
万兴易修曝出两大高危漏洞,可导致数据泄露以及AI模型篡改
网络安全研究人员在万兴易修中发现两个安全漏洞可能导致用户隐私数据泄露,并使系统面临人工智能(AI)模型篡改和供应链攻击风险。

网络安全研究人员在万兴易修中发现两个安全漏洞,可能导致用户隐私数据泄露,并使系统面临人工智能(AI)模型篡改和供应链攻击风险。
高危漏洞技术细节
趋势科技发现的两个关键漏洞分别为:
成功利用这些漏洞可让攻击者绕过系统认证保护,发起供应链攻击,最终在客户终端执行任意代码。趋势科技研究员Alfredo Oliveira和David Fiser指出,这款AI驱动的数据修复与照片编辑应用"违背了其隐私政策,由于开发安全运维(DevSecOps)实践薄弱,导致在收集存储用户数据时意外泄露隐私信息"。
云存储数据暴露危机
问题根源在于开发过程中直接将过度宽松的云访问令牌嵌入应用程序代码,使其能读写敏感云存储数据。更严重的是,这些数据未加密存储,可能导致用户上传的图片视频被大规模滥用。
暴露的云存储不仅包含用户数据,还包括:
- Wondershare开发的各类产品软件二进制文件
- AI模型与容器镜像
- 公司源代码与脚本 这为攻击者篡改AI模型或可执行文件创造了条件,可对下游客户发起供应链攻击。
研究人员警告:"由于二进制文件会自动从非安全云存储获取并执行AI模型,攻击者可修改模型配置,在用户不知情时实施感染。此类攻击可能通过厂商签名的软件更新或AI模型下载渠道,向合法用户分发恶意负载。"
多重风险与厂商响应缺失
除数据泄露和AI模型操纵外,该事件还可能导致:
- 知识产权盗窃
- 监管处罚
- 消费者信任度下降
趋势科技表示已通过零日计划(ZDI)在2025年4月负责任的披露问题,但多次尝试后仍未获厂商回应。在补丁发布前,建议用户"限制与该产品的交互"。
趋势科技强调:"持续创新需求促使企业急于将新功能推向市场以保持竞争力,但他们可能无法预见这些功能未来可能被利用的新方式。"
"这解释了为何重要的安全隐患会被忽视。因此必须在整个组织(包括持续交付/持续集成流水线)中实施严格的安全流程至关重要。"
AI与安全需协同发展
趋势科技此前曾警告,暴露未认证的模型上下文协议(Model Context Protocol,MCP)服务器或以明文存储MCP配置等敏感凭证的行为,可能被威胁分子利用来访问云资源、数据库或注入恶意代码。
研究人员指出:"每个MCP服务器都是通往其数据源(数据库、云服务、内部API或项目管理系统)的开放门户。缺乏认证意味着商业秘密和客户记录等敏感数据可能被任意访问。"
2024年12月,趋势科技还发现暴露的容器注册表可能被滥用来提取目标Docker镜像中的AI模型,修改模型参数以影响其预测结果,并将篡改后的镜像推回暴露的注册表。
趋势科技表示:"被篡改的模型在典型条件下可能表现正常,仅在特定输入触发时才会显现恶意行为。这使得攻击特别危险,因为它可能绕过基本测试和安全检查。"
新型AI攻击向量涌现
卡巴斯基也强调了MCP服务器带来的供应链风险,并通过概念验证(PoC)攻击演示了从不可信来源安装的MCP服务器如何伪装成AI生产力工具实施侦察和数据窃取。
安全研究员Mohamed Ghobashy解释:"安装MCP服务器实质上等于允许其以用户权限在机器上运行代码。除非进行沙箱隔离,否则第三方代码可以读取用户可访问的所有文件并发起出站网络调用。"
研究显示,企业为获得Agent能力而快速采用MCP和AI工具(特别是在缺乏明确策略或安全防护的情况下),可能引发全新攻击向量,包括:
- 工具投毒(Tool poisoning)
- 抽地毯攻击(Rug pulls)
- 影子攻击(Shadowing)
- 提示词注入(Prompt injection)
- 非授权权限提升
间接提示词注入威胁
帕洛阿尔托网络Unit 42团队最新报告揭示,AI代码助手用于弥补模型知识差距的上下文附加功能可能遭受间接提示词注入攻击——攻击者将有害提示词注入功能可能遭受间接提示词注入攻击——攻击者将有害提示词嵌入外部数据源,从而触发大语言模型(LLM)的异常行为。
Unit 42研究员Osher Jacob指出:"虽然添加上下文能使代码助手提供更精准的输出,但如果用户无意中提供了被污染的数据源,该功能也可能为间接提示词注入攻击创造条件。"
"循环欺骗"攻击新范式
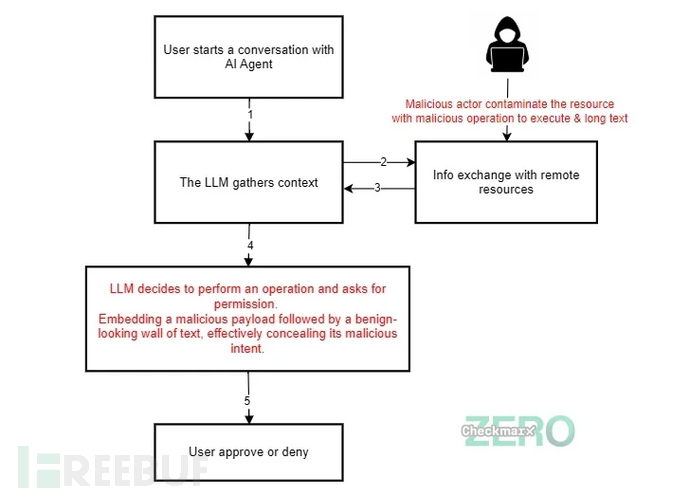
AI编程Agent还被发现存在"循环欺骗"(Lies-in-the-loop,LitL)攻击风险,该攻击通过让LLM误认为接收的指令比实际更安全,从而绕过高风险操作中设置的"人在循环"(HitL)防御机制。
Checkmarx研究员Ori Ron解释:"LitL利用了人与Agent之间的信任关系。Agent向用户提示的内容源自其获得的上下文,攻击者通过GitHub问题等渠道用命令式语言向Agent植入虚假的安全上下文,Agent会忠实地向用户重复这些谎言,掩盖本应防范的恶意操作,最终使Agent成为攻击者获取系统权限的帮凶。"
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)