字节「Coze 扣子」无需编程即可开发 AI 应用,实际体验如何?
大部分常用的 Python 库,在定义插件时都可以直接导入(比如 json,time,random)。其他一些必要的模块(比如 requests,datetime等),还可以从左侧的依赖包中添加,这就给了插件模块比代码模块高了几个维度的灵活性。
玩 COZE 一段时间了,总体来说还是比较容易上手的,一个教程没看(主要也是因为 COZE 的官方文档写的真是烂的可以)。本文主要提一些会令初学者焦头烂额的血泪教训,希望可以帮助到大家,后续会持续更新。
关于用户界面的布局
玩转用户界面主要靠容器,这里提一下几个容器的很重要参数:
位置参数
- 固定定位:相对于你浏览器界面固定,就是无论怎么滑动滚轮,这个容器是不动的。主要是用于固定的页面头部。(将父容器设置为固定定位,在界面右侧就不会出现小的滚动条)
- 绝对定位:父容器动,他才会动。
- 相对定位:最常用。
尺寸参数
- 百分比:占父容器的固定百分比。
- 填充容器:自动计算,平均分布。只要你的并列组件中有一个是填充容器,滚轮在父容器中运动时就不会让子容器来回晃动。
溢出
一般选滚动,特殊情况才会选隐藏。
常见困惑
不想要滚动的组件可以滚动:一个子容器可以在父容器中上下滚动,就是因为他的高度加上上下边距超过了父容器的固定高度!所以只要加大父容器的固定高度,或调小子容器的高度即可!(有时父容器不是固定高度也是出现这种情况,但原因同样是父容器的高度不足,调大百分比也可以解决。)
想要滚动的组件却卡死不动:首先,需要将父容器的溢出选项设置为“滚动”。如果仍然无法滚动,发生这种情况的原因多半是父容器是固定定位,且这个容器:(1)被设置为“固定”高度,且固定高度很大,超过了子容器的最大高度;(2)被设置为“百分比”,这个百分比的值超过一定数值也会导致超过了子容器的最大高度;(3)容器的高度被设置为“适应内容”;这样子容器没有发生溢出,自然就不会滚动。
禁用态和加载态
一般勾稽工作流的 loading 参数,即填入 {{工作流名称.loading}}。
可见性
这个就是控制隐藏。特别想提一点的就是,如果你想在工作流运行的时候显示一张加载图片,那么将这张图片的额可见性设置为 {{!工作流名称.loading}}(即取反)即可。
关于界面变量的引用
有时候界面返回值经常会出现:{"hidden":false,"value":"varible"},这种问题都是因为引用错误导致的,比如,你在引用一个输入变量时仅写了 {{ Textarea }},但其实应该是 {{ Textarea.value }}(也有可能是 .content,视具体情况而定)。
关于输出节点
输出节点只有在大模型节点之后才能开启流式响应。
如果输出节点绑定了消息卡片,即使开启流式输出,输出的卡片也是非流式的,卡片会等待所有回复内容加载完毕后一次性展示在对话中。
关于数据库
在SQL语句中引用字符串变量,需要在 {{}} 之外再加上半角单引号才行,像这样:
INSERT INTO datas (item, url) VALUES ('{{output_item}}', '{{output_url}}')关于代码模块
虽然学会使用代码模块是 COZE 小白到高级玩家的必经之路,但 COZE 的代码模块的灵活性还是比较有限的,并不是像一些小伙伴想的那样可以代替 Python IDE 。
因为不能导入大部分的 Python 库,所以代码模块只可以做一些简单的数据操作。如果你需要写简单的爬虫代码,那么需要使用的是 HTTP 请求模块,而不是代码模块。如果你需要编写比较复杂的爬虫代码或进行比较复杂数据操作,那都是需要自己定义插件的。
下面有几个典型的我认为会用到代码模块的场景:
请注意!以下代码均已 Python 为例,注意请在 IDE 左上角将语言切换为 Python。
1、解决 DeepSeek 系模型在 Coze 的数据类型配适问题
DeekSeek 在 Coze 的配适有很大问题,经常无法输出输出数组,只能输出字符串,导致后续无法批处理。
所以目前阶段一个暂时的解决办法只能是在 DS 大模型模块提示词里明确要求其输出数组格式:
将 XX 存入名为 result 的数组,{"result": [XX]}
或者更加复杂一点可以是一个 Object 数组,比如:
## 输出规范:将一个 Dict 数组存入 result ,请确保各级括号闭合。
{"result": [{"title":标题1, "content":内容1}, {"title":标题2, "content":内容2}, {"title":标题3, "content":内容3}, ]}
不过要特别注意,输出中千万不要出现中文全角字符,且必须要确保各级括号闭合,是一个完整的字典,不然后续无法处理(遗憾的是目前好像只有 R1 可以完全做到,V3 不行)。
最后,将 DS 大模型模块的输出名称改为 result,输出类型调为 String 类型。输出符合要求的字符串后,接一个代码模块就可以将其转为数组(字符串数组或字典数组),以供后续的批处理:
import json
async def main(args: Args) -> Output:
params = args.params
raw_str = params['input']
start_index = raw_str.find('{')
end_index = raw_str.rfind('}')
json_str = raw_str[start_index:end_index + 1]
data = json.loads(json_str)
return data代码模块的输出名称也要改为 result,输出类型调为相应的 Array<String> 或 Array<Object>类型即可。
但事实上,上面都是 COZE 导致的衍生问题,如果 COZE 微调好了根本不需要这些操作。
2、数组整合
这个主要是用于后续在用户界面需要将数据输出到列表模块,那么必须将所有输出都整合到一个 List 当中。
情况一:已经有一个字典列表(Array<Object>),想要在这个字典列表中的每一项加一个键值对,形成一个新的字典列表(Array<Object>)
async def main(args: Args) -> Output:
params = args.params
additional_datas = params['additional_datas'] ## 要新加入的内容,确保列表长度与object_array一致
object_array = params['object_array'] ## 原来的字典列表
for i, object in enumerate(object_array):
object['additional_data'] = additional_datas[i]
return object_array情况二:将两个字典列表(Array<Object>)合并成一个新的(Array<Object>)
async def main(args: Args) -> Output:
params = args.params
original_list = params["original"]
extension_list = params["extension"]
result = []
for dict1, dict2 in zip(original_list, extension_list):
new_dict = {**dict1, **dict2}
result.append(new_dict)
return {"result": result}情况三:批处理解离。批处理后,会输出一个 Array<Object>,如果你想将 Array<Object> 拆解为多个独立的 List(可能要用于后续的大模型输入),就需要用到以下代码:
async def main(args: Args) -> Output:
params = args.params
array_a = []
array_b = []
for item in params['input']:
percent.append(item['item_a'])
bargain.append(item['item_b'])
return {
"item_a": array_a,
"item_b": array_b,
}情况四:读取数据库某几行的样本,假设每一行样本都有四列:label(单个单词),list_a(列表),list_b(列表),list_c(列表)。可以用下面的代码把这几行内容整合成一个 Array<Object> 输出
def combinex(*lists, names):
# 检查输入的列表长度是否一致
list_lengths = [len(lst) for lst in lists]
if len(set(list_lengths)) > 1:
raise ValueError("输入的列表长度不一致")
# 检查名称数量是否与列表数量一致
if len(lists) != len(names):
raise ValueError("名称数量与列表数量不一致")
result = []
for i in range(len(lists[0])):
item_dict = {}
for j, lst in enumerate(lists):
item_dict[names[j]] = lst[i]
result.append(item_dict)
return result上面这个函数是用于将几个内容 list 和 一个名称 list 合并为一个 Array<Object> ,Array 的每一个元素的 key 就是名称 list 的对应元素,Array 的每一个元素的 value 是抽取每一个 list 的对应元素组成的 list (有点小复杂。。。)。这个操作通常是用于读取数据库的某一行。
async def main(args: Args) -> Output:
params = args.params
output_dict = {
'key1' : "",
'key2' : "",
'key3' : "",
'key4' : "",
'value1' : [],
'value2' : [],
'value3' : [],
'value4' : [],
}
output_lenth = min(5, len(params['outputList'])+1)
for i in range(1, output_lenth):
output_dict[f'key{i}'] = params['outputList'][-i]['label']
output_dict[f'value{i}'] = combinex(
ast.literal_eval(params['outputList'][-i]['list_a']),
ast.literal_eval(params['outputList'][-i]['list_b']),
ast.literal_eval(params['outputList'][-i]['list_c']),
names=['aa', 'bb','cc']
)
return output_dict上面这个操作就是读取数据库中最新的 4 行,然后整合成 Array<Object>。代码的输入变量名为 outputList,输出变量名为 key1(String),key2(String),key3(String),key4(String),value1(Array<Object>),value2(Array<Object>),value3(Array<Object>),value4(Array<Object>)
关于自定义插件
导入必要的库
大部分常用的 Python 库,在定义插件时都可以直接导入(比如 json,time,random)。其他一些必要的模块(比如 requests,datetime等),还可以从左侧的依赖包中添加,这就给了插件模块比代码模块高了几个维度的灵活性。
配置好出入和输出
在代码试运行之前,一定要在“元数据”配置好输入参数,包括变量名和数据类型,不然肯定报错。输入变量在函数中是通过 args.input.变量名 来引用的,这和代码模块的 args.params.变量名 有点不同。
输出的配置可以在试运行之后,使用右下角的“更新输出参数”自动配置。但他有时候数据类型会出错,所以最好还是检查一下。
输出变量可以是各种输出类型,但主函数 handler 的输出必须是字典格式( Coze 里的 Object 类型),即:
{
"输出变量名_1": 输出变量_1,
"输出变量名_2": 输出变量_2,
"输出变量名_3": 输出变量_3,
}COZE 目前存在的几个严重问题
1、经常莫名奇妙地出现 Network Error,工作流可以跑通,但在用户界面运行时就会跳 Network Error。
2、非豆包大模型竟然有单任务调用次数限制,好像是 5 次,但 R1 好像没有这个限制。
3、按钮在后续添加悬浮或点击效果无效,必须在新建时先添加。
4、Coze的工作流更新非常不智能,如果你的按钮已经关联好工作流,之后如果工作流有更新,很多情况你需要删除原来的关联并重新关联一次,更新才会生效。显然,这是一个很大的 bug !
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以在文末CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享

AI产品经理,0基础小白入门指南
作为一个零基础小白,如何做到真正的入局AI产品?
什么才叫真正的入局?
是否懂 AI、是否懂产品经理,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
你是否遇到这些问题:
1、传统产品经理
不懂Al无法对AI产品做出判断,和技术沟通丧失话语权
不了解 AI产品经理的工作流程、重点
2、互联网业务负责人/运营
对AI焦虑,又不知道怎么落地到业务中想做定制化AI产品并落地创收缺乏实战指导
3、大学生/小白
就业难,不懂技术不知如何从事AI产品经理想要进入AI赛道,缺乏职业发展规划,感觉遥不可及
为了帮助开发者打破壁垒,快速了解AI产品经理核心技术原理,学习相关AI产品经理,及大模型技术。从原理出发真正入局AI产品经理。
这里整理了一些AI产品经理学习资料包给大家
📖AI产品经理经典面试八股文
📖大模型RAG经验面试题
📖大模型LLMS面试宝典
📖大模型典型示范应用案例集99个
📖AI产品经理入门书籍
📖生成式AI商业落地白皮书
🔥作为AI产品经理,不仅要懂行业发展方向,也要懂AI技术,可以帮助大家:
✅深入了解大语言模型商业应用,快速掌握AI产品技能
✅掌握AI算法原理与未来趋势,提升多模态AI领域工作能力
✅实战案例与技巧分享,避免产品开发弯路
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图
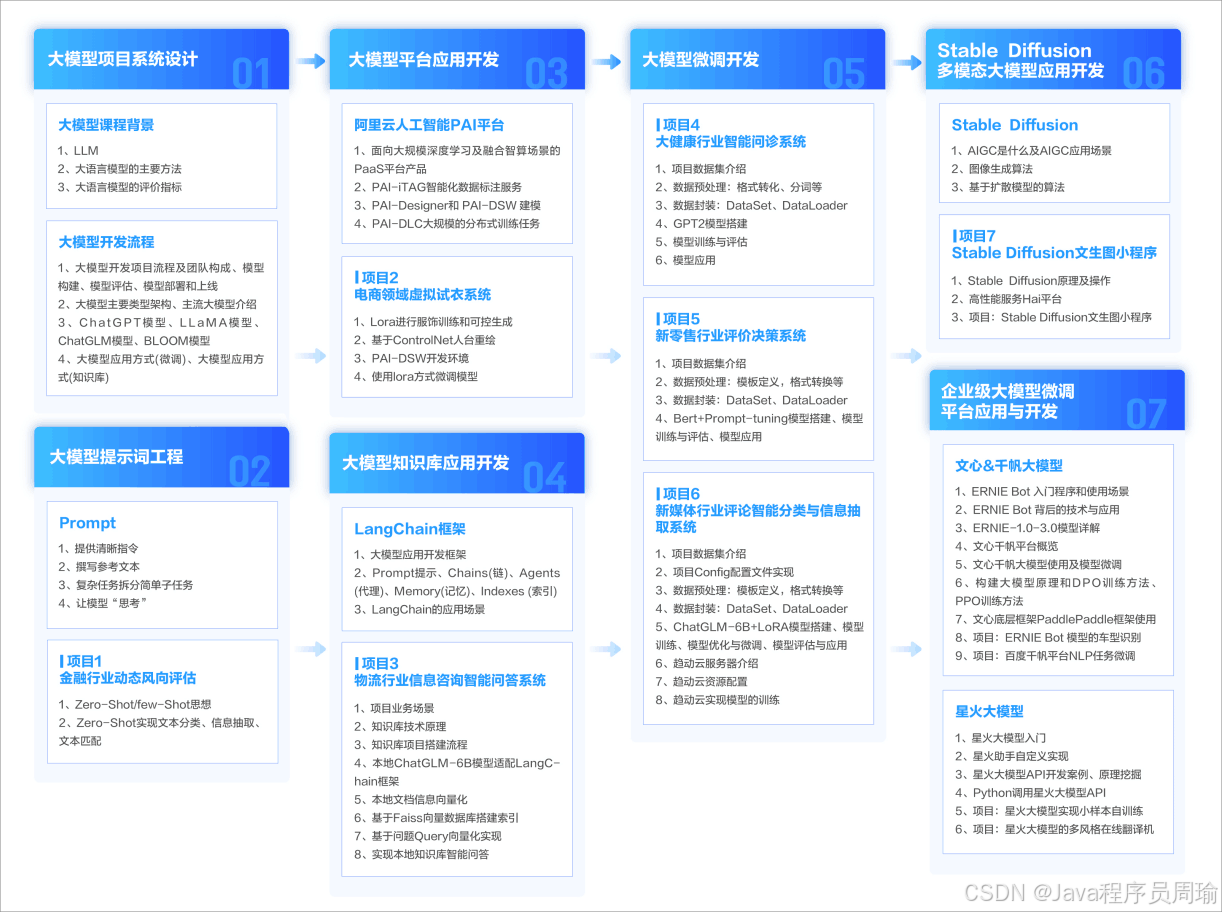
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享免费领取【保证100%免费】🆓

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)