一文搞懂什么是Hadoop?Hadoop的优点有哪些?Hadoop⽣态圈【详细介绍】
前情回顾:⼤数据是如何产⽣的?什么是数据仓库?目前为止,我们知道了海量数据的存储是使用数据仓库,而为了保证数据的质量呢,我们要有元数据管理,还有数据治理。而为了保证这些数据的性能、还有使用的效率等等,那么我们采取的是分层架构。在目前市面上用的比较广泛的数据仓库是Hive,而Hive又是依存于Hadoop这样一个开源的分布式计算平台上。所以本篇博客我们就来介绍一下Hadoop。Hadoop概述1 H
大家早上好,本人姓吴,如果觉得文章写得还行的话也可以叫我吴老师。欢迎大家跟我一起走进数据分析的世界,一起学习!
感兴趣的朋友可以关注我或者我的数据分析专栏,里面有许多优质的文章跟大家分享哦。
前情回顾:
⼤数据是如何产⽣的?
什么是数据仓库?
目前为止,我们知道了海量数据的存储是使用数据仓库,而为了保证数据的质量呢,我们要有元数据管理,还有数据治理。而为了保证这些数据的性能、还有使用的效率等等,那么我们采取的是分层架构。
在目前市面上用的比较广泛的数据仓库是Hive,而Hive又是依存于Hadoop这样一个开源的分布式计算平台上。所以本篇博客我们就来介绍一下Hadoop。
Hadoop概述
1 Hadoop简介
Hadoop是什么?简单来说,Hadoop就是解决⼤数据时代下海量数据的存储和分析计算问题。
Hadoop不是指具体的⼀个框架或者组件,它是Apache软件基⾦会下⽤Java语⾔开发的⼀个开源分布式计算平台,实现在⼤量计算机组成的集群中对海量数据进⾏分布式计算,适合⼤数据的分布式存储和计算,从⽽有效弥补了传统数据库在海量数据下的不⾜。
2 Hadoop优点
- ⾼可靠性:Hadoop按位存储和处理数据的能⼒值得⼈们信赖。
- ⾼扩展性:Hadoop是在可⽤的计算机集群间分配数据并完成计算任务,这些集群可以⽅便地扩展到数以千计的节点中。
- ⾼效性:Hadoop能够在节点之间动态地移动数据,并保持各个节点的动态平衡,因此处理速度⾮常快。
- ⾼容错性:Hadoop能够⾃动保存数据的多个副本,并且能够⾃动将失败的任务重新分配(比如一个计算机出现故障了,那有其他副本的计算机会重新进行工作,也就是说它这个容错性是很高的。)。
- 低成本:Hadoop是开源的,项⽬的软件成本因⽽得以⼤⼤降低。
3 Hadoop⽣态圈
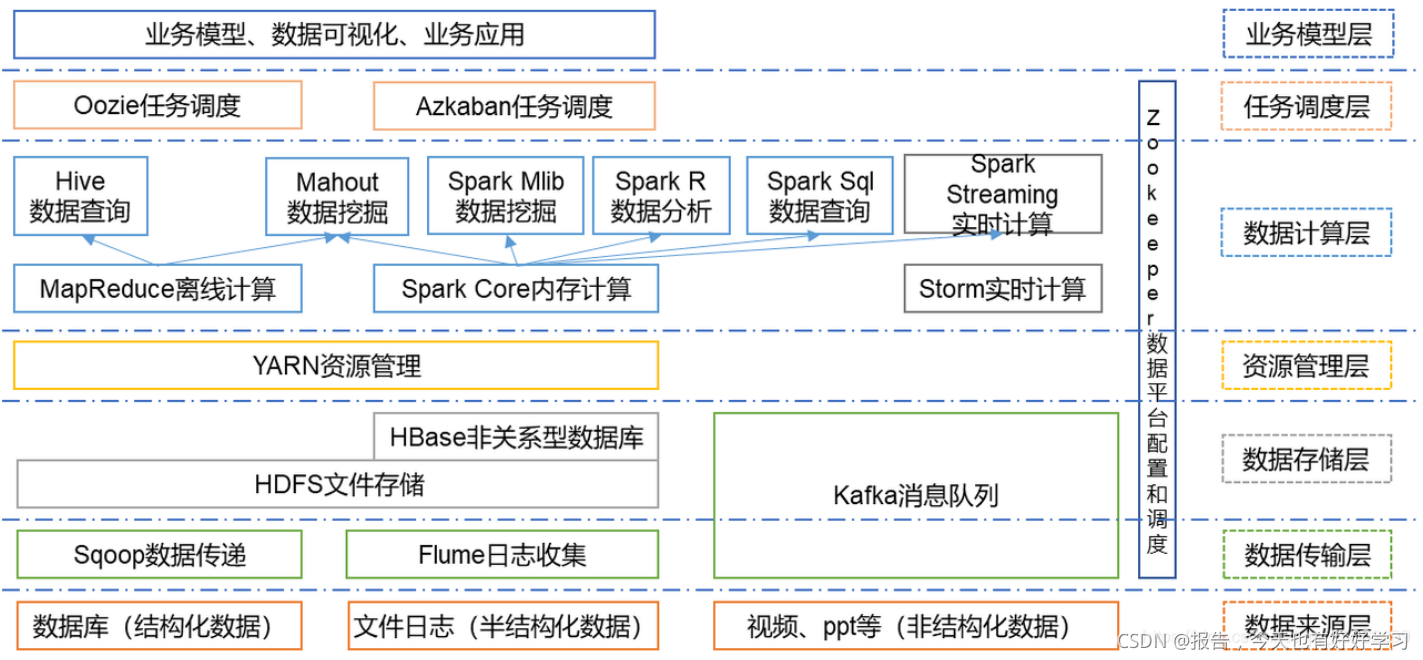
我们再来看一下Hadoop的生态圈,它的核心组件是HDFS,还有MapReduce。那随着处理任务的多样性,Hadoop生态圈它的组件会越来越多。


3.1 分布式存储(HDFS)
HDFS就是将⽂件切分成固定⼤⼩的数据块block(⽂件严格按照字节来切,所以若是最后切得省⼀点点,也算单独⼀块,hadoop2.x默认的固定⼤⼩是128MB,不同版本,默认值不同.可以通过Client端上传⽂件设置)。
它主要是负责分布式存储的,它把一个大文件切割成不同的小块,然后存储在相应的节点上,也就是计算机上。默认情况下呢它是把这个块分成一百二十八兆,当文件大于一百二十八兆的时候,它就会进行切割。
举个例子(如图),假如我现在有一个文件是二百兆,那它就切割了两块,分别放在不同的节点上。并且它对每一块进行备份,默认情况下是三个部分(本身加两个备份)。对于不同的副本,它是存储在不同的节点上的,那下一个我们可以这样算,也达到了这样子的三块。

也正是因为HDFS的这样一个分布式存储,还有多副本的备份,实现了Hadoop的这样一个容错性,还有就是工作量的均衡。
那如果我们把两块都存在了一个节点上,那当对这个数据进行处理的时候,我们可以第一块的计算那是在节点1,那对于第二块的计算,我们就到其他的副本节点上计算,让工作量保持均衡。
所以分布式存储保证了我们Hadoop系统的这样一个高容特性,还有高效性。
HDFS 的优点:
- 分布式存储
- ⽀持分布式和并⾏计算
- ⽔平可伸缩性
3.2 分布式计算(MapReduce)
MapReduce为海量的数据提供了计算。
MapReduce从它名字上来看就⼤致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将⼀个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。MapReduce采⽤"分⽽治之"的思想,简单地说,MapReduce就是"任务的分解与结果的汇总"。
举个例子,当有了对刚才的二百兆这个文件的一个计算的任务的时候,那MapReduce会把我们的这个任务分发给有这个块的这样一个节点,节点进行计算之后,然后他再整合输出。同理,也是因为MapReduce的分布式计算保证了Hadoop的高效性。
3.3 HBase
对于数据仓库来说,它存储的多数是历史数据,不太支持实时的这样一个交互。但是HBase它既存储数据,也能和HDFS进行交互,所以HBase存储的数据是可以支持实时的这样一个交互的,也就是说它可以用来完成MySQL、Oracle和SqlServer这样业务型数据库的功能,但是这样使用的还是比较少的。
所以在业务系统中,数据需要实时交互的,我们还是采用传统数据库比较好一些。
3.4 Zookeeper
Zookeeper,主要是对于我们的数据平台进行配置和调度的,主要是用来解决分布式应用中经常遇到的一些数据管理问题,例如统一命名、状态同步等等。它的目标就是封装好复杂、易出错的相关服务,将简单、易用的系统提供给用户。
举个例子,假设我们的程序是分布式部署在多台机器上的,也就是我们每一台机器上都有相应的应用程序。但是我们现在要更新,要改配置文件,那就需要逐台的来进行改变,这样就比较麻烦。但是现在呢我们把这个配置文件全部放在Zookeeper上,存储在Zookeeper上的某个目录中,然后相关的应用程序,也就是在每一台机器上的应用程序就会监测Zookeeper。当Zookeeper上的配置文件发生变化了之后,就会自动的进行下载、更新,这样我们就避免了每一台机器都进行逐步的更改。
3.5 Pig Hive ChuKwa
Pig、Hive和ChuKwa属于Hadoop生态圈的应用层,主要都是对数据进行处理和分析的,只是不同的场景,选择不同的组件会更好一些。
后期我会详细介绍Hive,其他两部分就暂时不介绍了。
结束语
一直在学习路上!
推荐关注的专栏
👨👩👦👦 机器学习:分享机器学习理论基础和常用模型讲解
👨👩👦👦 数据分析:分享数据分析实战项目和常用技能整理
关注我,了解更多相关知识!
CSDN@报告,今天也有好好学习

大数据从业者之家,一起探索大数据的无限可能!
更多推荐


 47
47 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)