区的消息。同时,Kafka还提供了分区器(Partitioner)机制,可以根据消息的键(key)来决定消息被发送到哪个分区,从而进一步控制消息的顺序消费。在一个分区中,消息的顺序是有序的,这意味着先发送的消息会被存储在分区的前部,而后发送的消息会被追加到分区的末尾。如果一个消费者消费了多个分区,某

当一个事务在尝试读取一条数据时,