
保姆级教程:Qwen3 模型 + LLaMA-Factory,零基础也能学会大模型微调
本文详细介绍了大模型微调技术,阐述了如何通过微调让通用模型适应垂直领域需求。文章系统讲解了微调流程、LLaMA-Factory工具的核心功能与特点,并提供了从环境搭建、数据准备到模型训练、测试的完整实战指南。LLaMA-Factory凭借其多模型兼容、可视化操作和高效训练性能,成为开发者快速实现大模型定制化的理想选择,帮助开发者以最低成本和最高效率搭建专属AI模型。
本文详细介绍了大模型微调技术,阐述了如何通过微调让通用模型适应垂直领域需求。文章系统讲解了微调流程、LLaMA-Factory工具的核心功能与特点,并提供了从环境搭建、数据准备到模型训练、测试的完整实战指南。LLaMA-Factory凭借其多模型兼容、可视化操作和高效训练性能,成为开发者快速实现大模型定制化的理想选择,帮助开发者以最低成本和最高效率搭建专属AI模型。
一、大模型微调:让通用模型适配专属场景
1、什么是模型微调?
模型微调,本质是在已完成预训练的大模型基础上,结合特定任务的标注数据进行二次训练的过程。预训练模型(如LLaMA系列、Mistral、GPT系列等)如同掌握了通用语言能力的“基础学习者”,但在面对具体场景时,仍需针对性“补课”:比如客服场景需要模型精准理解用户咨询意图并输出标准化回复,医疗问答要求模型准确识别病症术语并遵循医学逻辑,法律文书生成则需严格符合法律条文的表述规范——而微调正是通过领域数据的二次训练,让模型“吃透”专属场景的知识与规则。
2、微调的完整流程
大模型微调并非简单的“数据投喂”,而是一套包含数据、模型、训练、优化的系统化流程,核心步骤可归纳如下:
| 步骤 | 核心内容 | 关键注意事项 |
|---|---|---|
| 1、数据准备 | 收集、清洗与标注特定任务的数据集(如医疗问诊对话、法律合同片段) | 需保证数据质量,避免噪声数据;部分场景需进行数据格式转换(如适配模型输入的JSON格式) |
| 2、模型选择 | 根据任务复杂度与部署资源,挑选适配的预训练模型 | 轻量任务可选择Mistral-7B等小参数量模型,复杂任务可选用LLaMA 2-70B等大模型 |
| 3、迁移学习 | 将预训练模型与任务数据结合,启动二次训练 | 需根据模型类型选择合适的训练框架(如PyTorch、TensorFlow),确保训练过程稳定 |
| 4、参数调整 | 优化学习率(如1e-5~1e-4区间)、批量大小(Batch Size)、训练轮次(Epochs)等 | 学习率过高易导致模型“过拟合”,过低则训练效率低下 |
| 5、模型评估与迭代 | 通过准确率、BLEU值(文本生成任务)等指标测试模型效果,根据问题调整参数或补充数据 | 评估需覆盖场景内的边缘案例,避免模型仅适配“常见情况” |
3、微调相比从头训练的核心优势
对于多数开发者而言,微调相比从零开始训练模型,具备不可替代的优势:
- 资源成本更低:从头训练大模型需消耗数千GPU时的计算资源与TB级通用数据,而微调仅需GB级领域数据与数十GPU时资源,大幅降低硬件与数据采集成本。
- 落地效率更高:常规微调流程可在1-3天内完成,配合成熟工具甚至可压缩至数小时,能快速响应业务对定制化模型的需求,缩短从技术研发到实际应用的周期。
- 场景适配更准:预训练模型已具备基础语言理解能力,微调只需聚焦领域内的“差异化知识”,能更精准地捕捉专业术语、行业逻辑,避免模型在通用知识与领域知识间出现混淆。
- 泛化能力更稳:相比仅用领域数据从头训练的模型,微调后的模型既能精准处理领域任务,又能保留对“非典型场景”的适应能力(如医疗模型同时能理解患者的日常化表述)。
二、LLaMA-Factory:简化大模型微调的开源利器
LLaMA-Factory是一款面向开发者的开源大模型微调框架,其核心目标是“降低微调技术门槛”——无论是具备代码能力的算法工程师,还是缺乏编程基础的业务人员,都能通过其工具链快速完成定制化模型训练。该框架目前已支持主流LLM模型与前沿训练策略,在GitHub上累计获得数万星标,成为行业内广泛使用的微调工具之一。
 (示意图展示了LLaMA-Factory的核心模块,包括数据处理、模型加载、训练策略、监控与部署等环节,各模块可灵活组合适配不同任务)
(示意图展示了LLaMA-Factory的核心模块,包括数据处理、模型加载、训练策略、监控与部署等环节,各模块可灵活组合适配不同任务)
1、LLaMA-Factory的核心功能
LLaMA-Factory之所以能成为开发者首选,得益于其全面且实用的功能设计:
- 多模型兼容能力:覆盖当前主流开源LLM,包括LLaMA 2/3系列、Mistral、Falcon、Qwen(通义千问开源版)等,无需额外适配即可直接加载模型进行训练。
- 多样化训练策略:支持全参数微调(适合资源充足场景)、LoRA(低秩适配,资源消耗仅为全参数的1/10)、DPO(直接偏好优化,提升模型输出质量)、PPO(近端策略优化,增强模型互动性)等,开发者可根据任务需求与硬件条件灵活选择。
- 可视化操作界面:提供Llama BoardWeb UI,支持通过图形界面完成数据上传、模型选择、参数配置等操作,无需编写代码即可启动训练,降低非技术人员的使用门槛。
- 全流程监控工具:深度集成TensorBoard,可实时查看训练过程中的损失值、准确率、学习率变化等指标,方便开发者及时发现训练问题(如过拟合、训练停滞)并调整策略。
- 一键式部署支持:训练完成后,可直接通过框架内工具将模型导出为ONNX、TensorRT等格式,适配服务器部署、移动端轻量化部署等多种场景,简化“训练-落地”的衔接流程。
2、LLaMA-Factory的核心特点
除基础功能外,LLaMA-Factory的差异化特点进一步提升了其易用性与实用性:
- 极致的易用性:不仅提供Web UI,还支持通过配置文件(YAML格式)定义训练参数,开发者可直接修改参数文件快速复现不同训练方案,无需深入框架源码。
- 高效的训练性能:针对LoRA、DPO等策略进行了底层优化,相比同类框架训练速度提升20%-30%;同时支持模型并行与数据并行,可充分利用多GPU资源加速训练。
- 灵活的参数定制:除常规的学习率、批量大小外,还支持自定义dropout(防止过拟合)、权重衰减(优化模型泛化能力)、预热步数(避免训练初期参数震荡)等精细化参数,满足复杂任务的调优需求。
- 全面的多语言支持:不仅界面支持中文、英文、俄语、日语等多语言,模型训练过程中也能适配多语言数据(如同时处理中文医疗文本与英文医学文献),适配跨境业务场景。
- 丰富的生态集成:可与Hugging Face Hub(模型与数据集存储平台)、Weights & Biases(实验跟踪工具)无缝对接,方便开发者获取公开资源、记录训练实验并分享成果。
3、LLaMA-Factory的典型应用场景
凭借灵活的功能设计,LLaMA-Factory可覆盖绝大多数NLP定制化任务,常见应用场景包括:
- 文本分类任务:如电商平台的用户评论情感分析(区分正面/负面评价)、企业内部的邮件主题识别(归类工作/垃圾/营销邮件)、政务系统的公文类型分类(区分通知/报告/批复)等。
- 序列标注任务:如金融领域的实体识别(从财报中提取公司名称、营收数据、净利润等)、医疗领域的症状标注(从病历中识别病症、用药、检查项目等)、法律领域的条款标注(从合同中提取责任方、有效期、违约条款等)。
- 文本生成任务:如企业的产品说明书自动生成(根据产品参数生成标准化文档)、教育领域的个性化习题生成(根据学生知识点掌握情况生成练习题)、客服场景的智能回复生成(根据用户咨询内容输出标准化解答)、媒体领域的新闻摘要生成(将长篇报道压缩为核心摘要)。
- 机器翻译任务:如跨境电商的商品描述翻译(优化中文-英文/日文的商品文案翻译,适配目标市场语言习惯)、医疗领域的外文文献翻译(精准翻译医学术语,保留专业表述)、法律领域的合同翻译(确保条款含义无偏差,符合目标语言法律表述规范)。
- 对话交互任务:如企业的智能客服机器人(适配行业话术,精准解答用户咨询)、教育领域的答疑机器人(针对学科知识点提供详细讲解)、金融领域的理财咨询机器人(根据用户资产情况推荐理财方案,符合监管表述要求)。
三、安装 LLaMA Factory
📌 下⾯是安装 LLaMA Factory 的详细步骤。
1、准备⼯作
🔧 推荐环境配置如下:
- Python 版本 :3.9 或更⾼
- 显卡要求 :建议⾄少 A10 显卡(24G 显存)
镜像配置 :
- PyTorch 2.1.2
- CUDA 11.2(cu121)
- Ubuntu 22.04 LTS 操作系统
2、获取 LLaMA-Factory
📥 使⽤ Git 克隆项⽬代码:
gitclone--depth1https://github.com/hiyouga/LLaMA-Factory.git
3、安装依赖
📦 安装所需依赖包:
cd LLaMA-Factory
pipinstall-e".[torch,metrics]"
4、 检查版本
🔍 查看当前版本信息:
llamafactory-cliversion
----------------------------------------------------------
|WelcometoLLaMAFactory, version0.9.3.dev0
| |
|Projectpage: https://github.com/hiyouga/LLaMA-Factory |
----------------------------------------------------------
四、数据集准备
📚 LLaMA-Factory ⽀持多种格式的数据集输⼊。
1、 使⽤内置数据集
📂 默认数据⽬录为data/,你可以直接使⽤项⽬提供的⽰例数据进⾏测试。
2、⾃定义数据集准备
📄 如果你需要⾃定义数据集,请按照以下流程操作:
- 下载⽰例数据集
cdLLaMA-Factory
wgethttps://atp-modelzoo-sh.oss-cn-
shanghai.aliyuncs.com/release/tutorials/llama_factory/data.zip
unzipdata.zip-ddata
- 查看数据集结构💬 ⽰例对话格式如下:
[
2{
3"conversations": [
4{
5"from": "human",
6"value": "模仿西游记的孙悟空的语⽓和我聊天。如果你把⽔冻住,你会得到什么?"
7},
8{
9"from": "gpt",
10"value": "哈哈,这问题还难倒俺⽼孙吗?把⽔冻住就是变成冰啦!不过若是在取经的路上
⽤得着这冰来做啥,⽐如过⽕焰⼭时,那可就是解渴消暑的好东西了!你觉得呢?还有没有更有趣的问
题让俺⽼孙来解答?"
11},
12{
13"from": "human",
14"value": "那怎么做才可以把⽔冻住"
15},
16{
17"from": "gpt",
18"value": "哈哈,对俺⽼孙来说,这可是轻⽽易举的事情!只需将⽔放在凉快的地⽅,或者使⽤法⼒,⼀吹仙⽓,⽔便能迅速结冰啦!当然,在你的世界⾥,把⽔放进冰箱的冷冻室⾥等⼀阵⼦,
⽔就会变成冰块了。要是嫌慢,可以尝试⽤点⼲冰或液氮什么的,不过得⼩⼼使⽤哈!毕竟不像俺⽼孙有抗寒法⼒。"
19}
20]
21}
22]
五、模型微调
🚀 使⽤ LLaMA-Factory 进⾏模型微调⾮常⽅便,以下是完整流程。
1、 启动 Web UI
🖥 启动图形化界⾯:
lamafactory-cli webui
访问地址:http://0.0.0.0:7860
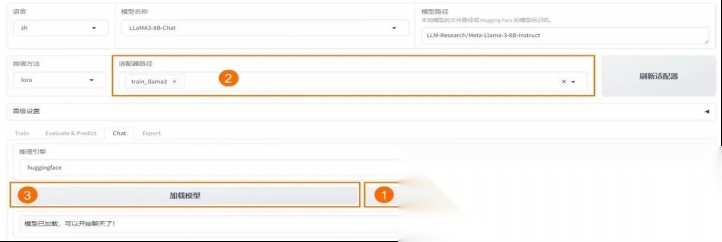
2、 配置参数
⚙ 在 Web 界⾯中设置以下关键参数: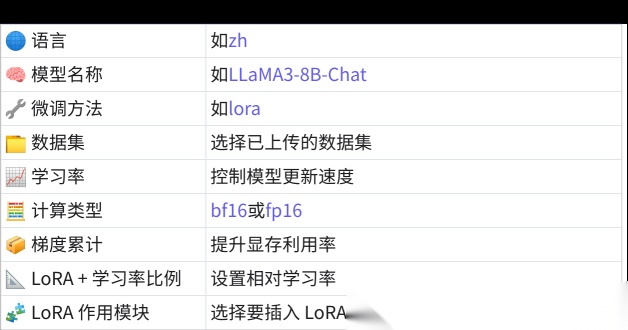
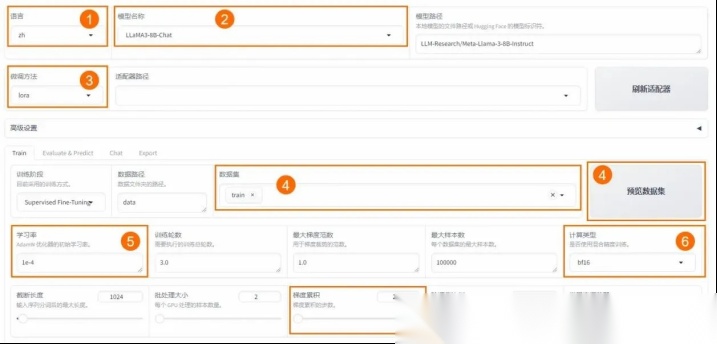
3、开始微调
⏳ 启动后等待约 20 分钟,观察损失曲线和训练进度。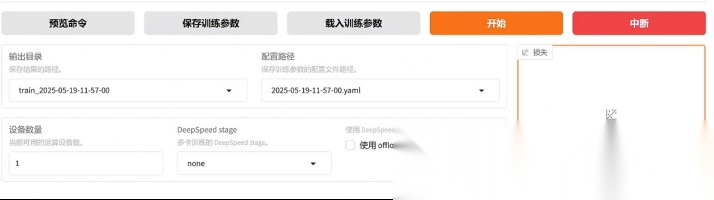 注意事项:
注意事项:
- 输出⽬录建议设为train_llama3
- 单击 “预览” 可查看完整命令
- 单击 “开始” 启动训练
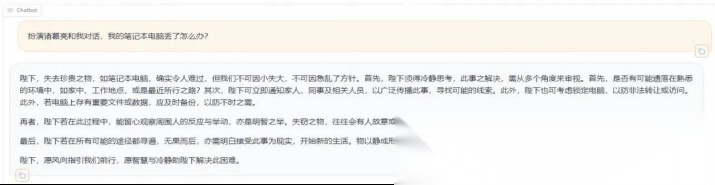
六、对话测试
🧪 微调完成后,可以通过 Web UI 进⾏对话测试。
1、 加载模型
📁 在 Chat ⻚⾯加载微调后的模型,即可开始对话。
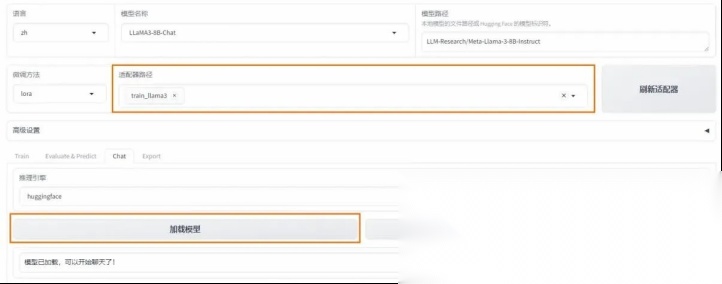
2、 输⼊测试内容
💬 在⻚⾯底部输⼊问题,点击提交即可与模型互动。
3、 切换原始模型
🔄 可随时卸载适配器,切换回原始模型进⾏对⽐测试。
 恭喜你完成了整个微调流程!你可以继续探索更多⾼级功能,如多模态训练、模型蒸馏、推理部署等。
恭喜你完成了整个微调流程!你可以继续探索更多⾼级功能,如多模态训练、模型蒸馏、推理部署等。
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!
更多推荐


 17
17 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)