
一文带你拆解vLLM:高吞吐推理是怎么炼成的
一文搞懂vLLM:为啥它能让一张GPU扛住几十倍用户?
这篇博客来聊聊vLLM到底是怎么工作的。顺便讲讲为啥需要它、它是怎么把显存玩出花的,以及在真实场景里它是怎么撑起那些动辄成千上万人同时在线的大模型服务的。
整篇文章会覆盖下面这些内容:
- 什么叫"serving 一个 LLM"
- 快速回顾一下 prefill、decode 和 KV cache
- 真正的痛点:KV cache 把显存吃光了
- 朴素的 serving 方式为啥浪费显存
- vLLM 到底是个啥
- PagedAttention 这个核心思路
- PagedAttention 是怎么把内存共享起来的
- Continuous batching(连续批处理)
- 兼容 OpenAI 接口的 API 服务
- 用 vLLM 能拿到哪些好处
- vLLM 在真实世界里的应用
下面正式开始。
什么叫"serving 一个 LLM"
在聊 vLLM 之前,得先搞清楚"serving 一个 LLM"到底是啥意思。
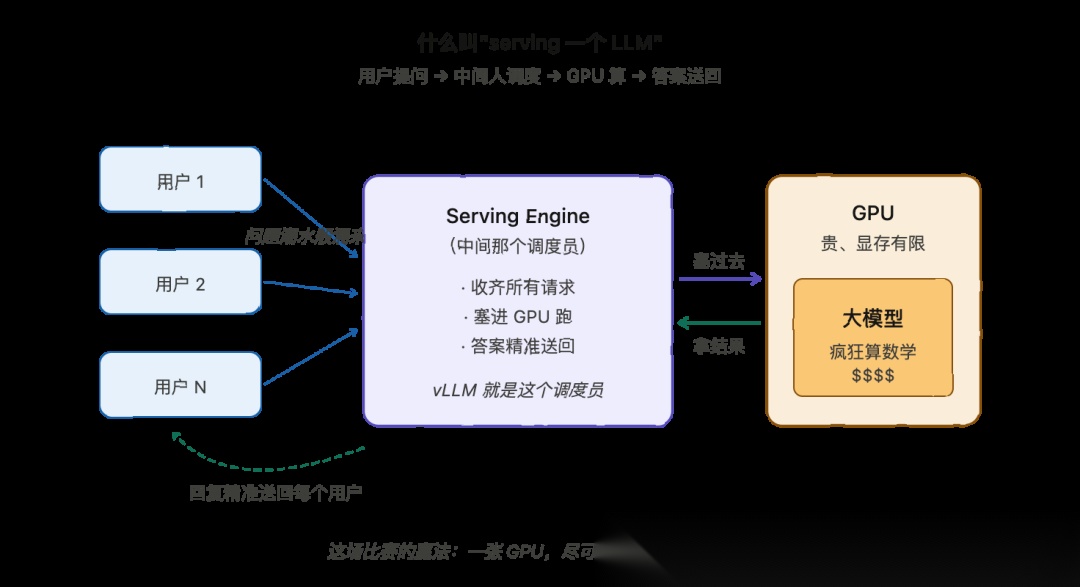
大语言模型(LLM)就是 ChatGPT、Claude 这些工具背后的那个东西。给它一段文字,它给你回一段文字,就这么简单。
所谓"serving 一个 LLM",说白了就是把模型跑在一台机器上,让很多用户能同时给它发问题、同时拿到答案。再通俗一点:serving 就是那一层负责接收用户请求、过一遍模型、再把回复送回去的东西。
举个场景。假设搭了一个聊天助手,几千号人同时打开它,每个人都在敲问题。所有问题一股脑涌向模型,每个人都盼着秒回。那个负责把这些请求都收下来、一个个跑模型、再把答案精准地送回每个对应用户手里的程序,就叫serving engine(推理服务引擎)。
这个流程长这样:
SERVING AN LLMUser 1 --question--> +-----------------+ +-----------------+User 2 --question--> | serving engine |----->| model on GPU |User 3 --question--> | (takes requests| | (does the heavy | ... | sends replies)|<-----| math, replies) |User N --question--> +-----------------+ +-----------------+ | +--reply--> back to each user
可以看到,很多用户同时发问题,serving engine 卡在中间,把所有请求收齐,扔给 GPU 上的模型跑,再把每个回复精准地送回对应的用户。
这里有个关键点要划重点:LLM 跑在 GPU 上。GPU 这种芯片专门擅长干 LLM 需要的那种暴力数学计算。但它有两个特点——贵,而且显存有限。所以一旦显存被浪费,能服务的用户数就掉下来,每个用户的成本就上去。
所以 serving 这件事的核心目标其实很朴素:在一张 GPU 上,尽可能服务更多用户、尽可能快。把这条目标记住,因为 vLLM 整个就是冲着赢下这场比赛去的。
快速回顾 prefill、decode 和 KV cache
要懂 vLLM,就得先稍微了解一下 LLM 是怎么一步步把答案吐出来的。别紧张,不会很烧脑。
当用户发来一段 prompt,模型并不会按完整的单词去读它。它会先把这段文字切成一小块一小块,叫 token。一个 token 大概就是一个词或者一个词的某一部分。所以 prompt 进了模型之后,变成的是一串 token。
接下来模型会分两个阶段干活。
第一个阶段叫 prefill。这个阶段模型会把整段 prompt 全部读一遍、消化一遍,但还一个字都没吐出来。说人话就是:prefill 就是模型把你整段输入啃完、嚼烂的过程。
第二个阶段叫 decode。这个阶段模型开始往外写答案,一次写一个 token。写一个 token,瞄一眼前面所有内容,再写下一个 token,就这么一直接龙下去,直到把答案写完。
而这两个阶段里,模型每处理一个 token,都会计算一些内部的中间值,然后把它们存起来。这些被存下来的东西,就放在一个叫 KV cache 的地方。
通俗解释一下 KV cache:模型每读到或写到一个 token,就会给它生成一份小笔记,记录这个 token 在上下文里到底意味着啥。KV cache 就是这一堆笔记的合集,每个 token 对应一份笔记。
为啥 KV cache 这么重要?因为 decode 阶段里,模型每写一个新 token,都得参考它前面所有 token 的笔记。要是没有 KV cache,模型每写一个字,就得把前面所有 token 的笔记重新算一遍——这速度慢到怀疑人生。所以模型把笔记算一次、存下来反复用。KV cache 就是让生成长答案变快的关键。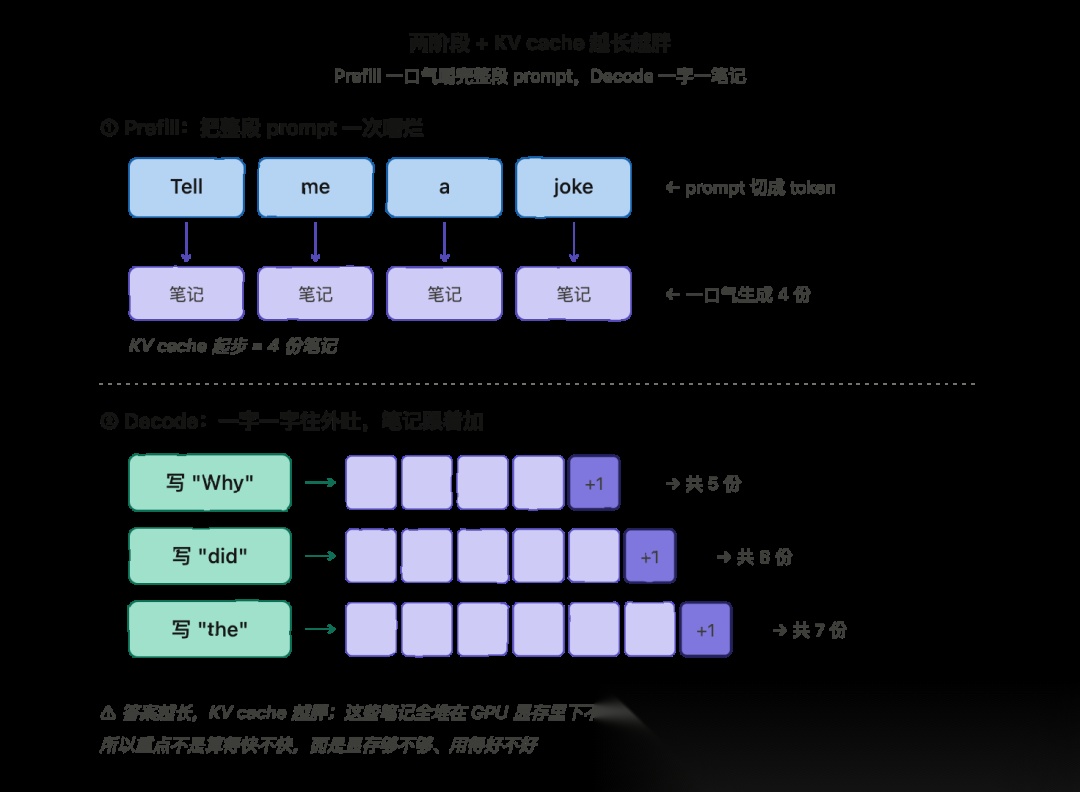
记住这一条核心:
“
KV cache 会随着答案越长越大。每多写一个 token,就要往 KV cache 里塞一份新笔记,而这些笔记全都躺在显存里。
可以这样画出来:
PREFILL then DECODE: the KV cache grows one set of notes per tokenprompt tokens: [ Tell ][ me ][ a ][ joke ] | | | |PREFILL writes: [n] [n] [n] [n] (one note per prompt token)so KV cache = [n][n][n][n] (4 notes after prefill)DECODE step 1: writes "Why" KV cache: [n][n][n][n][n]DECODE step 2: writes "did" KV cache: [n][n][n][n][n][n]DECODE step 3: writes "the" KV cache: [n][n][n][n][n][n][n] ... (grows by one each step)
可以看到,prefill 一上来就给每个 prompt token 都生成一份笔记。然后 decode 一个 token 一个 token 地写,每写一个就往 KV cache 里追加一份笔记。答案越长,KV cache 在显存里就越胖。
这就是基础,接下来该看真正的麻烦事了。
痛点来了:KV cache 把显存吃光了
知道了 KV cache 是啥,再来看它惹的麻烦。
模型本身就要占掉显存里很大一块。剩下的显存才能用来装当前所有正在服务的请求的 KV cache。
也就是说,KV cache 才是决定能同时服务多少用户的瓶颈。能腾出来给 KV cache 用的显存越多,能同时跑的请求就越多。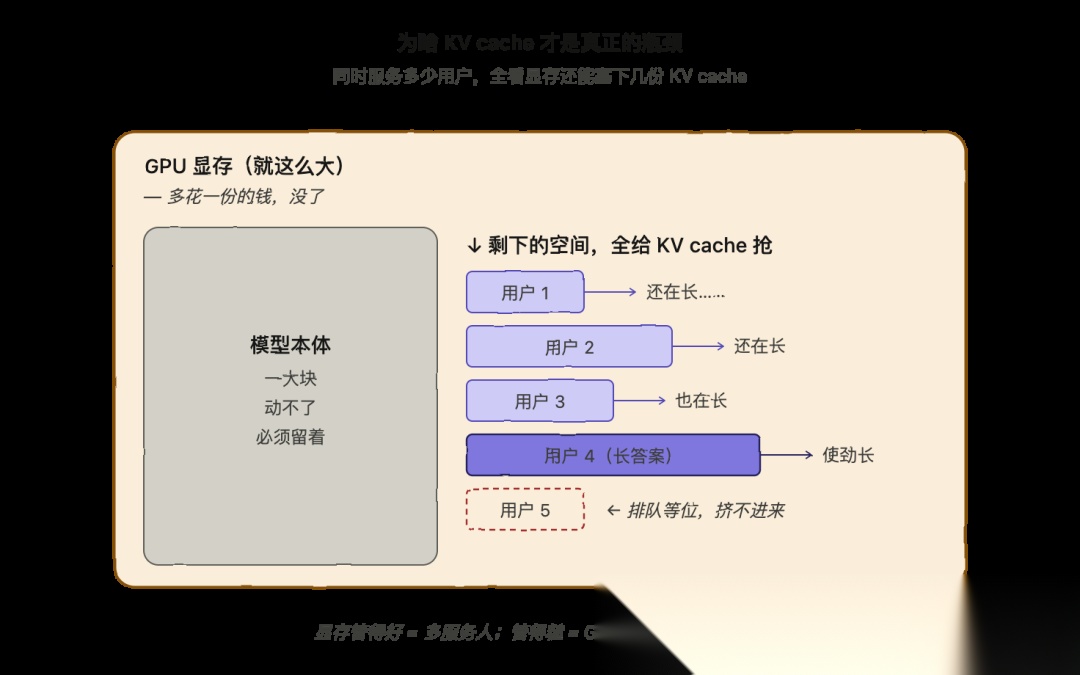
讲白点:每个正在跑的请求都有自己的一份 KV cache,而这份 KV cache 还在不断变大。如果同时服务几百几千个用户,所有人的 KV cache 全都挤在那一块显存里抢地盘。
所以 LLM serving 的真正瓶颈,根本不是算力快不快,而是 KV cache 的显存够不够、用得好不好。整件事的胜负手就是显存管理。管得好,多服务用户;管得糙,GPU 就在那里干瞪眼。
那个朴素的 serving 引擎是怎么管这块显存的,又错在哪了?往下看。
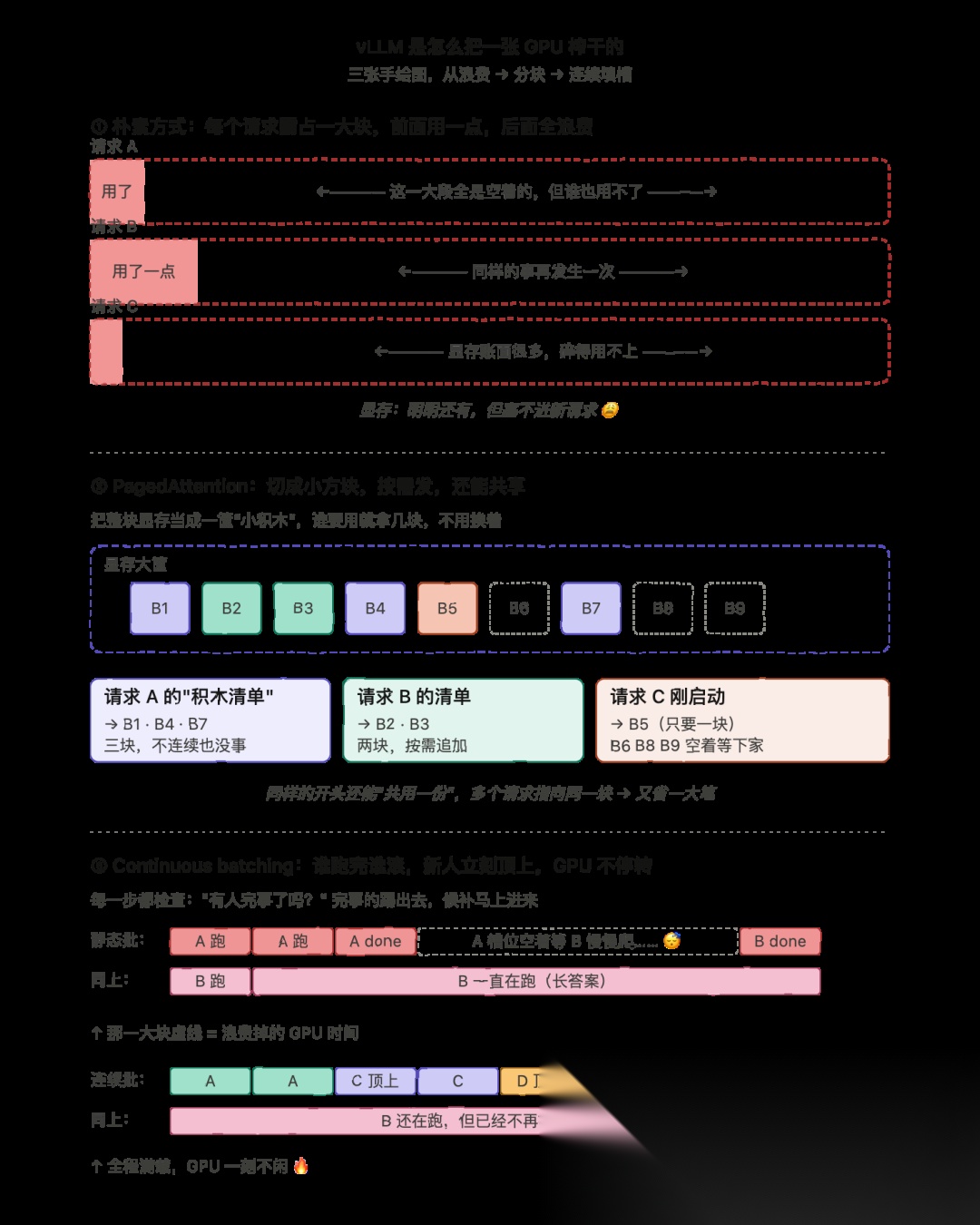
朴素 serving 方式为啥这么浪费
来看一个简单粗暴的 serving 引擎是怎么处理 KV cache 的,以及它栽在哪儿。
朴素方式做的事看起来挺"稳妥",但其实浪费得离谱。一个请求进来,引擎根本不知道这个答案最终会有多长。为了保险,它直接预留一整块连续的显存,按"最长可能的答案"来算。
举个例子。假设模型最多能生成 2000 个 token,那朴素引擎对每一个请求一上来就给它划走够 2000 token 用的 KV cache 空间——哪怕模型一个字都还没开始写。
问题来了。绝大多数答案根本没那么长。如果一个用户最后只回了 50 个 token,那剩下 1950 个 token 的空间就在那儿干放着,被预留了但啥也没干。一块巨大的显存就这么被锁死了,根本没用上。
这种浪费有两个名字,都得搞明白。
**第一个叫"过度预留"**(over-reservation)。就是预留的内存远远多于实际用到的内存。这块"被预留但没用"的空间,不能给别人用,纯纯浪费。
**第二个叫"碎片化"**(fragmentation)。意思是空闲的内存被切成了一堆零散的小碎片,没办法再利用。看图能更清楚:
NAIVE SERVING: one big continuous block reserved per requestRequest A: [#### used (50) ............... wasted, reserved for 2000 ..............]Request B: [###### used (120) ............ wasted, reserved for 2000 ..............]Request C: [## used (20) ................. wasted, reserved for 2000 ..............]free memory left: scattered tiny gaps -> cannot fit a new request
每个请求都霸占了一大整块连续显存,但前面只用了一点点。剩下的全是空的。而块和块之间残留下来的零碎空间又太小、太散,塞不进一个新请求。哪怕账面上显存还有不少,实际上就是用不了。这就是碎片化。
结局很憋屈。GPU 显存账面上看明明还很多,但因为浪费和碎片化的存在,能同时服务的用户数被压得很低。花了几万块钱买的 GPU,结果只用上了一小部分。
这时候 vLLM 就出场了。
vLLM 到底是个啥
知道了问题在哪,看下解法。
vLLM 是一个高吞吐(high-throughput)的 LLM serving 引擎。它的全部使命就是:在一张 GPU 上,把 KV cache 显存管得明明白白,从而尽可能多地服务请求。
简单说,vLLM 就是一个聪明的服务引擎——它不浪费 GPU 显存,所以同时能扛住的用户数能翻好几番。
顺便把"throughput"这个词捋一下,因为它就摆在 vLLM 名字里的"high-throughput"上。Throughput 翻译过来叫吞吐量,指单位时间里能完成多少活。高吞吐就是每秒能搞定的 token 数和请求数都特别多。vLLM 的目标就是把这个数字拉满。
vLLM 解决显存问题靠两个核心思路,配合工作:
- PagedAttention:不再一次性预留一大块显存,而是把 KV cache 切成小而固定的块,按需分配,几乎不浪费。
- Continuous batching:每一步都把跑完的请求踢出去、把新等待的请求顶上来,让 GPU 一刻都不闲着。
下面挨个拆。先讲 PagedAttention,这是 vLLM 的灵魂。
PagedAttention:核心思路
先一句话定义:
“
PagedAttention 把 KV cache 拆成固定大小的小块来管理,按需分配,而不是一上来就给一大块。
通俗讲就是:不再给每个请求塞一整块大蛋糕,而是按需切小块发给它。
这个思路其实是借鉴操作系统管内存的方式。操作系统管内存用的就是固定大小的小块,叫"页(page)"。一个程序要用更多内存了,操作系统就再给它一页。这些页不需要在物理上连成一片,操作系统会维护一张小表来记录每一页到底放在哪儿。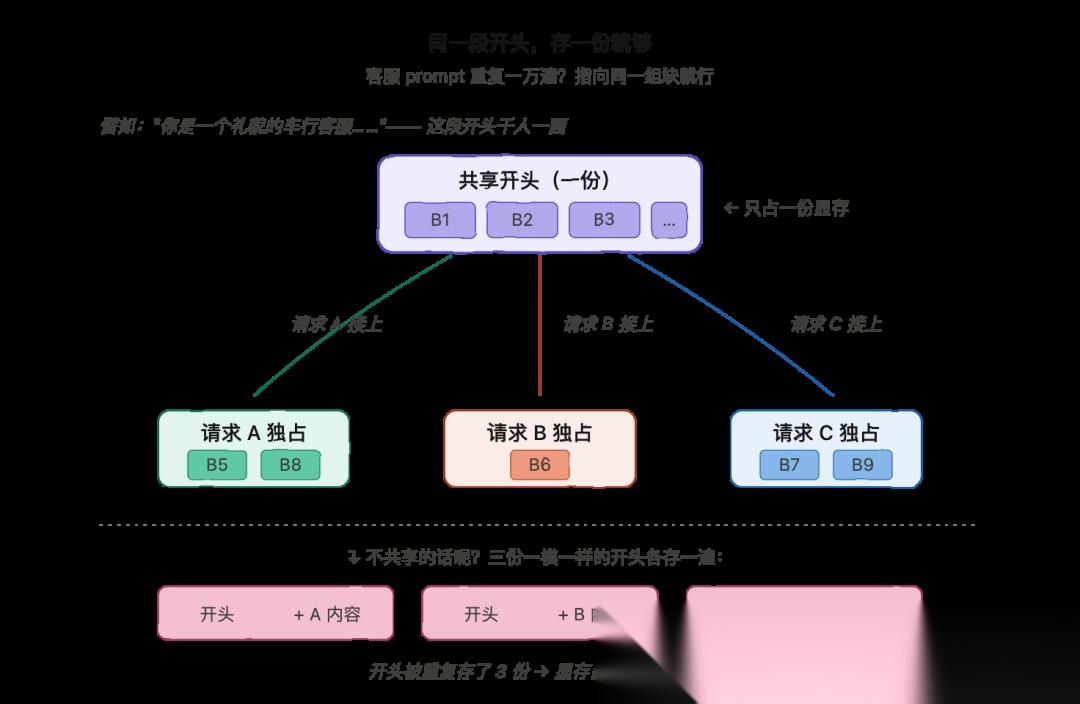
vLLM 对 KV cache 做的就是一模一样的事。它把整块 KV cache 显存切成一堆固定大小的小块,每块能装比如 16 个 token 的笔记。当某个请求需要存更多 token 了,vLLM 就再给它一块。这些块不需要在显存里挨着。vLLM 会维护一张叫 block table(块表) 的小表,记录哪些块属于哪个请求、按什么顺序。
走一遍流程感受下:
第一步:一个请求进来开始生成答案。vLLM 给它分一块,够装 16 个 token。请求开始往里填。
第二步:答案超过 16 个 token 了,第一块满了。vLLM 立马再给它分一块,只要显存里还有空闲块,随便哪个都行,不需要挨着前一块。
后续:答案继续往下写,vLLM 就继续按需一块块地发。请求一旦结束,vLLM 立刻把它名下所有的块全部回收,扔回空闲池,立等下一个请求来取。
画出来长这样:
PAGED ATTENTION: KV cache split into small fixed-size blocksGPU memory: [B1][B2][B3][B4][B5][B6][B7][B8][B9] ... (a pool of equal blocks)Request A's block table -> B1, B4, B7 (3 blocks, given as needed)Request B's block table -> B2, B3 (2 blocks, given as needed)Request C's block table -> B5 (1 block, just started)free blocks ready to hand out: B6, B8, B9
可以看到,整块显存变成了一个大小相同的块的共享池。每个请求只拿走自己真正需要的那几块,分布在池子里任何位置都行。块表就是那张小地图,按顺序把请求和它的块一一对应起来。请求一结束,它的块马上回到空闲池,下一个请求接着用。
问题就这么解决了:
- 没有过度预留:因为只有真要用了才分一块。
- 几乎没有碎片化:因为每块大小都一样,任何空闲块都能塞任何请求。
浪费的显存被压到接近零。
PagedAttention 是怎么共享内存的
PagedAttention 还自带一个特别漂亮的副作用——共享。这是分块带来的免费红利。
因为 KV cache 现在是由一堆小块组成的,两个不同的请求可以让自己的 block table 指向显存里同一块,而不是各存一份。一旦内容一样,这块就只存一次,大家共用。
举两个特别能体现这个好处的真实场景。
第一种:相同前缀。"前缀(prefix)"就是开头那一截。假设很多用户发来的请求都以同一段长长的系统指令开头,比如 “You are a polite customer support agent for a car dealership.”——这段开头大家都一样。有了块结构,vLLM 可以把这段共同开头的 KV cache 只存一份,然后让每个请求的 block table 都指向那几块。这种"开头复用"的细节,业界叫 prompt caching。
第二种:beam search。Beam search 是一种生成方式,模型会同时探索好几条可能的答案路径,最后保留最好的一条。这几条路径——叫 beam——共享同一个开头,只是后面才开始岔开。靠分块,所有 beam 都可以共享开头那几块,只有真正分岔的部分才各用各的块。
画出来是这样:
SHARING WITH BLOCKSshared beginning: [B1][B2] <- one copy in memory, used by all | +--------------+--------------+ | | | Request A Request B Beam C adds [B5] adds [B6] adds [B7]
B1 和 B2 装的就是大家共享的开头,只存一份。三条不同的路径都指向这两块作为它们的开头,然后各自再分自己独占的块。原本要重复存三次开头的显存,这下省下来了。
所以 PagedAttention 不光不浪费,还能让请求之间共享显存,往同一张 GPU 上塞更多用户。
Continuous batching:连续批处理
接下来聊 vLLM 的第二个大思路,它跟 PagedAttention 是配套使用的。
要懂这个,得先理解什么叫batching(批处理)。Batching 就是一次性把很多个请求放一起跑,而不是一个个排队跑。GPU 这种芯片处理一堆并行任务时效率最高,所以批处理就是让 GPU 忙起来、把吞吐拉满的常规手段。
但朴素的批处理有个大问题。
朴素方式叫 static batching(静态批处理)。做法是:攒一批请求,一起跑,必须等这一批里所有请求都跑完了,下一批才能开始。
坑就在这。不同请求生成的答案长度天差地别,可能一个用户答 20 个 token 就完事了,另一个要写 800 个 token。在静态批处理里,那个短的请求老早就结束了,结果它只能在那儿干等着批里那个最长的请求慢慢爬完——因为整批是同进同出的。这段干等的时间,那个 GPU 槽位是完全空着的,浪费了 GPU 时间。
这时候 continuous batching 就上场了。
“
Continuous batching 在每一步都会把跑完的请求踢出去、把队列里等着的新请求顶上来,而不是傻等整批跑完。
讲人话:只要有一个请求跑完了,vLLM 立刻把它扔出去,从等待队列里抓一个新请求填进那个空位。GPU 永远不会闲着等。
要记得,decode 是一个 token 一个 token 地往外吐,所以整个过程是由很多很多小步组成的。每一步 vLLM 都会检查一下:刚才有没有谁跑完了?有的话立刻把它踢掉,再补一个新人。整批永远是满载状态。
两种方式对比一下:
STATIC BATCHING (naive): the whole batch waits for the slowest onestep: 1 2 3 4 5 6 7 8Req A: X X X done - - - - <- idle, wasting the slotReq B: X X X X X X X doneCONTINUOUS BATCHING (vLLM): finished slots are refilled right awaystep: 1 2 3 4 5 6 7 8slot1: A A A C C C D D <- A finished, C jumped in, then Dslot2: B B B B B B B done
静态批处理里,A 早就跑完了但它的槽位空在那儿干等慢吞吞的 B。连续批处理里,A 一完事,C 立刻补进来;C 一完事,D 又跟上。GPU 全程在干活,一个槽位都没浪费。
Continuous batching 跟 PagedAttention 配合得天衣无缝。PagedAttention 让一个跑完的请求把显存块瞬间释放出去,continuous batching 立刻把这片释放的显存和槽位塞给下一个等待的请求。两个加一起,显存和算力都被榨到不剩。
这就是 vLLM 能让 GPU 满速干活的根本原因。
兼容 OpenAI 接口的 API 服务
聊完原理,再看看实际怎么用。
vLLM 提供一个和 OpenAI 接口兼容的 API 服务。也就是说,可以把 vLLM 当成一个监听聊天请求、返回模型回复的服务跑起来。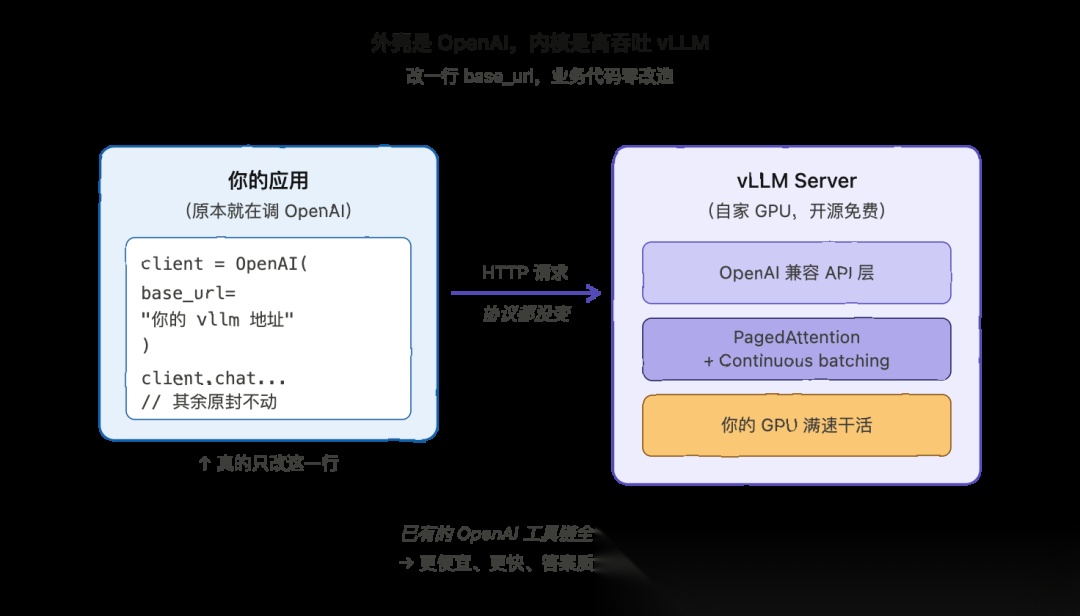
这一点意义巨大。因为业界已经有海量的工具和应用是冲着 OpenAI 的 API 写的。vLLM 既然说的是同一套"语言",那现成的工具只需要把接口地址换成自家 vLLM 的地址,一行业务代码都不用改,就能从用 OpenAI 平滑切到用自家 GPU 上跑的自家模型。
所以 vLLM 给的是:内核里是高吞吐引擎,外壳是大家最熟的那套 API。这点真的得夸一下,它让 vLLM 在真实项目里几乎是零门槛接入。
用 vLLM 能拿到哪些好处
把好处梳理一下,这些就是大家选 vLLM 的理由:
- 吞吐量大幅提升。PagedAttention 不浪费显存,continuous batching 不浪费时间。两者一叠加,每秒能服务的 token 数和用户数比朴素引擎高出好几倍甚至几十倍。
- GPU 利用率更高。无论是显存还是算力,vLLM 都能压到接近满载,把贵 GPU 的钱花到位。
- 每个请求的成本更低。同一张 GPU 既然能多扛这么多人,分摊到每个用户头上的成本就掉下来一大截。
- 接入特别简单。兼容 OpenAI API 这件事,让已有应用基本零改造就能切过来。
一句话总结:vLLM 让同一张 GPU 上能服务更多用户,速度更快,成本更低,而且答案质量分毫不变。模型还是那个模型,回答还是那些回答,vLLM 干的就是把浪费掉的显存和时间全都捡回来。
这就是 vLLM 的精髓。
vLLM 在真实世界里的应用
最后聊一下 vLLM 落地都用在哪儿。
vLLM 是目前最热门的开源 serving 引擎之一,被大量公司用来在自家 GPU 上跑开源大模型。只要需要让一个模型同时面对一大堆用户,vLLM 就是非常稳的选择。
它在两类系统里特别能打。
第一类是高并发的聊天类应用。一堆人同时在聊,continuous batching 保证每个 GPU 槽位都填满,PagedAttention 把所有人的 KV cache 塞进同一块显存里。结果就是——更少的 GPU 顶住更大的人流。
第二类是 Agent 系统。Agent 是那种能一步步推进任务、还会调一堆工具、来回好多轮才能搞定一件事的 AI 程序。Agent 在每一步都要重复发送同一段巨长的系统指令,所以 PagedAttention 的"相同前缀共享"在这里能省下海量显存;而 continuous batching 又能让这种多轮、短步骤的对话不停顿地往下滚。
总之,凡是需要把一个 LLM 高效、低成本地服务给一大群用户的场景,vLLM 都是个能帮大忙的家伙。
这就是 vLLM 的工作方式:它像操作系统管内存那样去管 KV cache——通过 PagedAttention 把显存切成小块按需发放、按需共享;通过 continuous batching 让 GPU 在每一步都被新的请求填满,一刻不闲;再用大家最熟的 OpenAI 兼容 API 把这些都包装好。换来的,就是同一块硬件上翻几倍的吞吐和翻几倍的 GPU 利用率。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)