
打造企业智慧知识库:我对RAG与智能体协同的大模型应用架构思考
本文系统探讨了企业级RAG(检索增强生成)系统的实践路径与演进方向。从NaiveRAG到AgenticRAG的架构演进,详细解析了包括数据工程、文档处理、向量检索、内容生成等关键环节的技术实现。重点阐述了模块化设计思想,通过将系统拆分为索引构建、预检索、检索后处理等可独立优化的功能模块,构建灵活可扩展的RAG工作流。文章指出未来RAG技术将向多模态支持、自学习能力和知识推理等方向发展,强调企业落地
当企业知识沉睡于数据孤岛,大模型却在幻觉中徘徊。RAG不只是技术,更是打通知识与智能的关键桥梁。
本文分享企业级RAG系统实践经验,从三个方面展开:实践流程架构及特点、理论依据、实践总结与展望。通过从Naive RAG到Agentic RAG的演进路径,探索如何构建真正赋能企业的知识型AI应用。
RAG实践流程架构
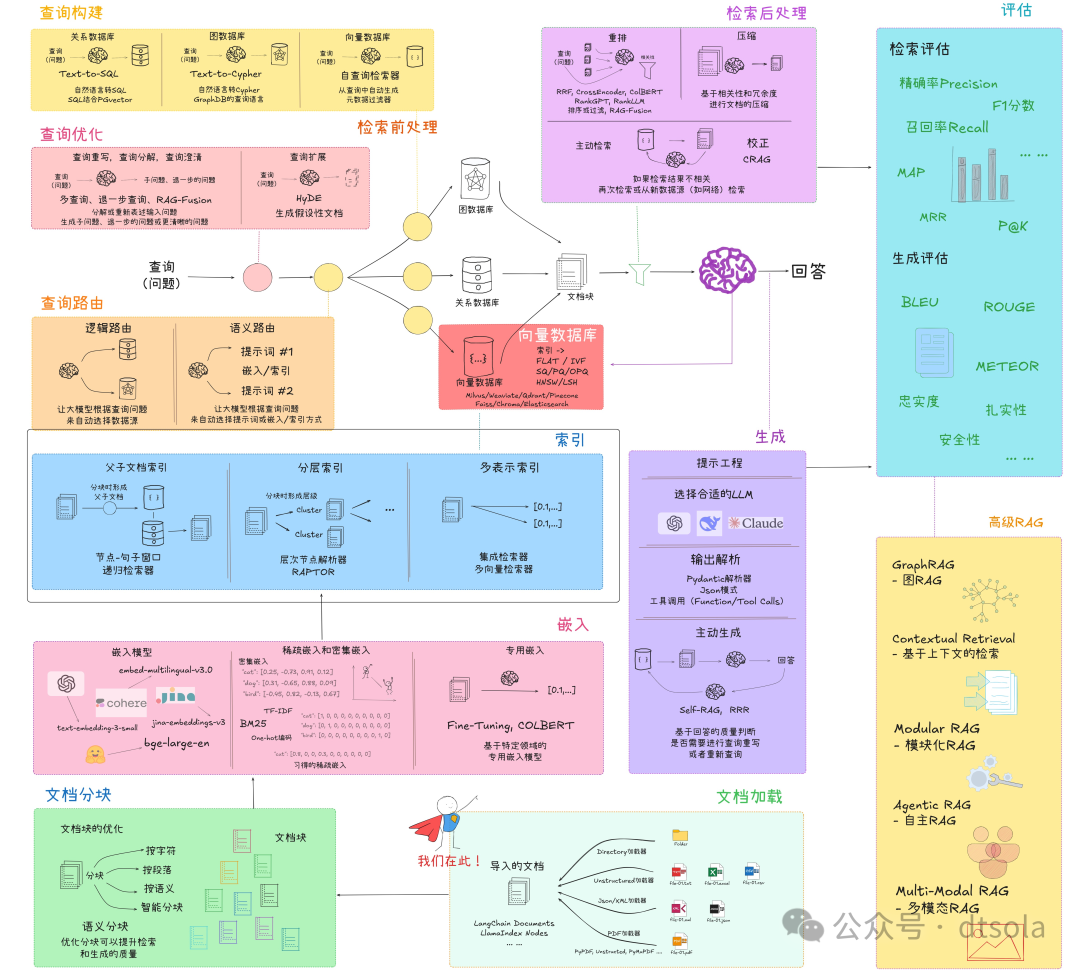
1. 数据工程
文档加载
数据是RAG系统的基础,高质量的数据加载流程至关重要:
- 多源数据支持:企业数据分散在不同格式中,需支持TXT、MD、PPT、PDF、Word、Excel、图片、网页等多种格式
- 数据清洗策略:
-
- 结构化清洗:表格数据规范化、列名标准化
- 非结构化清洗:去除特殊字符、HTML标签、冗余信息
- 语言标准化:统一编码、处理多语言文档
- 元数据提取:自动提取文档创建时间、作者、版本等关键元数据,便于后续检索和溯源
- 增量更新机制:建立文档变更检测机制,只处理变更部分,提高系统效率
文档分块
分块质量直接影响检索精度和生成质量:
- 字符分块:按固定字符数量切分,简单但可能破坏语义完整性
- 段落分块:按自然段落切分,保持基本语义单元
- 语义分块:基于语义边界智能切分,保证每个块的语义完整性
- 智能分块:
-
- 递归分块:大块先分,再细分
- 滑动窗口:保证上下文连贯性
- 重叠分块:相邻块保留一定重叠,避免信息丢失
- 分块粒度自适应:根据文档类型和内容复杂度动态调整分块大小
2. 文档嵌入
嵌入模型选型
- 通用嵌入模型:
-
- BGE-M3:多语言支持强,中文表现优异
- text-embedding-3-small:OpenAI小型嵌入模型,性能与成本平衡
- text-embedding-3-large:高精度需求场景
- GTE-large:开源模型中表现优异
- E5-large-v2:微软开源模型,英文表现突出
- 模型选择考量因素:
-
- 语言支持:中英文或多语言需求
- 维度大小:低维(384)到高维(1536)权衡
- 推理速度:生产环境吞吐量要求
- 部署成本:云服务或本地部署成本
嵌入方式及算法
- 密集嵌入(Dense Embedding):
-
- 优势:捕捉语义相似性,处理同义词
- 代表:Transformer类模型生成的向量
- 稀疏嵌入(Sparse Embedding):
-
- 优势:精确匹配关键词,处理专业术语
- 算法:TF-IDF、BM25
- 混合嵌入(Hybrid Embedding):
-
- 密集+稀疏结合,兼顾语义和关键词匹配
- 实现方式:ColBERT、SPLADE等
专用领域嵌入模型微调
- 领域适应微调:
-
- 对比学习:构建领域内正负样本对
- 蒸馏学习:从大模型蒸馏领域知识
- 微调数据构建:
-
- 领域问答对:构建专业领域QA对
- 相似度标注:人工标注文档相似度
- 评估指标:
-
- 检索准确率:P@k, R@k, MRR
- 相似度一致性:与人工判断的一致性
3. 文档索引建立
父子文档索引
- 节点-句子窗口递归索引器:
-
- 构建文档层次结构,从章节到段落到句子
- 优势:保留文档结构信息,支持多粒度检索
- 实现:存储父子关系,检索时可回溯上下文
分层索引
- 层次节点解析器(RAPTOR):
-
- 按语义层次构建索引树
- 检索时先定位大块,再精确定位小块
- 优势:提高检索效率,降低计算成本
多表示索引
- 多视角表示:
-
- 同一文档使用不同嵌入模型表示
- 不同粒度的文档块并行索引
- 优势:提高检索鲁棒性,应对多样化查询
4. 向量数据库
数据库选型
- 开源自部署选项:
-
- Milvus:分布式架构,高吞吐量,企业级支持
- Weaviate:模块化设计,支持多模态
- Qdrant:Rust实现,性能优异,过滤功能强大
- Chroma:轻量级,Python原生支持,快速原型
- FAISS:Meta开源,专注高性能向量检索
- 云服务选项:
-
- Pinecone:全托管,零运维,按需扩展
- ElasticSearch/OpenSearch:成熟生态,全文检索+向量能力
- 选型考量因素:
-
- 数据规模:百万级、亿级、百亿级
- 查询QPS:高并发需求
- 元数据过滤:结构化数据过滤能力
- 运维成本:自建vs云服务
- 集成难度:与现有系统兼容性
索引算法选型
- 精确检索:
-
- FLAT:暴力计算,精确但计算量大
- 近似检索:
-
- IVF:倒排索引,空间分区
- HNSW:层次化小世界图,高效近似检索
- LSH:局部敏感哈希,适合超大规模数据
- 量化算法:
-
- SQ:标量量化,简单压缩
- PQ/OPQ:乘积量化/优化乘积量化,大幅降低存储
- 选型考量:
-
- 精度vs速度:召回率与查询时间权衡
- 内存消耗:有限资源环境考量
- 构建时间:索引创建和更新效率
5. 检索前处理
查询构建
- text2sql:
-
- 将自然语言转换为SQL查询关系型数据库
- 实现:基于LLM的SQL生成,结合模板和约束
- text2cypher:
-
- 将自然语言转换为Cypher查询图数据库
- 应用:知识图谱查询,关系推理
- 自查询检索器:
-
- 自动构建向量数据库过滤条件
- 元数据过滤:时间范围、文档类型、部门等
- 混合查询:向量相似度+结构化条件
查询优化
- 查询重写:
-
- 多查询生成:一个问题生成多个变体查询
- 退一步查询:简化复杂查询,提高召回率
- RAG-Fusion:多查询结果融合排序
- 查询分解:
-
- 复杂问题拆分为多个简单子问题
- 子问题独立检索后结果合并
- 查询澄清:
-
- 模糊问题生成澄清性子问题
- 交互式引导用户明确意图
- 查询扩展:
-
- HyDE(Hypothetical Document Embeddings):
-
-
- 先用LLM生成假设性文档
- 对假设文档而非原始查询进行编码
- 提高复杂问题的检索效果
-
查询路由
- 逻辑路由:
-
- 基于问题类型选择合适数据源
- 实现:规则引擎或LLM判断
- 语义路由:
-
- 动态选择最佳嵌入模型和索引方式
- 根据问题特征选择检索策略
- 工具调用:
-
- 判断是否需要调用外部工具
- 工具选择:计算器、API调用、代码执行器等
6. 检索后处理
重排
- 基础重排算法:
-
- RRF(Reciprocal Rank Fusion):多源检索结果融合
- CrossEncoder:对<查询,文档>对重新评分
- 高级重排方法:
-
- ColBEAR:细粒度token级别相关性计算
- RankerGPT/RankLLM:利用大模型进行相关性判断
- 融合策略:
-
- RAG-Fusion:多查询结果的排序融合
- 加权融合:不同来源结果的权重分配
压缩
- 相关性压缩:
-
- 保留高相关段落,删除低相关内容
- 基于相似度阈值过滤
- 冗余度压缩:
-
- 检测并合并语义重复内容
- 实现:聚类或相似度矩阵计算
- 上下文优化:
-
- 智能截取关键上下文
- 保持信息密度最大化
CRAG(Corrective RAG)
- 主动检索校正:
-
- 初步检索结果评估
- 不满足时触发再次检索
- 多源检索:
-
- 内部知识库检索失败时
- 转向外部数据源(如网络)检索
- 反馈循环:
-
- 基于检索结果质量调整策略
- 动态优化检索参数
7. 内容生成
提示词工程
- 结构化提示模板:
-
- 角色定义:明确LLM应扮演的角色
- 任务说明:清晰定义输出要求
- 格式约束:指定输出格式
- 上下文增强:
-
- 检索结果组织:重要信息优先
- 引用标记:便于溯源
- 指令分离:区分检索内容和生成指令
- 思维链(CoT):
-
- 引导模型逐步推理
- 提高复杂问题解答质量
LLM选型
- 商业模型:
-
- GPT-4/GPT-4o:综合能力强,成本较高
- Claude 3.5 Sonnet:推理能力出色,长文本处理优异
- GPT-3.5-Turbo:性价比高,适合一般场景
- 开源模型:
-
- DeepSeek:中英双语能力强
- Qwen2:阿里开源,中文优势明显
- Llama 3:Meta开源,社区支持广泛
- Mistral:小参数量高性能
- 选型考量因素:
-
- 语言能力:中文/英文/多语言
- 推理能力:逻辑性、一致性
- 部署环境:云API/本地部署
- 成本控制:API调用成本/硬件投入
- 上下文窗口:8K/16K/32K/128K
输出解析
- 文本格式化:
-
- 结构化段落
- 重点突出
- 逻辑组织
- JSON输出:
-
- 结构化数据返回
- 便于前端渲染和处理
- 格式校验和纠正
- Markdown渲染:
-
- 富文本展示
- 表格、列表等高级格式
- 代码块语法高亮
工具调用
- Function/Tool Calls:
-
- 模型判断并调用外部函数
- 数据查询、计算、API调用等
- MCP(Multi-modal Conversational Prompting):
-
- 多模态交互
- 图表生成、数据可视化
专用领域生成模型微调
- 指令微调:
-
- 构建领域指令数据集
- LoRA/QLoRA低参数微调
- RAG增强微调:
-
- 结合检索结果进行微调
- 提高领域知识准确性
- RLHF/DPO:
-
- 基于人类反馈的强化学习
- 直接偏好优化
主动生成
- Self-RAG:
-
- 模型自评估生成内容质量
- 不满足时触发重新检索
- RRR(Retrieve, Rerank, Rewrite):
-
- 检索、重排、重写三步流程
- 迭代优化生成质量
8. 评估
检索评估
- 精确率(Precision):
-
- 检索结果中相关文档的比例
- P@k:前k个结果中的精确率
- 召回率(Recall):
-
- 相关文档被成功检索的比例
- 衡量检索系统的覆盖能力
- F1分数:
-
- 精确率和召回率的调和平均
- 综合评估检索效果
- MRR(Mean Reciprocal Rank):
-
- 首个相关结果排名的倒数平均
- 评估排序质量
生成评估
- 自动评估指标:
-
- BLEU/ROUGE:基于n-gram的文本相似度
- METEOR:考虑同义词的评估指标
- BERTScore:基于语义的评估
- 安全性评估:
-
- 幻觉检测:验证生成内容与事实一致性
- 有害内容过滤:确保输出符合安全标准
- 人工评估:
-
- 专家评审:领域专家质量评估
- A/B测试:不同系统对比测试
- 业务指标:
-
- 用户满意度:NPS/CSAT
- 解决率:问题一次性解决比例
- 效率提升:与传统方式对比的时间节省
实践流程理论依据
Navie RAG
架构
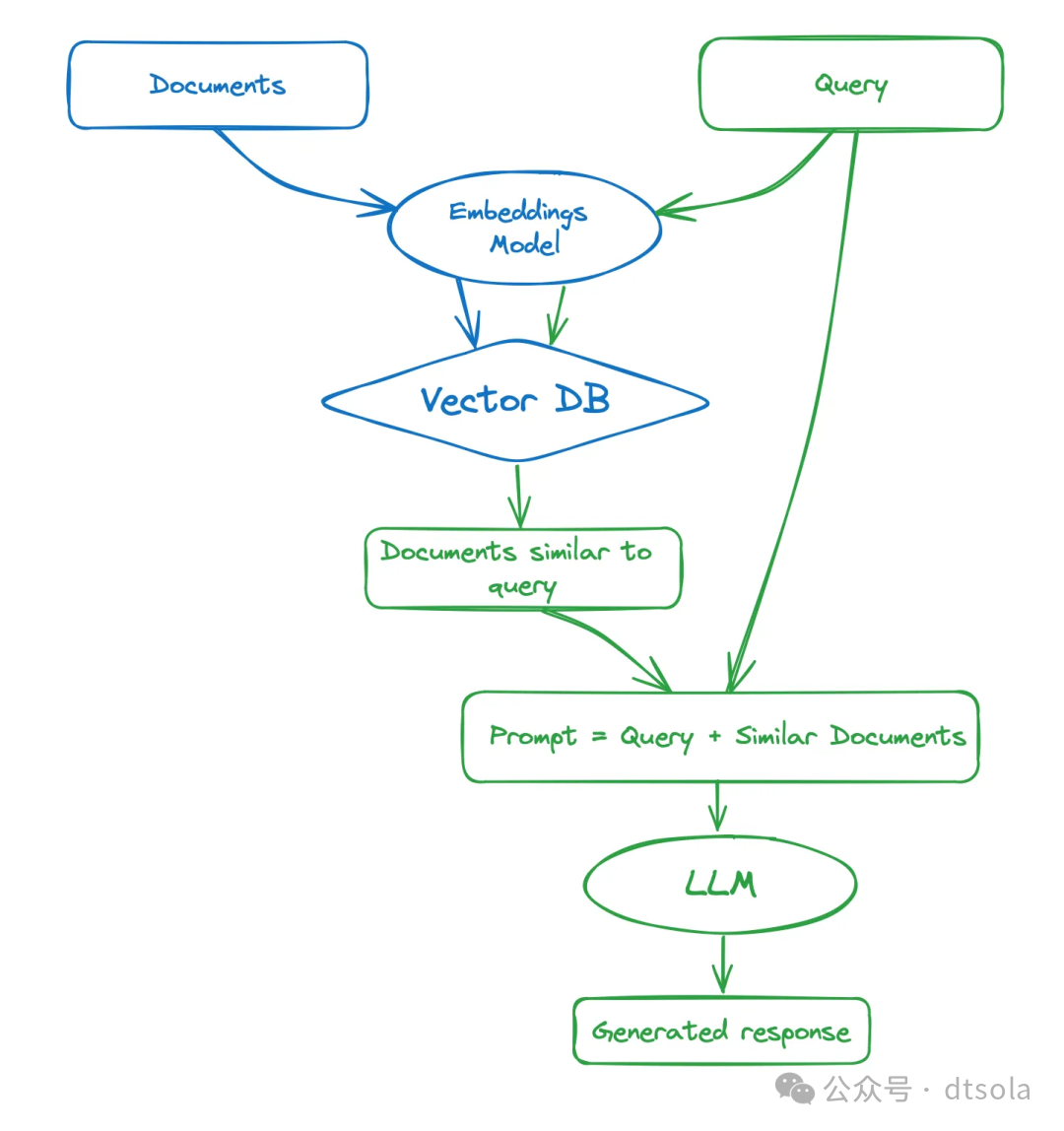
流程
1、索引构建(离线)
- 数据加载:从各个来源整合数据。
- 文档切块:按照一定策略切块文档,如固定大小,语义分块等。
- 向量化与存储:使用Embedding模型(bge系列等)将文档转换成向量,将向量即文档信息存储到向量数据库(腾讯云,Milvus,Faiss)等。
2、在线检索(在线)
- 检索:使用相同Embedding模型转换用户输入,并从向量数据库检索相似TopK文档(余弦相似度或者欧氏距离)。
- 生成:将用户输入与检索到的toK文档组织成Prompt,输入LLM生成回答。
Advanced RAG
架构
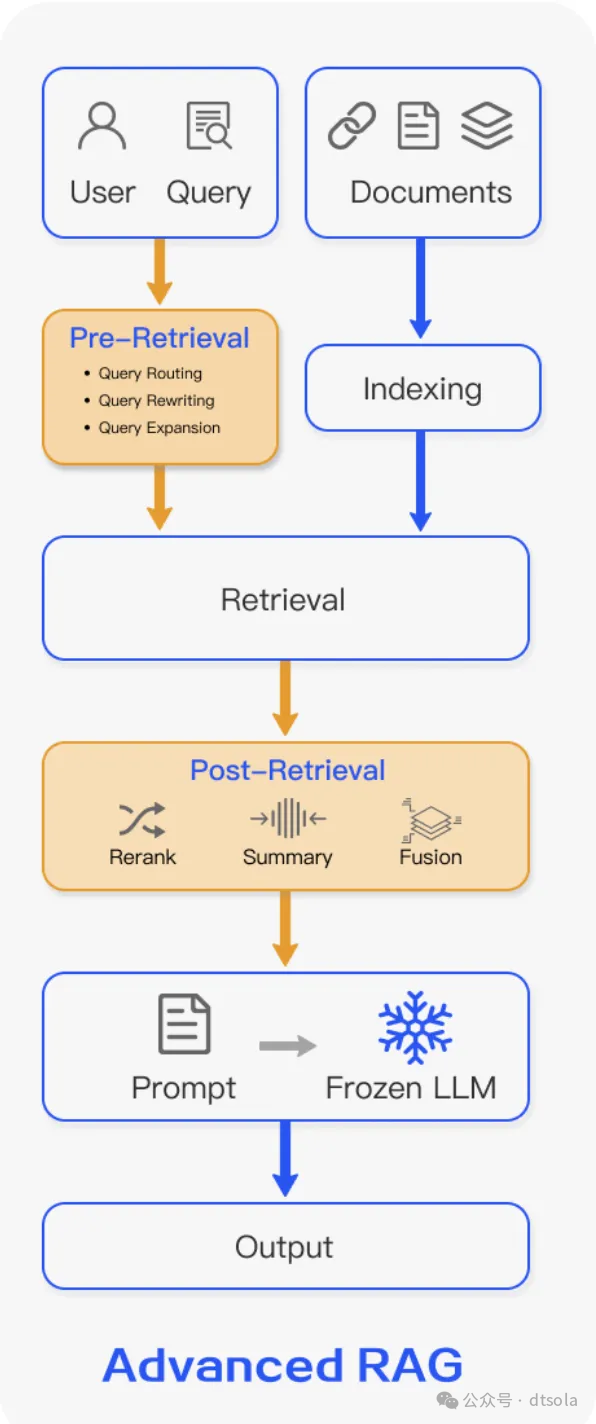
流程
基于Navie Rag增加两个步骤,包含5个阶段:Indexing -> Pre Retrieval -> Retrievel -> Post Retrievel -> Generation,旨在解决文档召回的质量和准确率。Navie RAG属于Advanced Rag的一个特化,即Pre Retrievel和Post Retrievel为空。
1、Pre-Retrieval
预检索处理: 侧重数据索引优化。
- 索引数据优化
-
- 增强数据密度:如利用LLM清洗冗余信息,元数据增强(条件过滤等)。
- 增强索引语义: 如预生成chunk快的假设性问题,提升检索对称性,建立如关键词搜索(BM25),向量检索或图数据库。尝试多种chunk分块策略(固定大小,递归,语义分块)。
- Embeddings模型优化: 针对特定领域数据对模型进行微调,提升语义匹配精度。
- Query增强
-
- Query translation: query转换,用于用户的不确定性,用户可能会输入模糊表达,或query与index文档不在一个语义空间,或query过于复杂的情况,因此需要query转换。如query-rewrite,query-expansion等。
- Query enhancement: query增强,增强或者扩大用户输入的query语义,如: HyDE(假设文档增强),Step-Back Prompting(回退一步prompt)。
- Query decomposition: query分解,把用户的复杂query分解成多个可管理的子问题,引导模型逐步解决各个子问题。如Answer Recursively(递归回答,迭代),Answer Individually(独立回答,分解后并行回答)。
2、Post-Retrievel
后检索处理: 侧重数据结果的二次加工&过滤
- 重排序Rerank
对检索出的文档做更精细的评估,将真正最匹配意图的文档排列到前面,尽可能减少噪声
- 上下文压缩Prompt Compression
若检索出大量文档,在输送给LLM之前可能还需要对文档做裁切,仅保留最关键核心的内容
Modular RAG ☆(核心依据)
架构
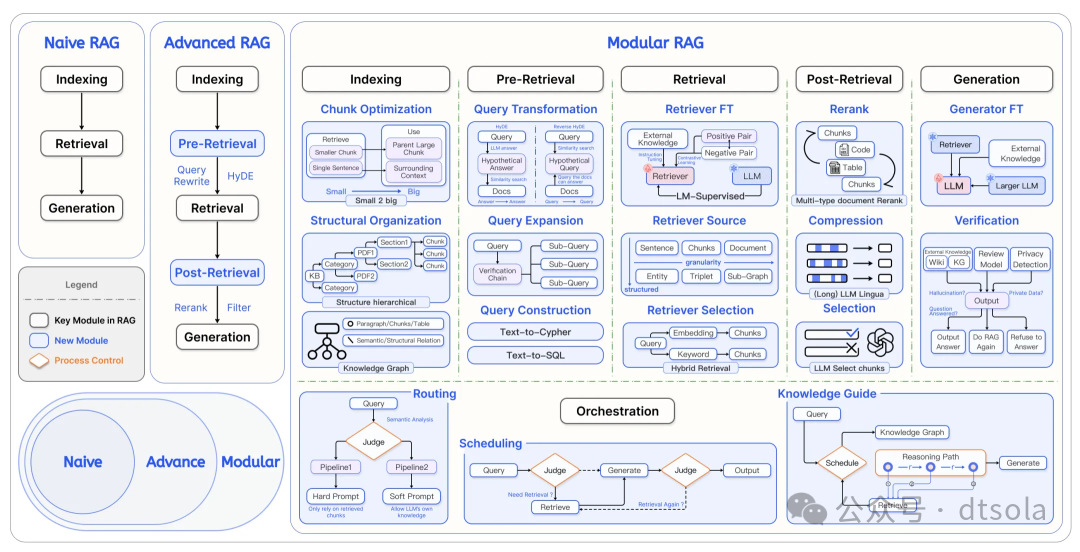
流程
模块化RAG,将 RAG 系统分为 Module Type、Module 和 Operators 三层结构。每个 Module Type 代表 RAG 系统中的一个核心流程,包含多个功能模块。通过整个 RAG 系统变成了多个模块和序列排列组合,形成 RAG 工作流。整体有7个部分:Indexing, Pre Retrieval, Retrievel, Post Retrievel, Memory, Generation, Orchestration. 这种范式在基于Advanced RAG的横向架构上引入了纵向的结构,即Module和Operators。
Agentic RAG
架构
Single-Agent Agentic RAG
该框架核心是一个系统决策中心的Router Agent,该Agent动态处理信息检索,集成操作,比较适用于多检索源的简单问答场景。
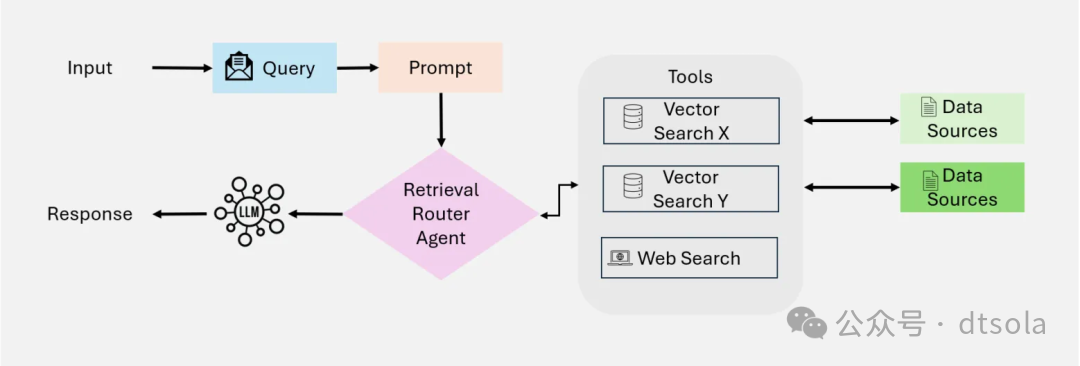
Multi-Agent Agentic RAG
为Single-Agent Agentic RAG架构的演进版本,用多个专用代理来细化更复杂的工作流和不同的查询类型。核心Router Agent下又挂接了多个检索Agent, 如Agent1用于查询结构化数据(Mysql),Agent2用于查询非结构化数据,Agent3用于Web查询或专用API查询等。
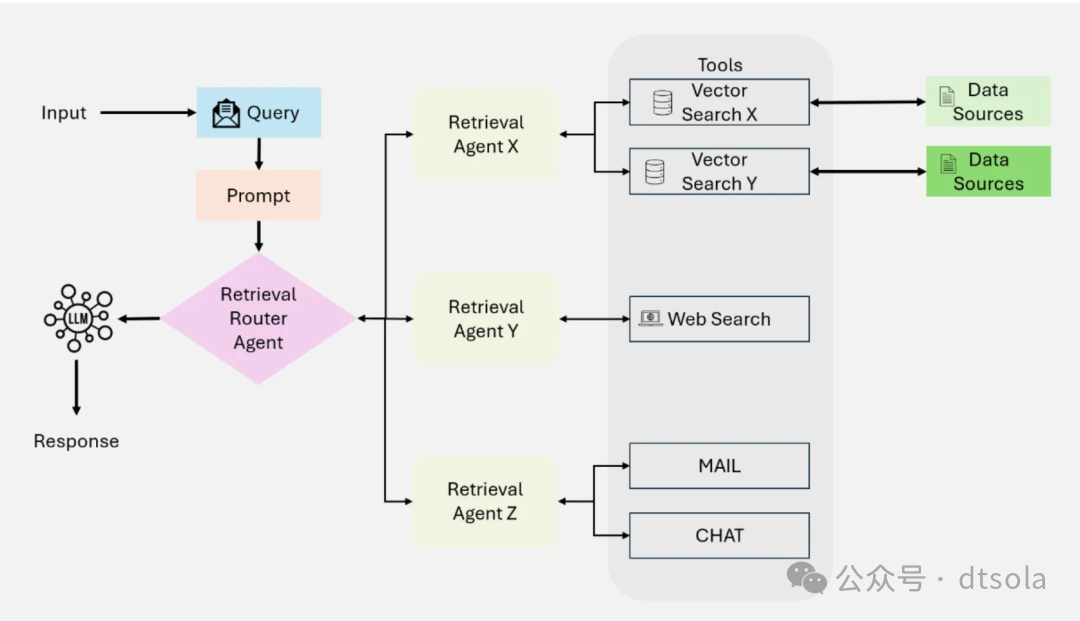
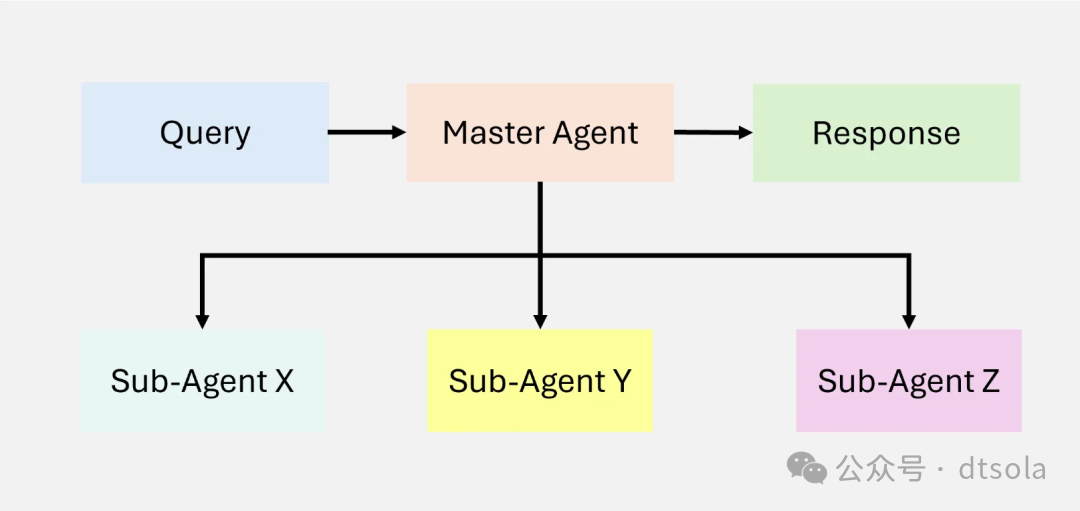
Hierarchical Agentic RAG
分层代理RAG,为Multi-Agent Agentic RAG架构的拓展,将整个系统分为多个层级的Agent,由顶级Agent驱动子Agent,并聚合子Agent的结果。
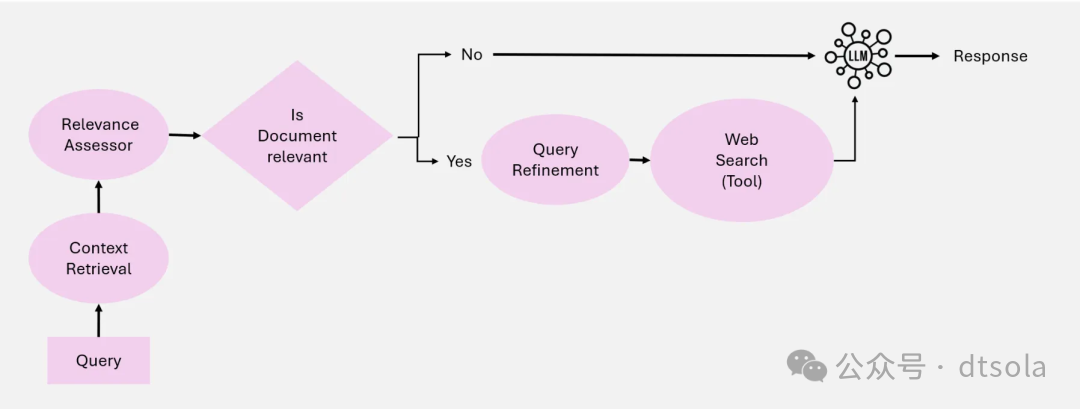
Agentic Corrective RAG
Corrective RAG的核心是他可以动态评估检索到的文档并纠正查询,提升检索文档的质量。
Agentic Corrective RAG系统建立在5个关键Agent上。
- Context Retrieval Agent: 负责从数据库中检索相关上下文。
- Relevance Evaluation Agent: 负责评估检索到的文档的相关性,并标记出不相关或不明确文档并采取纠正措施。
- Query Refinement Agent: 重写query增强检索的Agent。
- External Knowledge Retrieval Agent: 当Context Retrieval Agent检索的上下文不足时,从其他备用数据源检索数据(如Web 检索)。
- Response Synthesis Agent: 组织响应Agent。
Adaptive Agentic RAG
自适应Agent RAG, 与上述Modular RAG中的Adaptive retrieval一样,语义上都是在各个环节引入了LLM判断,并在引入LLM评测实现Loop自迭代。
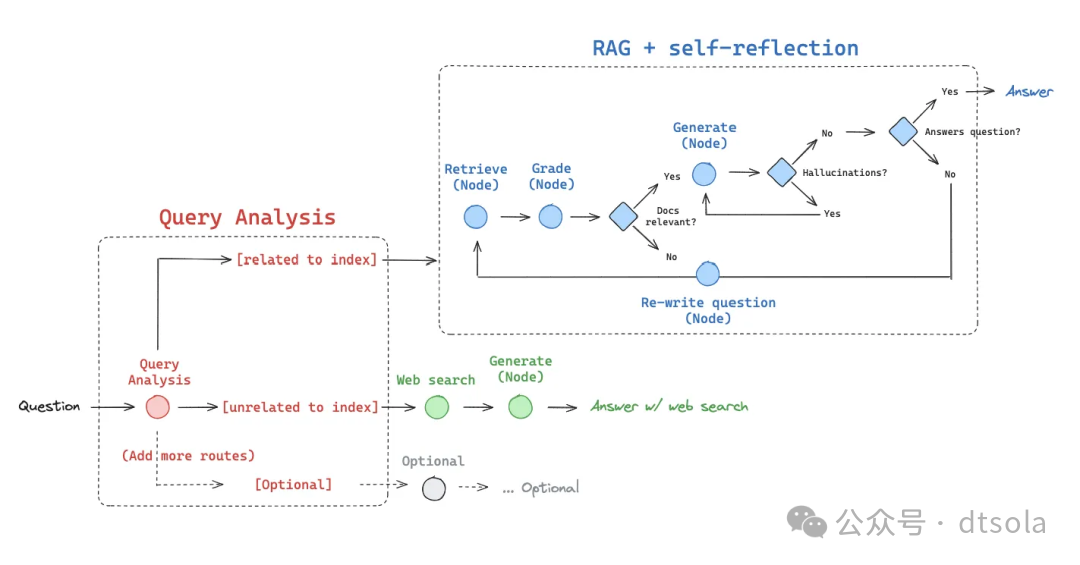
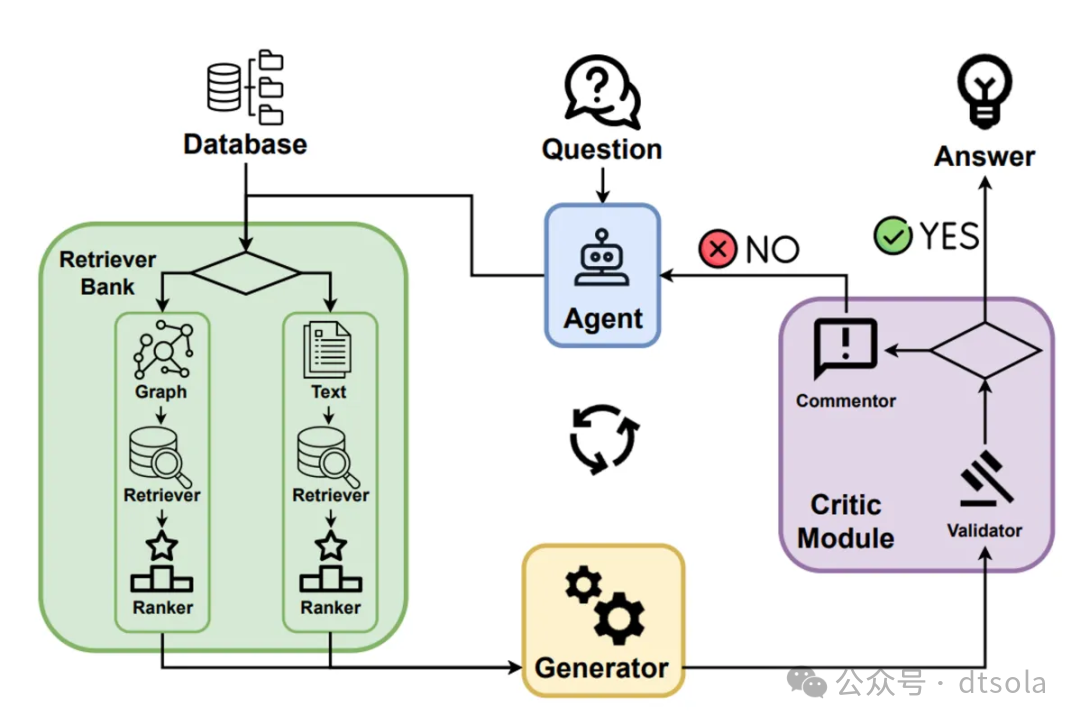
Graph-Based Agentic RAG
Graph-Based Agentic RAG在检索中引入了图检索,合并图数据及其他检索数据增强检索效果。
流程(思想)
Agentic RAG:架构上引入Agent的思路,实现动态决策(如是否检索、工具调用)和多轮迭代优化。相比上述提到的几种RAG,Agentic RAG将实际输入处理的多样性交给LLM处理,可以解决更复杂的问题。
Agent的核心部件:LLM + Memory + Planning + Tools
总结
企业级RAG系统的落地是一个复杂的系统工程,需要从简单到复杂、从单一到模块化、从静态到动态的演进过程。通过本文提供的实践框架,我们可以看到RAG技术已经从最初的Naive RAG发展到更加复杂的Modular RAG和Agentic RAG架构。
RAG技术演进路径
从Naive RAG到Advanced RAG:通过增加Pre-Retrieval和Post-Retrieval环节,解决了简单RAG在文档召回质量和准确率方面的局限性。
从Advanced RAG到Modular RAG:将RAG系统模块化为多个功能组件,形成灵活的工作流,使系统更具可扩展性和适应性。Modular RAG将系统分为Module Type、Module和Operators三层结构,每个核心流程都可以包含多个功能模块,通过组合形成完整的RAG工作流。
从Modular RAG到Agentic RAG:引入智能Agent作为决策中心,实现动态处理信息检索和集成操作,进一步提升系统的智能性和自适应能力。
企业实践的关键思考
- 模块化思维:企业在实施RAG系统时,应采用模块化设计思想,将复杂系统拆分为可独立优化的功能模块,便于迭代和扩展。
- 自适应机制:引入LLM作为决策中心,实现系统的自适应能力,能够根据不同查询类型和内容动态调整检索策略和生成策略。
- 多源融合能力:现代企业数据分散在多个系统中,RAG系统需要具备多源数据融合能力,包括结构化数据库、非结构化文档、知识图谱等。
- 闭环优化:建立评估-反馈-优化的闭环机制,通过持续监控系统性能,不断优化各个环节的效果。
- Agent协作框架:对于复杂业务场景,可考虑采用多Agent协作框架,如Hierarchical Agentic RAG或Multi-Agent Agentic RAG,将不同职责分配给专门的Agent处理。
未来发展方向
随着大模型和向量检索技术的不断进步,企业级RAG系统将向以下方向发展:
- 更深度的业务集成:RAG系统将与企业核心业务流程深度集成,成为员工和客户交互的智能中枢。
- 多模态RAG:扩展到图像、音频、视频等多模态内容的检索和生成,提供更全面的知识服务。
- 自学习能力:系统能够从用户交互中学习,自动优化检索策略和生成质量,减少人工干预。
- 知识推理增强:结合知识图谱和推理能力,不仅检索已有知识,还能进行知识推理和创新。
- 分布式协作:多个专业领域RAG系统协同工作,共同解决跨领域复杂问题。
企业级RAG系统的成功落地不仅需要先进的技术架构,还需要与企业业务深度结合,持续迭代优化,最终实现AI与人类专家知识的完美融合,创造真正的商业价值。通过从Naive RAG到Agentic RAG的演进,企业可以构建出更加智能、高效、准确的知识服务系统,为数字化转型提供强大支撑。
--------
对你有帮助?欢迎关注 ![]() 【dtsola】,第一时间获得推送 ~
【dtsola】,第一时间获得推送 ~
更多推荐


 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)