




- @2202_75347029
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
项目地址:https://github.com/ultralytics/ultralyticsYOLOv8 是 Ultralytics 公司于 2023 年推出的最新一代 YOLO(You Only Look Once)实时目标检测模型,继承并优化了 YOLO 系列“单阶段、端到端、高精度、高速度”的核心理念。它在架构设计上融合了先进的骨干网络(如 C2f 模块)、更高效的特征金字塔(PAN-FP
聊天平台每天都会有大量的用户在线,会出现大量的聊天数据,通过对聊天数据的统计分析,可以更好的对用户构建精准的用户画像,为用户提供更好的服务以及实现高 ROI 的平台运营推广,给公司的发展决策提供精确的数据支撑。项目将基于一个社交平台 App 的用户数据,完成相关指标的统计分析并结合 BI 工具对指标进行可视化展现。从 A 抽取数据 (E) ,进行数据转换过滤 (T) ,将结果加载到 B(L) ,就

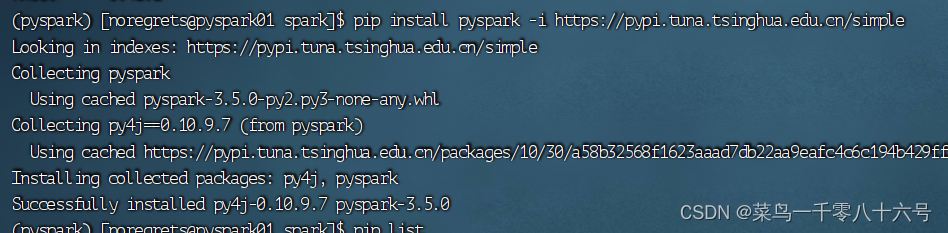
一、pyspark类库类库:一堆别人写好的代码,可以直接导入使用,例如Pandas就是Python的类库。框架:可以独立运行,并提供编程结构的一种软件产品,例如Spark就是一个独立的框架。PySpark是Spark官方提供的一个Python类库,内置了完全的Spark API,可以通过PySpark类库来编写Spark应用程序,并将其提交到Spark集群中运行。(1)下载PySpark库。
将SQL语句翻译成MapReduce程序运行。基于Hive为用户提供了分布式SQL计算能力,写的是SQL,运行的是MapReduce。Hive的优点:①操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。②底层执行MapReduce,可以完成分布式海量数据的SQl处理。

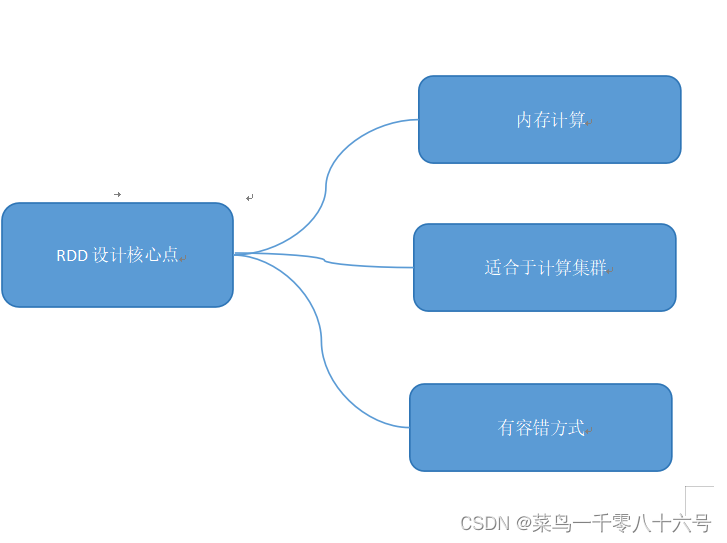
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面元素可并行计算的集合。可以认为RDD是分布式的列表List或数组Array,抽象的数据结构,RDD是一个抽象类Abstract Class和泛型Generic Type。
l值:l = V[$_CAHJk(326)](yt[$_CAIAL(291)](o), r[$_CAHJk(766)]()),其中yt[$_CAIAL(291)]其实就JSON.stringify方法,r[$_CAHJk(766)]()就是之前生成的随机字符串。V[$_CAHJk(326)]直接扣代码即可。其中this[$_CBGAs(766)](t)是一个随机字符串生成函数,可以固定写死,new
一、array类型建表语句:create table 表名(要素1 类型,要素2 类型,要素3 array)row format delimited filedsterminated by '\t' collection items terminated by ',';

聊天平台每天都会有大量的用户在线,会出现大量的聊天数据,通过对聊天数据的统计分析,可以更好的对用户构建精准的用户画像,为用户提供更好的服务以及实现高 ROI 的平台运营推广,给公司的发展决策提供精确的数据支撑。项目将基于一个社交平台 App 的用户数据,完成相关指标的统计分析并结合 BI 工具对指标进行可视化展现。从 A 抽取数据 (E) ,进行数据转换过滤 (T) ,将结果加载到 B(L) ,就
包含Hive、MySQL等安装配置

一、pyspark类库类库:一堆别人写好的代码,可以直接导入使用,例如Pandas就是Python的类库。框架:可以独立运行,并提供编程结构的一种软件产品,例如Spark就是一个独立的框架。PySpark是Spark官方提供的一个Python类库,内置了完全的Spark API,可以通过PySpark类库来编写Spark应用程序,并将其提交到Spark集群中运行。(1)下载PySpark库。