
白嫖48GB显存跑DeepSeek!AMD云GPU私有化部署实战
本文根据2026年6月17日晚8点我在CSDN直播“不花一分钱!用AMD免费云GPU私有化部署DeepSeek-R1实操整理,全程零成本,适合零基础读者跟着做。AMD 200小时免费算力白嫖地址:https://marketing.csdn.net/questions/Q2604140858304426315?utm_source=wubin
你有没有这样的感受?
每天用DeepSeek、ChatGPT、Kimi处理工作,越用越顺手——直到某天,你往对话框里粘贴了一份合同草稿,或者公司内部的用户数据……
停。
你有没有想过,这些数据去哪了?

一、四大痛点:调第三方AI API,你在裸奔
痛点一:数据隐私泄露风险
调用任何第三方AI API,你的输入内容都会上传到对方服务器。合同细节、客户信息、代码源文件——一旦发出去,你就失去了控制权。对于金融、医疗、法律、政务等行业,这是红线。
痛点二:成本随用量失控
个人用用还好。一旦团队推广,token消耗量爆炸式增长。按量计费的API账单,可以在一夜之间从几百变成几万。
痛点三:服务随时可能断供
还记得某些API因为政策变化突然断供的新闻吗?你的业务完全依赖对方,一旦断供,所有依赖这个API的系统立刻瘫痪。
痛点四:想练手私有化部署,却没有GPU
最现实的问题:私有化部署大模型需要显卡。一张48GB显存的专业GPU,售价动辄几万。租用云GPU,每小时的费用也需要几十元。
大多数开发者和团队,连动手试一试的机会都没有。
二、解决方案:免费领200小时AMD云GPU,自己部署DeepSeek
AMD正在推进"AI开发者计划",提供免费200小时的云GPU资源,硬件配置是:
- AMD Radeon PRO W7900
- 48GB GDDR6显存
- ROCm 7.2.1软件栈,已预装vLLM
这张卡足以流畅运行DeepSeek-R1-Distill-Qwen-14B(FP16推理仅需约28GB显存)。
今天这篇文章,就带你用这台免费的GPU,从零开始完成DeepSeek大模型的私有化部署,最终在自己的电脑上通过Cherry Studio或OpenCode与它对话——数据全程不出自己的服务器。

三、实操步骤
第一步:注册 AMD AI 开发者计划,领取免费算力
操作:
- 用电脑浏览器访问伍斌粉丝专属注册链接:marketing.csdn.net/questions/Q2604140858304426315?utm_source=wubin
- 用手机号注册登录
- 点击"AMD开发者云" → 点击"Create Template"
- 随便起一个Title,比如“my-deepseek” → Container Image选择
AMD OneClick Base (amd-oneclick-base:rocm7.2.1-py3.12-v20260416) - 点击"Create Template" → 点击右上角头像 → 点击"Profile"
- 在页面下方找到刚才创建的Template,点击右侧"Launch"按钮
- 在自动打开的新页面中,点击"Terminal"进入云端终端
⚠️ 注意:请选择 Terminal 标签,而非 Python 3(Notebook)。vLLM 是长期运行的后台服务进程,必须在 Terminal 里启动,Notebook Cell 不适合管理这类进程。
📖 概念解释:JupyterLab 是什么?
JupyterLab 是基于 Web 浏览器的交互式开发环境,AMD 云 GPU 实例默认通过它提供访问入口。你在网页里就能拿到:
- Terminal:完整的 Linux 终端,与普通 SSH 体验相同
- Notebook(.ipynb):代码+输出+图表混排的"活文档",适合逐步探索
比喻:JupyterLab 就像云端的瑞士军刀工作台——网页里就有螺丝刀(Terminal)、草稿本(Notebook)、文件柜(文件管理器),不需要额外安装任何东西。
第二步:检查系统状态与硬件参数
进入 Terminal 后,依次运行以下5条命令,确认环境正常。
命令1:查看 GPU 基本状态
rocm-smi
正常输出示例:
Device Node IDs Temp Power ... VRAM% GPU%
0 8 0x744b, 19093 27.0°C 15.0W ... 0% 0%
⚠️ 避坑:如果 Temp、Power 等字段全部显示
N/A,不要慌——这是正常现象。容器虚拟化环境下传感器权限受限,只要VRAM%和GPU%能显示数值(0%),说明 GPU 已正确挂载,可以正常使用。
命令2:确认 GPU 架构
rocminfo | grep -E "^Agent|Name:|Marketing|gfx"
实际输出示例:
Agent 1
Name: AMD EPYC 9334 32-Core Processor
Marketing Name: AMD EPYC 9334 32-Core Processor
Vendor Name: CPU
Agent 2
Name: AMD EPYC 9334 32-Core Processor
Marketing Name: AMD EPYC 9334 32-Core Processor
Vendor Name: CPU
Agent 3
Name: gfx1100
Marketing Name: AMD Radeon Graphics
Vendor Name: AMD
Name: amdgcn-amd-amdhsa--gfx1100
Name: amdgcn-amd-amdhsa--gfx11-generic
解读:
- Agent 1、2 是 CPU(EPYC 9334),Agent 3 是 GPU
- GPU 架构为
gfx1100(RDNA3),即 Radeon PRO W7900- 只有 1 个 GPU Agent,说明容器内只分配了 1 张卡
📖 背景知识:英伟达/AMD/华为的AI产品线
| 产品线 | 英伟达 | AMD | 华为 |
|---|---|---|---|
| 消费级 / 工作站级(本地推理、个人开发者、工作站) | GeForce / RTX (RTX 4090、RTX 5090等) | Radeon (RX9070 XT、AI PRO R9700、W7900等) | (暂无面向消费者和工作站的独立GPU产品线) |
| 数据中心级(云端训练、大规模推理) | H系列 (H100、H200、B200等) | Instinct (MI300X、MI350X等) | 昇腾Ascend(910C、910B、950等) |
命令3:确认容器内 GPU 数量
ls /dev/dri/renderD*
输出 /dev/dri/renderD134(数字可能不同),说明容器分配了1张 GPU。
解读:只有 1 个渲染设备节点
renderD134,确认容器只分配了 1 张 GPU。
命令4:确认 VRAM 大小
amd-smi static --vram
正常输出:
VRAM:
TYPE: GDDR6
VENDOR: SAMSUNG
SIZE: 49136 MB
BIT_WIDTH: 384
解读:
- 类型:GDDR6,三星颗粒
- 容量:49136 MB ≈ 48 GB,足以运行 DeepSeek-R1-Distill-Qwen-14B(FP16 约 28 GB)
- 总线宽度:384-bit(高带宽配置)
命令5:确认 vLLM 已预装
pip show vllm
实际输出示例:
Name: vllm
Version: 0.16.1.dev0+g89a77b108.d20260317.rocm721
Summary: A high-throughput and memory-efficient inference and serving engine for LLMs
Location: /opt/venv/lib/python3.12/site-packages
...
解读:vLLM 已预装,版本为 ROCm 7.2.1 专属构建,无需手动安装 vLLM。
📖 概念解释:VRAM(显存)是什么?
VRAM(Video RAM,显存)是GPU 上的专用内存,专门存储模型权重、KV 缓存和激活值。VRAM 容量直接决定 GPU 能运行多大的模型。
| 模型规模 | 所需VRAM(FP16) | 可跑示例 |
|---|---|---|
| 7B参数 | ~14GB | Qwen2.5-7B、Llama3-8B |
| 13-14B参数 | ~28GB | DeepSeek-R1-Distill-Qwen-14B(本文目标) |
| 32B参数 | ~64GB | 需要多卡或大显存单卡 |
| 70B参数 | ~140GB | 需要多卡集群 |
比喻:VRAM 就像厨师的操作台面积——台面越大,厨师才能同时处理越大的订单(模型权重)和越长的菜单(上下文窗口)。台面太小就只能把部分食材放回冰箱,频繁搬运导致速度大幅下降。

📖 概念解释:gfx1100 和 ROCm 是什么?
- gfx1100:AMD GPU 在 ROCm 软件栈中的架构标识符,对应 AMD RDNA 3 架构(即本文使用的 Radeon PRO W7900)。
- ROCm:AMD 推出的开源 GPU 计算平台,是英伟达 CUDA 的对标替代品,提供高度兼容 CUDA 的 HIP 编程接口。
| 维度 | 英伟达 CUDA | AMD ROCm |
|---|---|---|
| 历史 | 2006年推出,20年积累 | 2016年推出,10年历史 |
| 开放性 | 闭源 | 开源 |
| AI市场份额 | ~75-80% | ~5-7% |
| 旗舰AI芯片 | H100/B200/H200 | MI300X/MI350X |
| 生态 | 极其成熟 | 快速追赶,ROCm 7.2已达功能对等 |
比喻:CUDA 像手机市场的 iOS——性能强、生态丰富,但贵且封闭。ROCm 像 Android——开放、便宜,生态正在迅速追赶。
环境检查汇总:确认以下所有项目均通过,再继续后续步骤。
| 检查项 | 预期状态 |
|---|---|
rocm-smi 能显示 Device 0 |
✅ |
rocminfo 中出现 gfx1100 |
✅ |
/dev/dri/renderD* 存在至少一个节点 |
✅ |
| VRAM SIZE ≥ 16000 MB | ✅(实际约 49136 MB) |
pip show vllm 显示版本号 |
✅ |
第三步:设置环境变量
export PYTORCH_ROCM_ARCH="gfx1100"
export HSA_OVERRIDE_GFX_VERSION=11.0.0
export HF_ENDPOINT=https://hf-mirror.com
参数说明:
| 变量 | 作用 |
|---|---|
PYTORCH_ROCM_ARCH="gfx1100" |
告诉 PyTorch 当前 GPU 的架构型号,避免使用低效的通用内核 |
HSA_OVERRIDE_GFX_VERSION=11.0.0 |
覆盖 ROCm 对 GPU 版本的识别,gfx1100 对应版本号 11.0.0 |
HF_ENDPOINT=https://hf-mirror.com |
将 Hugging Face 下载源切换为国内镜像(hf-mirror.com),提升下载速度 |
⚠️ 避坑:这两个 ROCm 环境变量是 gfx1100 的必要配置,缺少任何一个都会导致 vLLM 无法正确识别 GPU 或性能大幅下降。
第四步:下载 DeepSeek-R1-Distill-Qwen-14B 模型
推荐使用 ModelScope(魔搭社区),国内网络直连,速度通常可达几十 MB/s:
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-14B \
--local_dir /workspace/models/DeepSeek-R1-14B
参数说明:
| 参数 | 说明 |
|---|---|
--model deepseek-ai/DeepSeek-R1-Distill-Qwen-14B |
指定要下载的模型 ID |
--local_dir /workspace/models/DeepSeek-R1-14B |
指定本地保存路径 |
下载说明:
- 模型大小约 28 GB(FP16 全精度)
- 下载期间可点击 JupyterLab 顶部
+号开新 Terminal 标签页做其他操作 - 使用 ModelScope 下载无需修复 huggingface_hub 版本,可直接启动 vLLM
⚠️ 避坑:
pip安装如果长时间无响应,加-i https://pypi.tuna.tsinghua.edu.cn/simple使用清华镜像。
📖 概念解释:ModelScope、FP16 和"蒸馏"
**ModelScope(魔搭社区)**是阿里巴巴达摩院推出的开源 AI 模型托管平台,中文界常称为"中国的 Hugging Face"。
比喻:ModelScope 和 Hugging Face 就像京东和亚马逊——亚马逊(HF)是全球老大,但从美国发货到中国有时慢;京东(ModelScope)在国内有仓库,国内用户发货快,而且很多国产模型首发在 ModelScope。
FP16(半精度浮点数):用16个二进制位存储一个浮点数,是大模型推理的行业默认格式。
| 格式 | 每参数字节数 | 14B模型大小 | 特点 |
|---|---|---|---|
| FP32 | 4字节 | ~56GB | 传统训练精度,AI推理一般不用 |
| FP16 | 2字节 | ~28GB | 推理标准,质量损失极小 |
| INT8 | 1字节 | ~14GB | 量化推理,轻微质量损失 |
| INT4 | 0.5字节 | ~7GB | 激进量化,VRAM严重不足时使用 |
**“蒸馏”(Distill)**是什么?DeepSeek-R1 原版有 6710 亿个参数,需要极其昂贵的服务器才能运行。"蒸馏"是一种知识迁移技术:让大模型(老师)去"教"一个小模型(学生),把核心推理能力传授给它。蒸馏后的 14B 版本,参数只有 140 亿,缩小了约 48 倍,单卡 48GB 显存即可流畅运行。
比喻:一位有30年经验的米其林大厨(R1 满血版),他的厨艺需要10个人的厨房团队才能支撑。蒸馏就是让大厨把最核心的几道招牌菜,亲自手把手教给一个年轻厨师(14B)。年轻厨师学到了大厨八九成的精髓,而且他一个人就能开工。
第五步:启动 vLLM 推理服务
模型下载完成后,在同一 Terminal 中运行:
PYTORCH_ROCM_ARCH="gfx1100" \
HSA_OVERRIDE_GFX_VERSION=11.0.0 \
VLLM_USE_V1=1 \
vllm serve /workspace/models/DeepSeek-R1-14B \
--max-model-len 16384 \
--gpu-memory-utilization 0.90 \
--trust-remote-code \
--port 8000 \
--served-model-name deepseek-r1-14b \
--enable-auto-tool-choice \
--tool-call-parser hermes
参数说明:
| 参数 | 说明 |
|---|---|
VLLM_USE_V1=1 |
启用 vLLM V1 引擎,性能更好 |
--max-model-len 16384 |
最大上下文长度 16K(即模型一次能"记住"的字数上限) |
--gpu-memory-utilization 0.90 |
使用 90% 的 VRAM,留 10% 余量防止内存溢出(OOM)崩溃 |
--trust-remote-code |
允许加载模型自带的自定义代码(DeepSeek 需要此选项) |
--port 8000 |
服务监听端口,使用 OpenAI 兼容 API 格式 |
--served-model-name deepseek-r1-14b |
为模型指定干净的别名,避免路径斜杠在客户端配置中引起解析问题 |
--enable-auto-tool-choice |
允许 vLLM 接受 tool_choice: auto 请求(OpenCode 等工具需要) |
--tool-call-parser hermes |
指定工具调用的解析格式;R1-14B 基于 Qwen 底座,使用 hermes 格式 |
启动成功标志: 终端出现以下内容说明服务已就绪:
INFO: Application startup complete.
⚠️ 避坑集锦:
- 不能加
VLLM_ROCM_USE_AITER=1:该参数仅对 MI300 系列(CDNA 架构)有效,在 gfx1100 上无效甚至报错,不要添加。- 不能运行 DeepSeek-R1 满血 671B 版本:满血版使用 MLA 架构,gfx1100 不支持,只能运行蒸馏版(标准 attention)。
groups: cannot find name for group ID 109:容器启动时的权限映射问题,与 GPU 使用无关,忽略即可。ImportError: huggingface-hub>=0.34.0,<1.0 is required:如果之前手动升级过huggingface_hub到 1.x,执行以下命令降回兼容版本:pip install "huggingface_hub>=0.34.0,<1.0" -i https://pypi.tuna.tsinghua.edu.cn/simple
📖 概念解释:vLLM 是什么?
vLLM 是专门用于高效推理和部署大语言模型的开源推理引擎,由 UC 伯克利于2023年推出。它让 DeepSeek 模型权重文件对外提供标准 OpenAI 兼容 API 服务,Cherry Studio、OpenCode 等客户端可以直接对接。
| 框架 | 核心优势 | 适合谁 |
|---|---|---|
| vLLM | 上手快、支持AMD ROCm、OpenAI兼容API | 大多数场景的默认选择 |
| TensorRT-LLM | NVIDIA GPU上性能最强(快10-30%) | 追求极致吞吐的生产环境 |
| Ollama | 极简安装,一条命令跑模型 | 个人学习、单用户场景 |
| llama.cpp | 纯CPU可跑,内存要求极低 | 无GPU的普通笔记本 |
比喻:如果把大语言模型比作一个才华横溢的厨师,那 vLLM 就是这家餐厅的点餐+出餐系统——负责接收无数顾客的点单(并发请求),智能排队,高效出餐(推理输出),并以标准格式上菜(OpenAI 兼容 API)。
📖 背景知识:英伟达/AMD/华为的AI算力帝国
| 城市组件 | AI 世界对应物 | 作用 |
|---|---|---|
| 最终用户 | API 调用方(Cherry Studio 、OpenCode、你的AI应用程序) | 发出请求、收取回复 |
| 快递公司 | 推理服务框架(TensorRT-LLM / vLLM / MindIE) | 把模型高效"送达"用户 |
| 汽车/运输工具 | AI 框架(PyTorch / PyTorch / MindSpore) | 装载数据和模型 |
| 道路零件如沥青钢 筋标线 |
深度学习原语库(cuDNN / MIOpen / CANN算子库) | 提供造路的基础材料和规格 |
| 交通规则 | 编程语言(CUDA / HIP / AscendCL) | 让司机能用标准指令开车 |
| 道路系统 | 底层计算平台(CUDA / ROCm / CANN) | 让程序"开车"上芯片 |
| 土地/发电站 | 硬件芯片(H100-H200-B200 / MI300X-MI350X-W7900 / Ascend910C-950) | 提供原始算力(电力) |
第六步:云端本地验证推理
新开一个 Terminal 标签页(点 JupyterLab 顶部 + 号),运行:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-r1-14b",
"messages": [{"role": "user", "content": "用中文介绍一下你自己"}],
"max_tokens": 500
}'
收到 JSON 格式的回复,说明推理服务已成功运行。
如果想在Jupyter Notebook中验证,那么可以新开一个 Python3 Notebook 标签页(点 JupyterLab 顶部 + 号),在出现的输入框中复制粘贴下面的Python脚本,然后按Shift + Enter运行(需要耐心等一会儿才能看到结果):
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="dummy" # vLLM 本地服务不需要真实 key
)
response = client.chat.completions.create(
model="deepseek-r1-14b",
messages=[{"role": "user", "content": "请解释什么是张量并行"}],
max_tokens=1000
)
print(response.choices[0].message.content)
第七步:用 ngrok 打通公网隧道
云端服务默认只在云实例内部可访问。要让本地电脑(比如Mac)连接到云端 vLLM,需要用 ngrok 打通公网隧道。
步骤1:安装 ngrok
在云Terminal终端中运行下面的命令安装ngrok:
curl -sSL https://ngrok-agent.s3.amazonaws.com/ngrok.asc \
| sudo tee /etc/apt/trusted.gpg.d/ngrok.asc >/dev/null \
&& echo "deb https://ngrok-agent.s3.amazonaws.com buster main" \
| sudo tee /etc/apt/sources.list.d/ngrok.list \
&& sudo apt update \
&& sudo apt install ngrok
⚠️ 安装过程中会出现 AMD 内部源无法解析的警告(
compute-artifactory.amd.com),这是正常现象,不影响 ngrok 安装,忽略即可。
步骤2:注册 ngrok 账号并获取 authtoken
- 打开 https://dashboard.ngrok.com/signup 注册免费账号并验证邮箱
- 登录后访问 https://dashboard.ngrok.com/get-started/your-authtoken 复制 authtoken
步骤3:配置 authtoken
ngrok config add-authtoken <YOUR_AUTHTOKEN>
将 <YOUR_AUTHTOKEN> 替换为上一步复制的实际值。
步骤4:暴露 8000 端口
ngrok http 8000
正常输出:
Session Status online
Forwarding https://xxxx.ngrok-free.app -> http://localhost:8000
记下 Forwarding 行中的 https://xxxx.ngrok-free.app URL,后续配置需要用到。
步骤5:从本地 Mac 验证公网访问
在本地电脑(如Mac)的Terminal中运行下面的命令:
curl https://xxxx.ngrok-free.app/v1/models \
-H "Authorization: Bearer no-key"
返回 JSON 且 data[].id 字段显示 "deepseek-r1-14b" 说明公网访问成功。
⚠️ 避坑:
- 报错
ERR_NGROK_4018:ngrok 自2023年12月起强制要求账号认证,直接运行ngrok http 8000会报此错,必须先配置 authtoken。- 免费版 ngrok URL 每次重启都会变化:每次重启 ngrok 后,需要同步更新客户端配置中的 URL。
📖 概念解释:ngrok 是什么?
ngrok 是一个安全隧道工具,把云端私有网络里运行的服务,通过加密隧道暴露到公网,生成临时的 HTTPS 域名,让任何地方的人都能访问。
比喻:你在云端的小黑屋里(私有网络)开了一家餐厅,但外面的人找不到门。ngrok 相当于帮你在公路边(公网)竖了一块临时路牌,标注"从这里进去可以找到你",而且这条路是加密安全的。

第八步A:配置 Cherry Studio(适合不看代码的非开发者)
Cherry Studio 是免费开源的跨平台 AI 桌面客户端(支持 Mac/Windows/Linux),适合不写代码、只需要用 AI 聊天的用户。
安装: 从 Cherry Studio 官方网站下载 macOS 版本安装包安装。
配置步骤:
- 打开 Cherry Studio,点击右上角小齿轮图标进入设置
- 点击左下方 + Add → Provider Name 填
my-deepseek-r1→ Provider Type 选OpenAI→ 点击 OK - 在配置界面填写以下信息:
| 字段 | 填写值 |
|---|---|
| API Key | no-key |
| API Host | https://xxxx.ngrok-free.app(替换为你的实际 ngrok 地址) |
- 点击 Fetch model list 右侧的 + 号 → Model ID 填
deepseek-r1-14b→ 点击 Add Model
开始对话: 在 Cherry Studio 主界面点击上方切换模型按钮,选择 deepseek-r1-14b,即可开始与私有化部署的 DeepSeek 对话。
第八步B:配置 OpenCode(适合看代码的开发者)
OpenCode 是开源的终端 AI 编程助手,运行在命令行终端,支持 75+ 大语言模型。接入私有 DeepSeek 后,代码数据完全不离开本地,隐私最高。
配置文件位置:
~/.config/opencode/opencode.json
若文件不存在,手动创建即可。
完整配置内容:
{
"$schema": "https://opencode.ai/config.json",
"model": "my-deepseek/deepseek-r1-14b",
"provider": {
"my-deepseek": {
"npm": "@ai-sdk/openai-compatible",
"name": "私有化 DeepSeek-R1-14B",
"options": {
"baseURL": "https://xxxx.ngrok-free.app/v1",
"apiKey": "no-key"
},
"models": {
"deepseek-r1-14b": {
"name": "DeepSeek-R1-14B (私有云)",
"limit": {
"context": 16384,
"output": 8192
}
}
}
}
}
}
将 baseURL 中的 https://xxxx.ngrok-free.app 替换为你的实际 ngrok URL。
参数说明:
| 字段 | 值 | 说明 |
|---|---|---|
npm |
@ai-sdk/openai-compatible |
适配任何 OpenAI 兼容协议的服务 |
baseURL |
ngrok URL + /v1 |
必须以 /v1 结尾 |
apiKey |
no-key |
vLLM 不校验 Key,填任意非空字符串 |
models 中的键 |
deepseek-r1-14b |
必须与 vLLM --served-model-name 一致 |
limit.context |
16384 |
与 vLLM --max-model-len 保持一致 |
limit.output |
8192 |
单次最大输出 token,设为窗口一半留给输入 |
注册凭证: 配置文件保存后,在 OpenCode TUI 中运行 /connect 命令,选择 Other,输入 provider ID my-deepseek,API key 填 no-key。
验证: 启动 OpenCode 后,发送 hi 进行测试,正常回复则配置成功。
⚠️ 避坑:
"auto" tool choice requires...错误:vLLM 启动命令缺少--enable-auto-tool-choice和--tool-call-parser hermes两个参数,按第五步完整命令重启 vLLM 即可。max_tokens=32000 cannot be greater than max_model_len=16384错误:OpenCode 对未知模型默认请求 32000 个 token,超出 vLLM 上限。在opencode.json的模型配置中添加"limit": {"context": 16384, "output": 8192}即可解决。
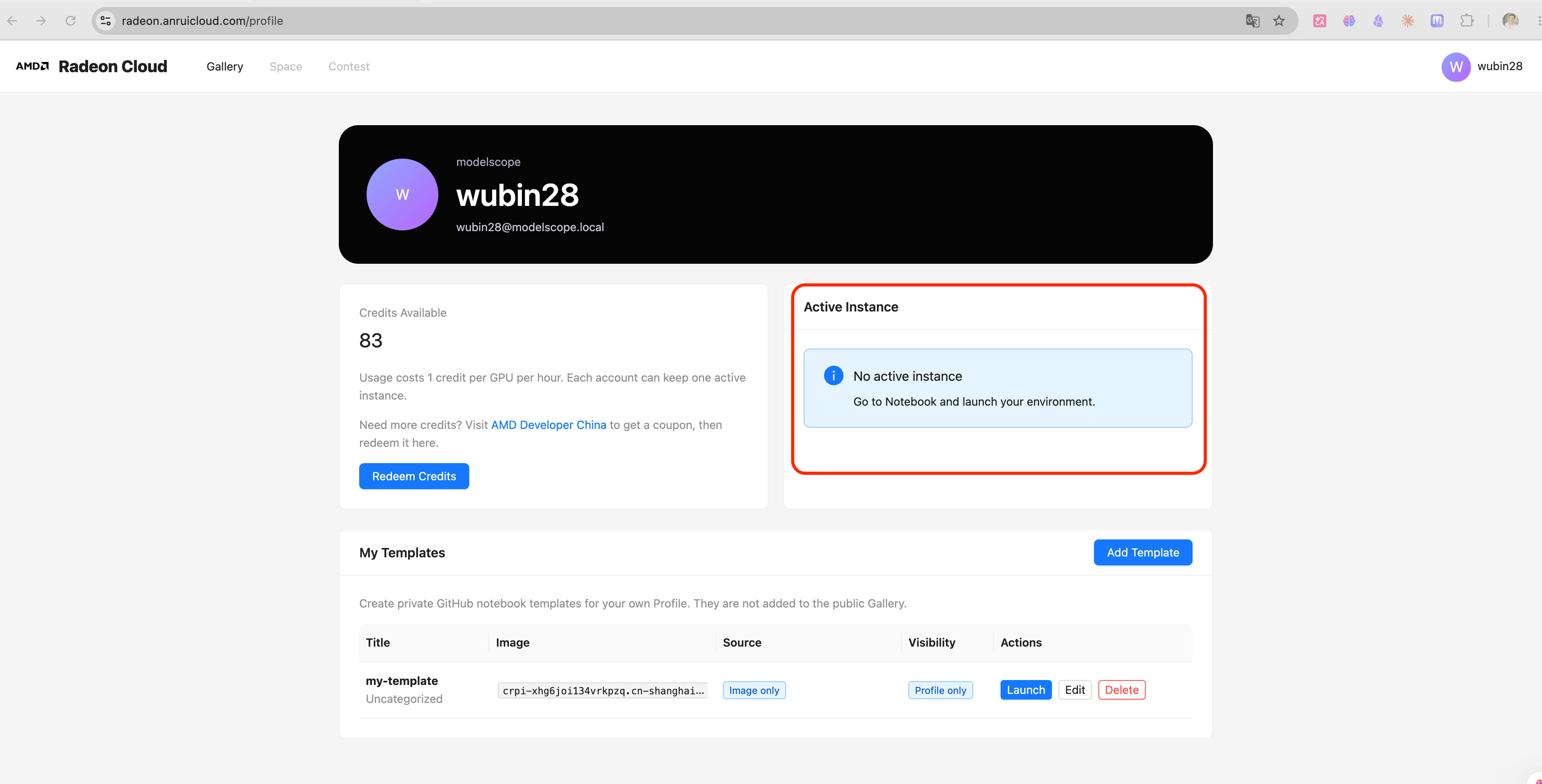
用完记得在radeon.anruicloud.com页面的右上角Profile里删实例! 否则会持续消耗你的200小时免费额度,甚至产生费用。每次实验结束不再使用云GPU后,在 Profile 里的“Active Instance”里删除实例(删完实例后,之前下载的任何软件和配置都会抹除,不过可以让AI帮你写一个脚本,把多次手工命令复制粘贴执行,变成只须执行一行命令就端到端搞定),删完后要像下图所示的那样才行。
四、总结
今天我们完成了:
✅ 注册 AMD AI 开发者计划,获取免费 48GB VRAM 云 GPU
✅ 在 JupyterLab 中检查 ROCm 环境(5条命令确认就绪)
✅ 通过 ModelScope 下载 DeepSeek-R1-Distill-Qwen-14B(约28GB)
✅ 用 vLLM 启动 OpenAI 兼容推理服务
✅ 用 ngrok 打通公网隧道,实现本地电脑访问
✅ 配置 Cherry Studio(非开发者)或 OpenCode(开发者)与私有模型对话
整个流程零硬件成本,数据全程在你自己的 GPU 上运行,不上传任何第三方服务器。
这是私有化部署的最低门槛入口。当你把这套流程跑通之后,会发现:原来私有化部署并没有那么神秘,它只是需要一张合适的 GPU、一个推理引擎,和一份耐心整理的操作手册。
如果你在操作过程中遇到问题,欢迎在评论区留言。
关注视频号"AI辅助软件开发伍斌",了解更多AI智能体应用实操步骤秘籍。

免费领 150 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)