
小白学大模型:LLaMA-Factory介绍与使用
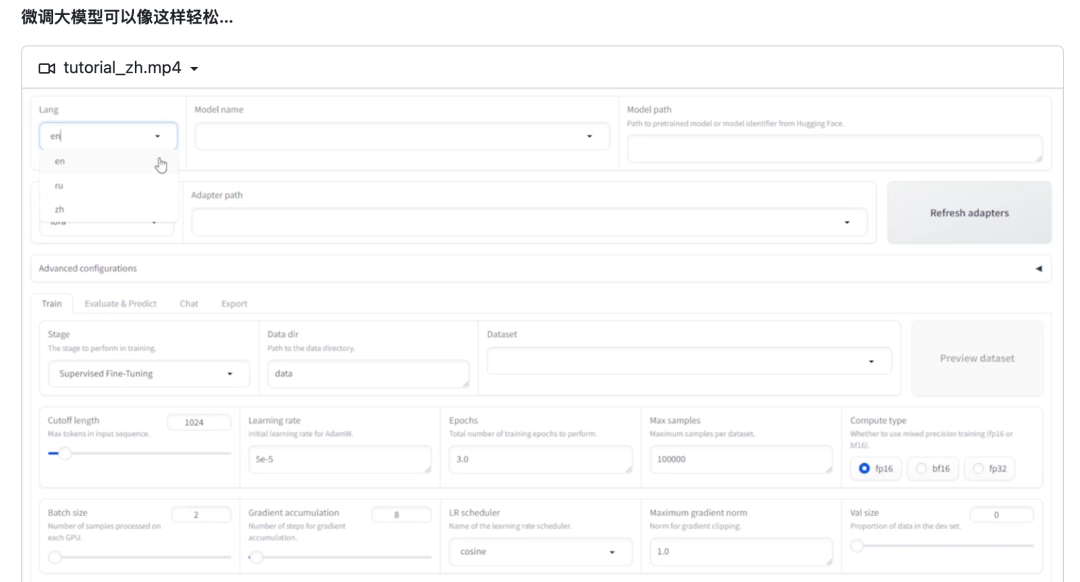
Efficient fine-tuning对于将大型语言模型(LLMs)调整到下游任务中至关重要。然而要在不同模型上实现这些方法需要付出相当大的努力。LLaMA-Factory是一个统一的框架,集成了一套先进的高效训练方法。它允许用户通过内置的Web UI灵活定制100多个LLMs的微调,而无需编写代码。
-
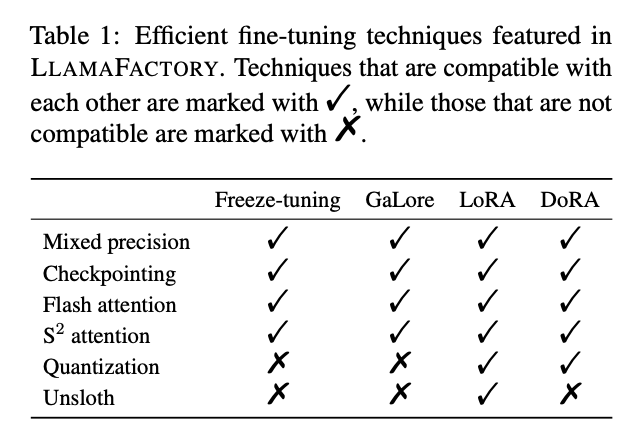
多种精度:32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调。
-
先进算法:GaLore、DoRA、LongLoRA、LLaMA Pro、LoRA+、LoftQ 和 Agent 微调。
-
实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈
LLaMA-Factory的起源
大型语言模型(LLMs)展示了卓越的推理能力,并赋予了各种应用程序以动力,随后大量的LLMs通过开源社区开发并可供使用。例如,Hugging Face的开源LLM排行榜拥有超过5,000个模型,为希望利用LLMs强大功能的个人提供了便利。
使用有限资源对极大数量的参数进行微调成为将LLM调整到下游任务的主要挑战。一个流行的解决方案是高效微调它在适应各种任务时降低了LLMs的训练成本。然而社区提出了各种高效微调LLMs的方法,缺乏一个系统的框架来将这些方法适应和统一到不同的LLMs,并为用户提供友好的界面进行定制。
为解决上述问题,LLaMA-Factory是一个LLMs微调的框架。它通过可伸缩模块统一了各种高效微调方法,实现了使用最小资源和高吞吐量微调数百个LLMs。此外,它简化了常用的训练方法,包括生成式预训练、监督微调、基于人类反馈的强化学习(RLHF)和直接偏好优化(DPO)。用户可以利用命令行或Web界面定制和微调他们的LLMs,几乎不需要编写代码。
高效微调技术
高效LLM微调技术可以分为两大类:一类侧重于优化,另一类旨在计算。高效优化技术的主要目标是在保持成本最低的同时调整LLMs的参数。另一方面,高效计算方法旨在减少LLMs中所需计算的时间或空间。
高效优化
-
冻结微调方法涉及在微调少部分解码器层的同时冻结大部分参数。
-
梯度低秩投影将梯度投影到一个低维空间中,以一种内存高效的方式进行全参数学习。
-
低秩适应(LoRA)方法冻结所有预训练权重,并在指定的层引入一对可训练的低秩矩阵。
-
当与量化结合时,这种方法被称为QLoRA,它额外降低了内存使用。
高效计算
用的技术包括混合精度训练和激活检查点。通过对注意力层的输入输出(IO)开销进行检查,Flash Attention引入了一种硬件友好的方法来增强注意力计算。S2 Attention解决了在块稀疏注意力中扩展上下文的挑战,从而减少了在微调长上下文LLMs中的内存使用。各种量化策略通过使用更低精度的权重表示减少了大型语言模型(LLMs)的内存需求。
LLaMA-Factory有效地将这些技术结合到一个统一的结构中,大大提高了LLM微调的效率。这将导致内存占用从混合精度训练中的每个参数18字节,或者bfloat16训练中的每个参数8字节,减少到仅0.6字节每个参数。
LLaMA-Factory模块划分
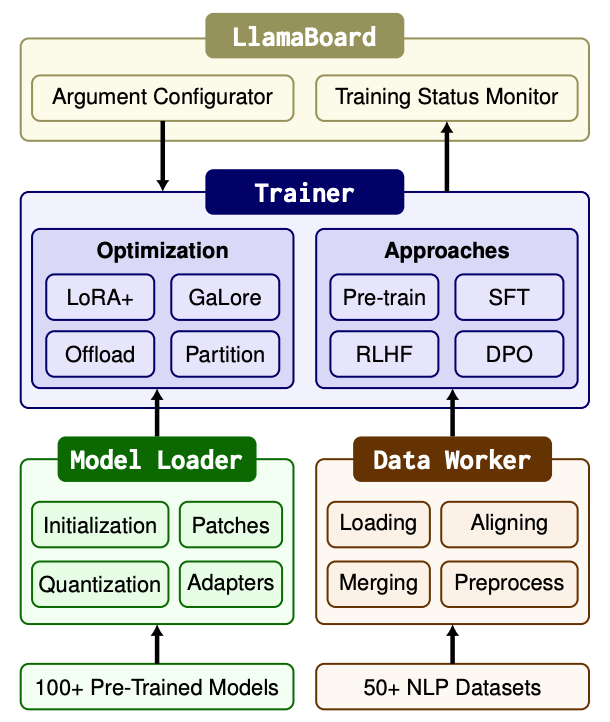
LLaMA-Factory由三个主要模块组成:模型加载器(Model Loader)、数据处理器(Data Worker)和训练器(Trainer)。
-
模型加载器准备了各种架构用于微调,支持超过100个LLMs。数据处理器通过一个设计良好的管道处理来自不同任务的数据,支持超过50个数据集。
-
训练器统一了高效微调方法,使这些模型适应不同的任务和数据集,提供了四种训练方法。
-
LLaMA Board为上述模块提供了友好的可视化界面,使用户能够以无需编写代码的方式配置和启动单个LLM微调过程,并实时监控训练状态。
LLaMA-Factory微调对比
比较了完全微调、冻结微调、GaLore、LoRA和4位QLoRA的结果。微调后,我们计算训练样本上的困惑度,以评估不同方法的效率。
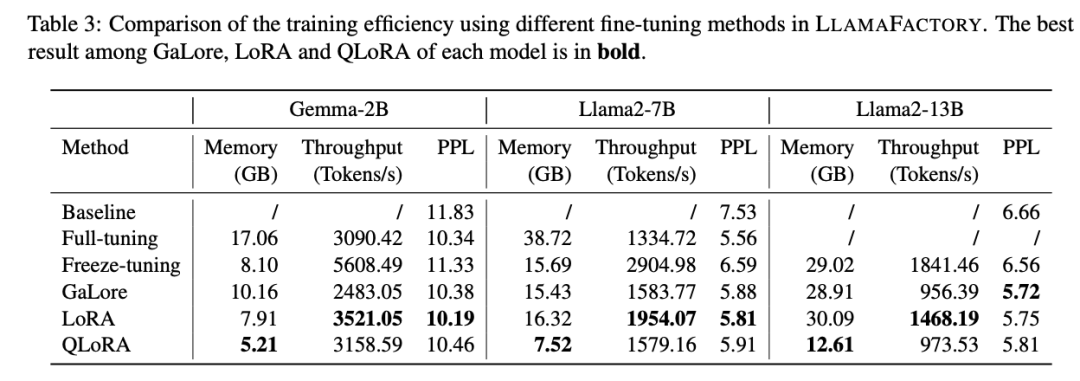
我们观察到,QLoRA始终具有最低的内存占用,因为预训练权重采用了更低的精度表示。LoRA通过Unsloth在LoRA层中的优化,实现了更高的吞吐量。
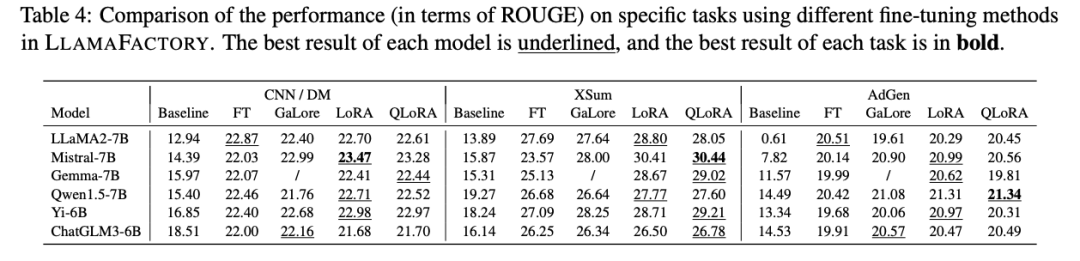
Mistral-7B模型在英文数据集上表现更好,而Qwen1.5-7B模型在中文数据集上获得了更高的分数。这些结果表明,微调模型的性能也与它们在特定语言上的固有能力相关联。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。


三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)