YOLOv8【主干网络篇·第4节】LSKNet大核卷积遥感检测专用网络!
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。
✨ 特惠福利:目前活动一折秒杀价!一次订阅,永久免费,所有后续更新内容均免费阅读!
全文目录:
⏩ 零、摘要
大家好!欢迎回到我们的《YOLOv8专栏》!在本节中,我们将深入探索专为遥感图像目标检测设计的强大卷积网络——LSKNet(Large Selective Kernel Network)。遥感图像因其独特的“上帝视角”,常常包含着大量尺度差异巨大、背景复杂的物体,这给传统卷积神经网络带来了巨大挑战。
LSKNet通过其创新的大核选择机制,动态地调整感受野,极大地提升了模型在复杂场景下的特征提取能力。本文将从遥感检测的痛点出发,详细剖析LSKNet的核心原理、模块结构与实现细节,并手把手带您将LSKNet集成到YOLOv8的骨干网络中,通过详尽的代码实战与解析,让您彻底掌握这一前沿技术。准备好了吗?让我们一起开启这场大核卷积的探索之旅吧!🚀
⏩ 一、温故知新:上期内容回顾
在上一篇 《YOLOv8【卷积创新篇·第3节】EfficientNet系列主干网络替换实战》 中,我们详细探讨了堪称“效率典范”的EfficientNet家族。我们一起回顾了其核心的 **复合缩放(Compound Scaling)**策略,即如何通过一组固定的缩放因子α, β, γ,同时对网络的深度(depth)、宽度(width)和分辨率(resolution)进行优化,从而在提升性能的同时,精确地控制计算资源。
我们还深入分析了EfficientNet的基础构建块——MBConv,它巧妙地融合了深度可分离卷积、SE注意力机制以及残差连接,实现了特征提取效率和效果的完美平衡。最后,我们通过实战代码,演示了如何将EfficientNet-B0到B7的不同尺寸模型作为YOLOv8的骨干网络,为同学们在不同硬件资源下选择最优模型提供了清晰的指引。
EfficientNet的设计哲学,即在“资源约束”下追求“最优性能”,为我们后续的网络设计提供了宝贵的思路。而今天,我们将把目光投向一个更具挑战性的领域——遥感图像检测,看看LSKNet是如何用一种全新的“动态视角”来解决这个难题的。✨
⏩ 二、前言:遥感检测的挑战与大感受野的重要性
当我们处理常规的自然图像时,目标物体通常占据了画面的大部分区域,尺度也相对适中。然而,当我们切换到遥感视角(如卫星、无人机航拍),图像的特性发生了翻天覆地的变化:
- 尺度差异悬殊 (Vast Scale Variation): 同一幅图像中,可能既有占地上万平方米的机场、港口,也有仅占几个像素点的车辆、行人。这种巨大的尺度差异要求网络必须具备极强的多尺度特征捕捉能力。
- 方向任意性 (Arbitrary Orientation): 地面上的物体从空中俯瞰,可能呈现任意角度,这要求网络对旋转具有更好的鲁棒性。
- 背景复杂且小目标密集 (Complex Background & Dense Small Objects): 城市、山林、农田等背景信息极其复杂,小目标(如车辆、船舶)常常密集地排列在一起,极易被背景淹没或相互混淆。
传统的CNNs,尤其是那些使用3x3小卷积核堆叠而成的网络(如ResNet),其感受野(Receptive Field)的增长是相对缓慢和线性的。对于需要理解大范围上下文信息才能准确分类的大型目标(例如,识别一个“港口”,需要看到码头、船只、集装箱区等多个组成部分),有限的感受野显然力不从心。
因此,增大感受野,让网络“看”得更远、更广,成为了提升遥感检测性能的关键。简单粗暴地堆叠更多层或使用更大的固定卷积核(如11x11, 15x15)会带来两个问题:一是计算量和参数量急剧增加;二是对小目标的细节特征捕捉能力会下降。
有没有一种方法,可以智能地、动态地为图像的不同区域匹配不同大小的感受野呢?🤔 这正是LSKNet(Large Selective Kernel Network)试图解决的核心问题。它引入了一种巧妙的空间核选择机制,让网络能够根据输入特征,自适应地为每个像素位置选择最合适的卷积核尺寸,从而在不显著增加计算成本的前提下,实现巨大且灵活的感受野。
接下来,就让我们正式揭开LSKNet的神秘面纱!
⏩ 三、LSKNet核心思想深度剖析
LSKNet的核心思想可以概括为:通过并行处理多个大核深度卷积,并利用一个动态选择机制,将它们的输出进行加权融合,从而为不同的空间位置自地分配最合适的感受野。
3.1 大感受野需求分析:为何遥感检测有独钟”?
为了更直观地理解,我们来看一个例子。如下图所示,要识别左侧的“机场”,模型不仅要看到“跑道”,还要看到“航站楼”、“停机坪”等关联区域。一个小的感受野可能一次只能看到跑道的一部分,很容易将其误判为“公路”。而一个足够大的感受野则能将整个机场的布局尽收眼底,做出更准确的判断。
对于右侧密集停放的车辆,如果感受野过大,可能会将多辆车及其之间的空地“平滑”掉,导致漏检。此时,一个较小的感受野反而能更好地聚焦于单个车辆的精细特征。
LSKNet的设计正是为了应对这种“见大也见小”的复杂需求。它不满足于单一的、固定的感受野,而是追求一种“按需分配”的智能化特征提取模式。
3.2 LSK模块结构设计:优雅的动态选择艺术
LSKNet的核心在于其精心设计的LSK(Large Selective Kernel)模块。一个LSK模块通常嵌入在网络的残差结构中,取代标准的3x3卷积。其整体结构如下图所示:

从宏观上看,它遵循了经典的“瓶颈”设计(Bottleneck Design):
- 1x1卷积/升维:先用一个1x1卷积对输入特征进行通道扩展或压缩,为后续的大核卷积做准备。
- LSK核心单元:这是整个模块的灵魂,负责进行动态的大核卷积操作。
- 1x1卷积恢复:将核心单元输出的特征通过另一个1x1卷积恢复到与输入匹配的通道数。
- 残差连接:将处理后的特征与原始输入(通过一个快捷连接)相加,保证了梯度的顺畅传播,使得网络可以构建得更深。
真正的魔法发生在LSK核心单元内部。让我们把它“砸开”看看。
3 空间核选择机制:LSKNet的“最强大脑”
LSK核心单元内部可以分解为两个主要部分:卷积分支 (Large Kernel Convolution Branch) 和 核选择分支 (Kernel Selection Branch)。
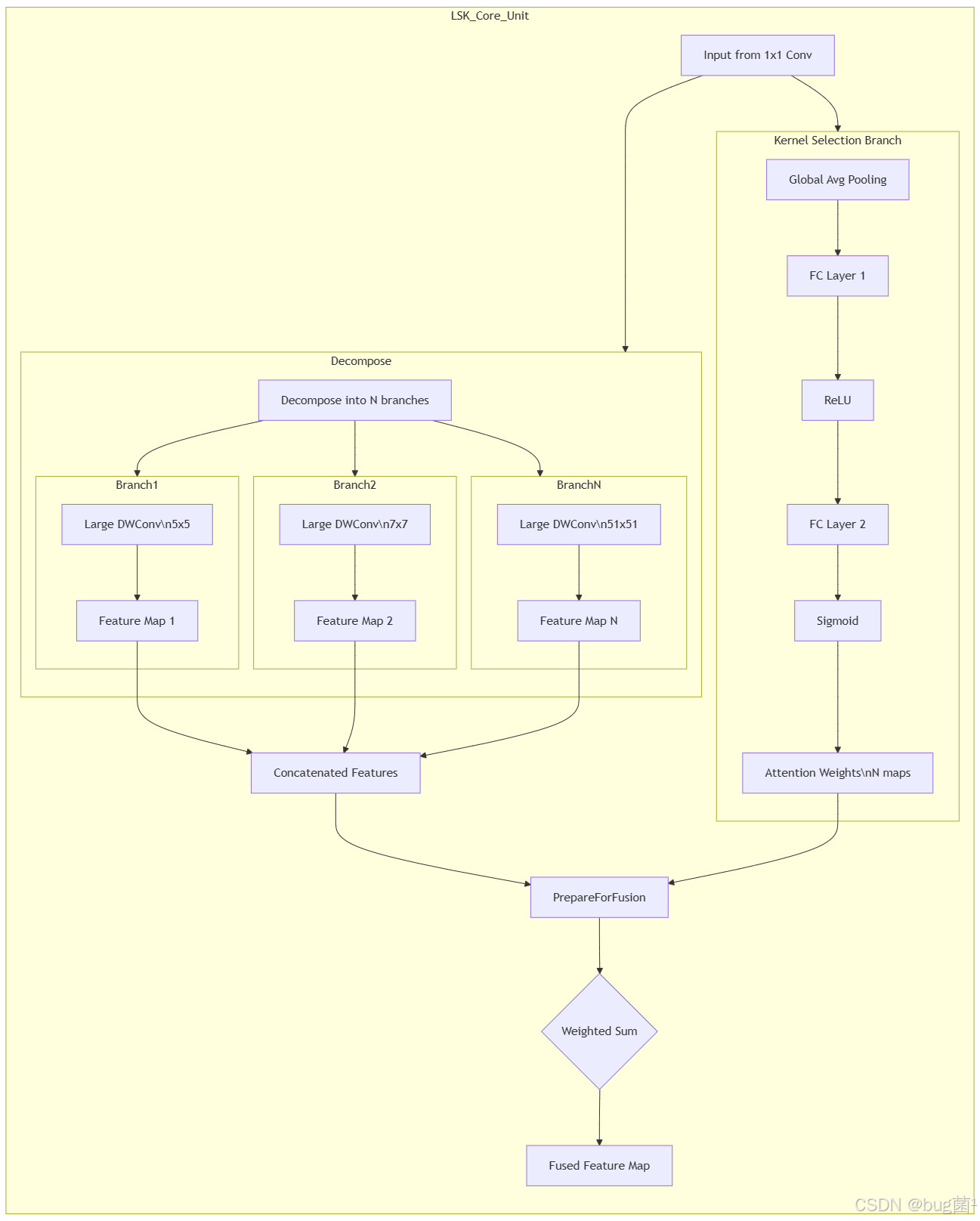
工作流程详解:
-
分解 (Decompose): 输入特征图在通道维度上被分解成N个部分,每个部分将送入一个不同的大核卷积分支。
-
大核卷积分支 (Large Kernel Convolution Branch):
** 这里有N个并行的分支,每个分支使用一个不同尺寸的** 大核深度可分离卷积(Large Kernel Depth-wise Convolution)**。例如,分支1用5x5,分支2用7x7,…,直到一个非常大的尺寸,如论文中提到的51x51。- 使用深度可分离卷积是为了在拥有大感受野的同时,极大地减少计算量和参数量。
- 每个分支输出一个经过特定感受野处理后的特征图
Feat_i。
-
特征拼接 (Concatenate): 将所有N个分支输出的特征图
Feat_1, Feat_2, ..., Feat_N沿着通道维度拼接起来。 -
择分支 (Kernel Selection Branch):
- 这一分支的作用是为拼接后的特征图生成一个“注意力图”,告诉模型在每个空间位置上,应该更关注哪个卷积核带来的信息。
- 它首先对输入特征进行全局平均池化(GAP),得到一个通道描述符。
- 然后通过两个全连接层(FC)来学习通道间的非线性关系,这与SE模块非常相似。
- 最后通过Sigmoid函数生成N个注意力权重图,每个图对应一个大核分支。这些权重图的维度与原始特征图的空间维度相同。
-
加权融合 (Weighted Sum):
- 将拼接后的特征图与生成的注意力权重图进行元素级相乘。
- 这相当于在每个像素位置,用注意力权重去调制来自不同大核分支的特征。如果某个位置的注意力权重在对应51x51核的通道上值很高,那么该位置的最终输出特征就主要来自于51x51核的贡献。
- 最后将加权后的特征相加(或通过1x1卷积融合),得到最终的输出特征图。
通过这个机制,LSKNet就实现了在同一层网络中,不同空间位置拥有不同大小的有效感受野,这对于处理尺度变化剧烈的遥感图像来说,无疑是一大利器!
⏩ 四、LSKNet代码全解析与实现 (PyTorch)
理论讲了这么多,是时候上代码了!Talk is cheap, show me the code. 😊 下面我们用PyTorch来实现一个完整的LSK模块。
4.1 LSK Block核心模块代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.modules.utils import _pair
class LSKBlock(nn.Module):
"""
LSK Block: Large Selective Kernel Block
专门为遥感等需要大感受野的场景设计
"""
def __init__(self, dim, kernel_sizes=[5, 7, 9, 11], LSK_group=4, split_ratio=0.25):
"""
初始化LSK模块
:param dim: 输入和输出的维度 (channels)
:param kernel_sizes: 一系列大卷积核的尺寸列表
:param LSK_group: LSK核心操作中的分组数
:param split_ratio: 维度划分比例,用于注意力机制
"""
super().__init__()
self.dim = dim
self.kernel_sizes = kernel_sizes
self.num_kernels = len(kernel_sizes)
self.LSK_group = LSK_group
# 1. 瓶颈结构中的第一个1x1卷积,用于升维
self.conv1 = nn.Conv2d(dim, dim, kernel_size=1)
self.bn1 = nn.BatchNorm2d(dim)
# 2. LSK核心单元
# 使用分组卷积实现并行的深度可分离卷积
# 每个组对应一个不同尺寸的卷积核
self.conv_dw = nn.ModuleList()
for i, ks in enumerate(kernel_sizes):
# 为每个卷积核创建一个深度可分离卷积层
# groups=dim // self.num_kernels 保证了每个组独立进行深度卷积
self.conv_dw.append(
nn.Conv2d(
dim // self.num_kernels,
dim // self.num_kernels,
kernel_size=ks,
padding=ks // 2,
groups=dim // self.num_kernels
)
)
# 3. 空间核选择机制 (注意力分支)
self.split_channels = int(dim * split_ratio)
self.conv_split = nn.Conv2d(dim, self.split_channels * self.num_kernels,
kernel_size=1, groups=self.LSK_group)
self.bn_split = nn.BatchNorm2d(self.split_channels * self.num_kernels)
# 全局平均池化
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 两个全连接层
self.fc1 = nn.Conv2d(dim, self.dim, kernel_size=1)
self.fc2 = nn.Conv2d(dim, self.dim * self.num_kernels, kernel_size=1)
# Softmax用于归一化注意力权重
self.softmax = nn.Softmax(dim=1)
# 4. 瓶颈结构中的第二个1x1卷积,用于降维/恢复
self.conv3 = nn.Conv2d(dim, dim, kernel_size=1)
self.bn3 = nn.BatchNorm2d(dim)
# 激活函数
self.act = nn.GELU()
def forward(self, x):
"""
前向传播函数
"""
# 保存输入,用于残差连接
identity = x
# -------- 进入瓶颈结构 ---------
# 1. 第一个1x1卷积和BN
x = self.bn1(self.conv1(x))
# -------- LSK核心单元 ---------
# 2. 将特征图在通道维度上分割成 N 份
# N = self.num_kernels
x_split = torch.split(x, self.dim // self.num_kernels, dim=1)
# 3. 并行执行不同尺寸的大核深度卷积
x_conv = []
for i in range(self.num_kernels):
x_conv.append(self.conv_dw[i](x_split[i]))
# 4. 将卷积后的结果拼接起来
x_merged = torch.cat(x_conv, dim=1)
# -------- 空间核选择机制 ---------
# 5. 计算注意力权重
# 全局池化 + 全连接层
s = self.avg_pool(x_merged)
s = self.fc2(self.act(self.fc1(s)))
# (B, N*C, 1, 1) -> (B, N, C, 1, 1)
# N是卷积核数量, C是每个分支的通道数
s = s.view(s.size(0), self.num_kernels, self.dim // self.num_kernels, 1, 1)
# 使用softmax在 'N' 这个维度上进行归一化,得到权重
attn_weights = self.softmax(s)
# 6. 加权融合
# (B, C_total, H, W) -> (B, N, C_branch, H, W)
x_merged_view = x_merged.view(x_merged.size(0), self.num_kernels, self.dim // self.num_kernels,
x_merged.size(2), x_merged.size(3))
# 注意力权重与特征图相乘
# attn_weights: (B, N, C, 1, 1)
# x_merged_view: (B, N, C, H, W)
# 广播机制会自动处理
fused_feat = attn_weights * x_merged_view
# (B, N, C, H, W) -> (B, N*C, H, W)
fused_feat = fused_feat.view(fused_feat.size(0), -1, fused_feat.size(3), fused_feat.size(4))
# -------- 瓶颈结构收尾 ---------
# 7. 第三个1x1卷积
x_out = self.bn3(self.conv3(fused_feat))
# 8. 残差连接
output = identity + x_out
return output
# 测试代码
if __name__ == '__main__':
# 创建一个 LSKBlock 实例
# 输入维度为64, 使用 5x5, 7x7, 9x9, 11x11 四种卷积核
lsk_block = LSKBlock(dim=64, kernel_sizes=[5, 7, 9, 11])
# 创建一个随机的输入张量
# B, C, H, W = (4, 64, 56, 56)
input_tensor = torch.randn(4, 64, 56, 56)
# 将模型和数据移动到GPU (如果可用)
if torch.cuda.is_available():
lsk_block = lsk_block.cuda()
input_tensor = input_tensor.cuda()
print("输入张量尺寸:", input_tensor.shape)
# 执行前向传播
output_tensor = lsk_block(input_tensor)
print("输出张量尺寸:", output_tensor.shape)
# 检查参数量
num_params = sum(p.numel() for p in lsk_block.parameters() if p.requires_grad)
print(f"LSKBlock 参数量: {num_params / 1e6:.2f} M")
4.2 代码逐行解析
-
__init__(self, ...):dim: 定义了模块处理的特征通道数,输入和输出通道数相同,符合残差块的设计。kernel_zes: 一个列表,定义了所有并行大核卷积的尺寸。代码的灵活性体现在这里,你可以轻松地尝试不同的组合,比如[7, 11, 13]。self.conv1,self.bn1: 瓶颈结构的入口,一个1x1卷积,用于特征变换,后面跟着一个BN层。self.conv_dw: 这是一个nn.oduleList,是实现并行处理的关键。我们循环kernel_sizes列表,为每个尺寸都创建一个深度可分离卷积层(groupsdim // self.num_kernels是实现深度卷积的核心)。注意padding = ks // 2是为了保持卷积后特征图的尺寸不变。self.avg_pool,self.fc1,self.fc2: 这三部分构成了注意力权重的生成网络。AdaptiveAvgPool2d(1)将每个通道的空间信息压缩成一个值,fc1和fc2(用1x1卷积实现,效率更高)则学习通道间的复杂关系,并最终输出足够多的通道数,以便为每个大核分支的每个通道都生成一个权重。self.softmax: 在dim=1(即我们自己view出来的num_kernels维度)上进行Softmax,确保对于每个像素的每个通道组,所有大核的权重之和为1。self.conv3,self.bn3: 瓶颈结构的出口,用于融合特征并恢复最终的通道数。
-
forward(self, x):identity = x: 保存原始输入,用于最后的残差连接,这是所有现代网络设计的基石。torch.split(, ...): 这是一个非常高效的操作,它将输入张量x沿着通道维度(dim=1)切分成self.num\_kernels\个小块,每个小块送入对应的大核卷积。x_conv.append(...)->torch.cat(…)`: 分别计算每个分支的卷积,然后将结果重新拼接起来。s = self.avg_pool(merged)…attn_weights = self.softmax(s): 完整地执行了注意力权重的计算过程。注意view操作的使用,它在不改变数据存储的情况下,重塑了张量的形状,以便进行后续的softmax和加权操作。attn_weights * x_merged_view: 这是最核心的加权操作。PyTorch的广播机制(Broadcasting)在这里发挥了巨大作用。attn_weights的形状是(B, N, C, 1, 1),x_merged_view的形状是(B N, C, H, W)。相乘时,attn_weights会自动扩展(广播)到(B, N, C, H,W),从而实现元素级的加权。output = identity + x_out: 最后的残差相加,完成一次LSK Block的计算。
这段代码不仅实现了LSKNet的核心功能,而且具有很好的可读性和扩展性,您可以基于它进行各种实验和改进。👍
⏩ 五、实战演练:将LSKNet集成为YOLOv干网络
现在,激动人心的时刻到了!我们要将上面实现的LSKBlock集成到YOLOv8的骨干网络中,替换掉原有的C2f模块,打造一个拥有超大动态感受野的全新YOLOv8!
集成过程主要分为三步:
- 创建LSK模块文件: 将我们的
LSKBlock代码保存成一个独立的Python文件。 - 修改YOLOv8模型定义: 在YOLOv8的代码库中,引入
LSKBlock并用它构建新的主干。 - 编写新的YAML配置文件: 定义新模型的网络结构。
5.1建LSKNet基础模块 (ultralytics/nn/modules/lsk_block.py)
首先,在你的YOLOv8项目文件夹中,找到ultralytics/nn/modules/目录,在里面创建一个新的文件,命名为lsk_block.py,然后将我们上面写的LSKBlock类的全部代码粘贴进去。
为了能和YOLOv8的C2f模块无缝替换,我们最好再封装一层,让它的输入输出参数和C2f保持一致。我们创建一个LSKCSP`模块。
# 在 lsk_block.py 文件中,除了 LSKBlock,再增加以下内容
import torch
import torch.nn as nn
# ... (LSKBlock 的代码放在这里) ...
class LSKCSP(nn.Module):
"""
LSK Block with Cross Stage Partial connection.
参照 C2f 模块的结构,将核心卷积替换为 LSKBlock
"""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
"""
初始化LSKCSP模块
:param c1: 输入通道数
:param c2: 输出通道数
:param n: LSKBlock 的重复次数
:param shortcut: 是否使用残差连接
:param g: 分组数 (未使用,保持接口一致)
:param e: 通道扩展因子
"""
super().__init__()
# 计算隐藏层通道数
self.c = int(c2 * e)
# 两个1x1卷积,用于分割和融合特征
self.cv1 = nn.Conv2d(c1, 2 * self.c, 1, 1, bias=False)
self.cv2 = nn.Conv2d((2 + n) * self.c, c2, 1, bias=False)
self.bn = nn.BatchNorm2d(2 * self.c)
self.act = nn.SiLU()
# 核心的 LSKBlock 堆叠
# 注意:这里我们简化了kernel_sizes的配置,实际可以做的更灵活
self.m = nn.Sequential(*(LSKBlock(self.c, kernel_sizes=[5, 7, 9]) for _ in range(n)))
def forward(self, x):
# 将输入x通过cv1后,在通道维度上分割成两部分
y = list(self.cv1(x).split((self.c, self.c), 1))
# 其中一部分经过n个LSKBlock的处理,并将每次的输出都拼接起来
y.extend(m(y[-1]) for m in self.m)
# 最后通过cv2进行特征融合
return self.cv2(torch.cat(y, 1))
说明:
LSKCSP的结构模仿了C2f,它首先将输入特征分成两半,一半直接保留,另一半送入由n个LSKBlock组成的序列中进行深度处理。y.xtend(...)这种结构保留了每一层LSKBlock的输出,实现了跨阶段的特征融合,这有助于梯度的传播和特征的复用。- 这样封装后,
LSKCSP就可以像C2f一样,在YAML文件中被直接调用了。
5.2 改造YOLOv8主干,融入LSKNet
现在我们需要让YOLOv8认识我们新的LSKCSP模块。
-
在
ultralytics/nn/tasks.py中导入块:
打开tasks.py文件,在最顶部的导入区域,加入我们的LSKCSP。# ultralytics/nn/tasks.py # ... other imports from .modules import (C1, C2, C3, C2f, ...) from .modules.lsk_block import LSKCSP # <--- 添加这一行 -
在
__init__函数中注册新模块:
在同一个文件的parse_model函数附近(通常在DetectionModel类或其基类BaseModel的__init__中),找到一个类似字典或if-elif链的模块注册表,将LSCSP加进去。# 在 DetectionModel 类的 __init__ 方法或 parse_model 函数中 # 找到模块映射的地方 # 例如,在 ultralytics/nn/tasks.py 的 parse_model 函数内部 # ... # for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # m = eval(m) if isinstance(m, str) else m # eval strings # if m in (Classify, C1, C2, C3, C2f, ..., LSKCSP): # <--- 在这里加上 LSKCSP # c1, c2 = ch[f], args[0] # ... # 不同的YOLOv8版本可能位置不同,关键是找到这个模块解析的地方 # 在较新版本中,可能是在 ultralytics/nn/tasks.py 的 DetectionModel 类里 # self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist # ... # 需要确保在调用 `eval(m)` 时,LSKCSP 已经被导入并可见。小提示: 最简单的方式是直接在
tasks.py的MODULES字典(如果存在)或全局作用域内,让LSKCSP这个名字可被eval函数找到。上面的导入语句通常就能实现这一点。
5.3 配置模型YAML文件,训练
最后一步,也是最灵活的一步,就是编写一个新的.yaml文件来定义我们基于LSKNet的YOLOv8模型结构。
-
创建
yolov8-lsk.yaml:
在ultralytics/models/v8/目录下,复制一份yolov8.yaml并重命名为yolov8-lsk.yaml。 -
修改
backe部分:
打开yolov8-lsk.yaml,找到backbone的定义,将原来的C2f模块替换为我们自定义的LSKCSP模块。你可以选择性地替换,比如只替换后面几层感受野需求更大的C2f`。# Ultralytics YOLO 🚀, AGPL-3.0 license # YOLOv8-LSKNet model configuration file # Parameters nc: 80 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple # Anchors anchors: null # Backbone backbone: # [from, number, module, args] - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 - [-1, 3, C2f, [128, True]] - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 - [-1, 6, C2f, [256, True]] - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 - [-1, 6, LSKCSP, [512, True]] # <--- 在这里替换!使用 LSKCSP - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 - [-1, 3, LSKCSP, [1024, True]] # <--- 在这里替换!使用 LSKCSP - [-1, 1, SPPF, [1024, 5]] # Head head: # ... (head部分保持不变)在这个例子中,我们替换了主干网络后面两个阶段的
C2f模块。因为网络的深层部分负责提取更高级的语义信息,对感受野的要求更大,所以在这里使用LSKCSP能最大化其优势。 -
开始训练!
现在,你可以像训练标准YOLOv8模型一样,使用这个新的配置文件了:
yolo detect train data=your_dataset.yaml model=yolov8-lsk.yaml epochs=100 imgsz=640
恭喜你!你已经成功地将一个先进的大核选择网络集成到了YOLOv8中。通过这个过程,你不仅学会了LSKNet的原理,更掌握了如何对YOLOv8进行深度定制和魔改的核心技能!这绝对是值得庆祝的巨大进步!🎉
⏩ 六、SKNet性能优势与思考
6.1 遥感图像特征提取的优势
相比于传统的CNN,LSKNet在遥感图像上展现出明显的优势:
- 上下文感知能力强: 巨大的感受野使得模型能够理解目标与其周围环境的关系,有效区分相似物体(如区分河流中的“桥”和岸边的“堤坝”)。
- 抑制噪声: 通过动态选择,模型可以为简单的背景区域分配一个平滑的大核,有效抑制纹理噪声,同时为包含小目标的复杂区域分配更精细的小核。
- 参数效率高: 借助深度可分离卷积,LSKNet在获得巨大感受野的同时,并没有引入过多的参数和计算量,保持了模型的轻量化。
6.2 多目标的完美适配
LSKNet最核心的亮点在于其对多尺度目标的自适应能力。传统的图像金字塔(Image Pyramid)或特征金字塔网络(FPN)是在不同层级上解决多尺度问题,而LSKNet是在同一层内,通过空间维度的动态选择来解决多尺度问题。这两种方法是互补的,当LSKNet作为主干网络,再配合YOLOv8的FPN结构(如PANet),就形成了一个从“层内”到“层间”的全方位多尺度解决方案,理论上能极大地提升对各种尺寸目标的检测精度。
⏩ 七、总结与展望
在本篇超长篇幅的教程中,我们进行了一次从理论到实践的深度探索:
- 我们分析了遥感检测的痛点,明确了大感受的重要性。
- 深入剖析了LSKNet的核心,理解了其并行大核分支与空间核机制的精妙设计。
- 我们从零开始,用PyTorch手写了
LSKBlock,并对其代码进行了逐行解析。 - 最终,我们通过三步走的实战演练,成功地将LSKNet集成为YOLOv8的自定义主干,并给出了训练方法。
LSKNet为我们打开了一扇新的大门,它告诉我们卷积核不一定是固定不变的,而是可以根据内容动态变化的。这种“选择性”和“适应性”的思想,是近年来计算机视觉领域发展的一个重要趋势。
希望通过本文的学习,你不仅掌握了LSKNet这一个具体的模型,更能举一反三,将这种动态设计的思想应用到你未来的研究和项目中去。不断探索,不断创新,这正是我们学习的乐趣所在!你做得非常棒,坚持学到这里,已经超越了很多人!给你点赞!👍
⏩ 八、敬请期待:内容预告
在探索了专为遥感设计的“重量级”选手LSKNet之后,下一节,我们将把目光转向另一个极端——极致的轻量化!
在 《YOLOv8【卷积创新篇·第35节】MobileNetV3轻主干深度优化》 中,我们将一起探究大名鼎鼎的MobileNet家族的第三代力作。
- 它是如何利用**神经架构搜索(NAS)**技术,自动设计出最优的网络结构?
- 全新的h-swish激活函数相比ReLU和swish有何优势?
- 它又是如何巧妙地结合SE注意力机制,在极低的计算量下实现高精度的?
如果你对移动端部署、模型压缩和加速充满兴趣,那么下一节绝对不容错过!让我们一起揭开MobileNetV3高效背后的秘密!我们下期再见!👋 Bye~
希望本文所提供的YOLOv8内容能够帮助到你,特别是在模型精度提升和推理速度优化方面。
PS:如果你在按照本文提供的方法进行YOLOv8优化后,依然遇到问题,请不要急躁或抱怨!YOLOv8作为一个高度复杂的目标检测框架,其优化过程涉及硬件、数据集、训练参数等多方面因素。如果你在应用过程中遇到新的Bug或未解决的问题,欢迎将其粘贴到评论区,我们可以一起分析、探讨解决方案。如果你有新的优化思路,也欢迎分享给大家,互相学习,共同进步!
🧧🧧 文末福利,等你来拿!🧧🧧
文中讨论的技术问题大部分来源于我在YOLOv8项目开发中的亲身经历,也有部分来自网络及读者提供的案例。如果文中内容涉及版权问题,请及时告知,我会立即修改或删除。同时,部分解答思路和步骤来自全网社区及人工智能问答平台,若未能帮助到你,还请谅解!YOLOv8模型的优化过程复杂多变,遇到不同的环境、数据集或任务时,解决方案也各不相同。如果你有更优的解决方案,欢迎在评论区分享,撰写教程与方案,帮助更多开发者提升YOLOv8应用的精度与效率!
OK,以上就是我这期关于YOLOv8优化的解决方案,如果你还想深入了解更多YOLOv8相关的优化策略与技巧,欢迎查看我专门收集YOLOv8及其他目标检测技术的专栏《YOLOv8实战:从入门到深度优化》。希望我的分享能帮你解决在YOLOv8应用中的难题,提升你的技术水平。下期再见!
码字不易,如果这篇文章对你有所帮助,帮忙给我来个一键三连(关注、点赞、收藏),你的支持是我持续创作的最大动力。
同时也推荐大家关注我的公众号:「猿圈奇妙屋」,第一时间获取更多YOLOv8优化内容及技术资源,包括目标检测相关的最新优化方案、BAT大厂面试题、技术书籍、工具等,期待与你一起学习,共同进步!
🫵 Who am I?
我是数学建模与数据科学领域的讲师 & 技术博客作者,笔名bug菌,CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等社区博客专家,C站博客之星Top30,华为云多年度十佳博主,掘金多年度人气作者Top40,掘金等各大社区平台签约作者,51CTO年度博主Top12,掘金/InfoQ/51CTO等社区优质创作者;全网粉丝合计 30w+;更多精彩福利点击这里;硬核微信公众号「猿圈奇妙屋」,欢迎你的加入!免费白嫖最新BAT互联网公司面试真题、4000G PDF电子书籍、简历模板等海量资料,你想要的我都有,关键是你不来拿。

-End-

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)