
爆火的 DeepSeek-OCR:开启大模型文本处理新纪元
近期,DeepSeek 团队开源的 DeepSeek-OCR 模型,在 AI 领域掀起热潮。该模型相关论文《DeepSeek-OCR:Contexts Optical Compression》一经发布,便引发业内广泛关注。在 Hugging Face 平台,其 3B 参数量的基础信息公开后,短时间内页面访问量激增,GitHub 上相关代码仓库的 star 数量快速上涨,成为众多开发者和研究者讨论的
一、惊爆!DeepSeek 开源黑科技模型
1.1 模型横空出世,震撼 AI 圈
近期,DeepSeek 团队开源的 DeepSeek-OCR 模型,在 AI 领域掀起热潮。该模型相关论文《DeepSeek-OCR:Contexts Optical Compression》一经发布,便引发业内广泛关注。在 Hugging Face 平台,其 3B 参数量的基础信息公开后,短时间内页面访问量激增,GitHub 上相关代码仓库的 star 数量快速上涨,成为众多开发者和研究者讨论的焦点,彻底点燃了 AI 圈对长文本处理技术的关注热情。
1.2 这款模型为何能迅速 “出圈”?
要知道,传统 OCR 技术在处理长文本时,往往面临 token 数量过多、计算成本高的难题,而 DeepSeek-OCR 却能以少量视觉 token 完成海量文本压缩。它究竟是如何突破技术瓶颈,实现高效文本压缩的?其背后又蕴含着哪些创新的技术原理?接下来,我们将一一揭晓。
二、探秘 DeepSeek-OCR:全新的文本压缩理念
2.1 长文本处理的困境
在大语言模型(LLM)的应用场景中,长文本处理一直是棘手难题。传统文本处理方式依赖大量文本 token,当文本长度增加时,token 数量会呈线性甚至指数级增长。这不仅导致模型计算复杂度大幅上升,还会消耗巨额算力与显存资源。例如,部分主流 LLM 在处理超过万字的文档时,常会出现运算卡顿、响应延迟等问题,甚至因资源不足而中断任务,严重制约了长文本场景下的应用落地。
2.2 “光学压缩” 的破局之道
DeepSeek-OCR 提出的 “视觉模态压缩” 方案,为长文本处理困境提供了全新解法。其核心思路是将长文本转化为视觉信息进行压缩 —— 就像我们在生活中,一张图片能容纳数百字的文字内容,且占用空间远小于纯文本文件。该模型借助视觉模态的天然压缩优势,将海量文本转化为少量视觉 token,从源头减少数据量,既降低了计算资源消耗,又为长文本上下文处理开辟了新路径。
三、深度剖析:DeepSeek-OCR 的架构与原理
3.1 核心组件大揭秘
3.1.1 DeepEncoder:图像压缩的魔法引擎
作为模型的核心编码器,DeepEncoder 专为高分辨率输入场景设计,具备 “低计算激活 + 高压缩比” 双重优势。其架构融合了 SAM-base(Segment Anything Model-base)、CLIP-large(Contrastive Language-Image Pre-training-large)模型与 16 倍卷积压缩器:SAM-base 负责精准提取文本区域的视觉特征,CLIP-large 实现跨模态特征对齐,16 倍卷积压缩器则在保留关键信息的前提下,将视觉数据压缩至原尺寸的 1/16。以 1024×1024 分辨率的文档图像为例,经 DeepEncoder 处理后,视觉 token 数量可控制在百级以内,远低于传统文本 token 数量,有效解决了数据冗余问题。
3.1.2 DeepSeek3B-MoE-A570M:精准还原的解码大师
解码器 DeepSeek3B-MoE-A570M 采用混合专家(MoE)架构,总参数量 3B,其中激活参数量仅 570M。该架构的优势在于 “按需调用资源”—— 模型内置多个专业化 “专家模块”,在处理不同类型文档(如多语言文档、手写体文档、古籍文档)时,会自动激活适配的专家模块协同工作。例如,处理英文技术文档时,会优先激活 “专业术语识别模块” 与 “格式解析模块”;处理中文古籍时,则重点调用 “异体字识别模块” 与 “模糊文本修复模块”,确保从压缩视觉 token 中精准重建文本内容。

3.2 训练与数据的奥秘
3.2.1 独特的训练流程
DeepSeek-OCR 采用 “两阶段训练法”,确保编码器与解码器协同优化。第一阶段为 “编码器独立预训练”:单独训练 DeepEncoder,使用海量高分辨率文档图像(涵盖印刷体、手写体、多语言等场景),优化其特征提取与压缩能力,目标是在保证视觉信息完整性的前提下,实现最高压缩比。第二阶段为 “端到端联合微调”:将预训练好的 DeepEncoder 与 DeepSeek3B-MoE-A570M 解码器结合,使用标注好的 “图像 - 文本” 配对数据进行联合训练,优化跨模态信息转换效率,重点提升 OCR 精度与文本还原连贯性。
3.2.2 庞大而优质的数据支撑
模型训练数据规模庞大且类型丰富,涵盖三大核心数据集:一是 “多语言文档数据集”,包含英、中、日、德等 12 种语言的新闻、财报、论文等文档,总量超 500 万页;二是 “特殊场景文档数据集”,涵盖手写病历、古籍善本、模糊扫描件等特殊文本,共 300 万页,用于提升模型鲁棒性;三是 “通用视觉数据集”,采用 COCO、Flickr30k 等公开数据集,增强模型对复杂背景、光照变化的适应能力。多样化的数据支撑,让 DeepSeek-OCR 能够应对不同行业、不同场景的文本处理需求。
四、实力验证:DeepSeek-OCR 的卓越表现
4.1 高压缩比下的高精度
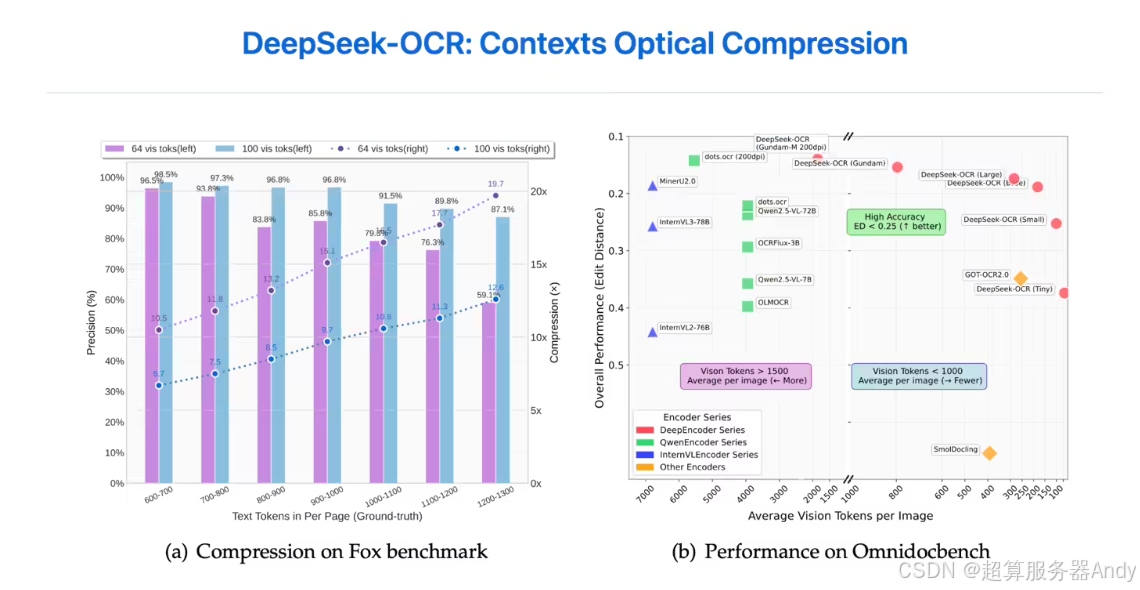
实验数据显示,DeepSeek-OCR 在不同压缩比下均保持出色性能:当文本 token 数量与视觉 token 数量比例≤10:1(即压缩比≤10×)时,模型 OCR 精度高达 97%,与传统无压缩 OCR 技术精度基本持平;即使压缩比提升至 20×(文本 token 数量为视觉 token 的 20 倍),准确率仍稳定在 60% 以上。这一表现远超行业平均水平 —— 传统 OCR 技术在压缩比超过 8× 时,精度会骤降至 50% 以下。高压缩比与高精度的平衡,让该模型在历史文档长上下文压缩(如古籍全文存储)、大语言模型记忆机制研究(如长文本上下文窗口扩展)等领域具备巨大应用潜力。
4.2 OmniDocBench 测试的辉煌战绩
在权威 OCR 测试集 OmniDocBench(涵盖 10 类复杂文档场景,包括多栏排版、低分辨率、复杂背景等)中,DeepSeek-OCR 表现惊艳:对比行业主流模型 GOT-OCR2.0 与 MinerU2.0,DeepSeek-OCR 仅使用 100 个视觉 token,就在 “多栏论文解析”“低分辨率财报识别” 等 5 个场景中超越 GOT-OCR2.0(需 256 个 token / 页);在 “古籍模糊文本识别”“手写病历解析” 等难度更高的场景中,使用不足 800 个视觉 token,性能便优于 MinerU2.0(平均需 6000 个 token / 页)。更少的 token 消耗意味着更低的计算成本,这一测试结果充分证明了 DeepSeek-OCR 的高效性与经济性。

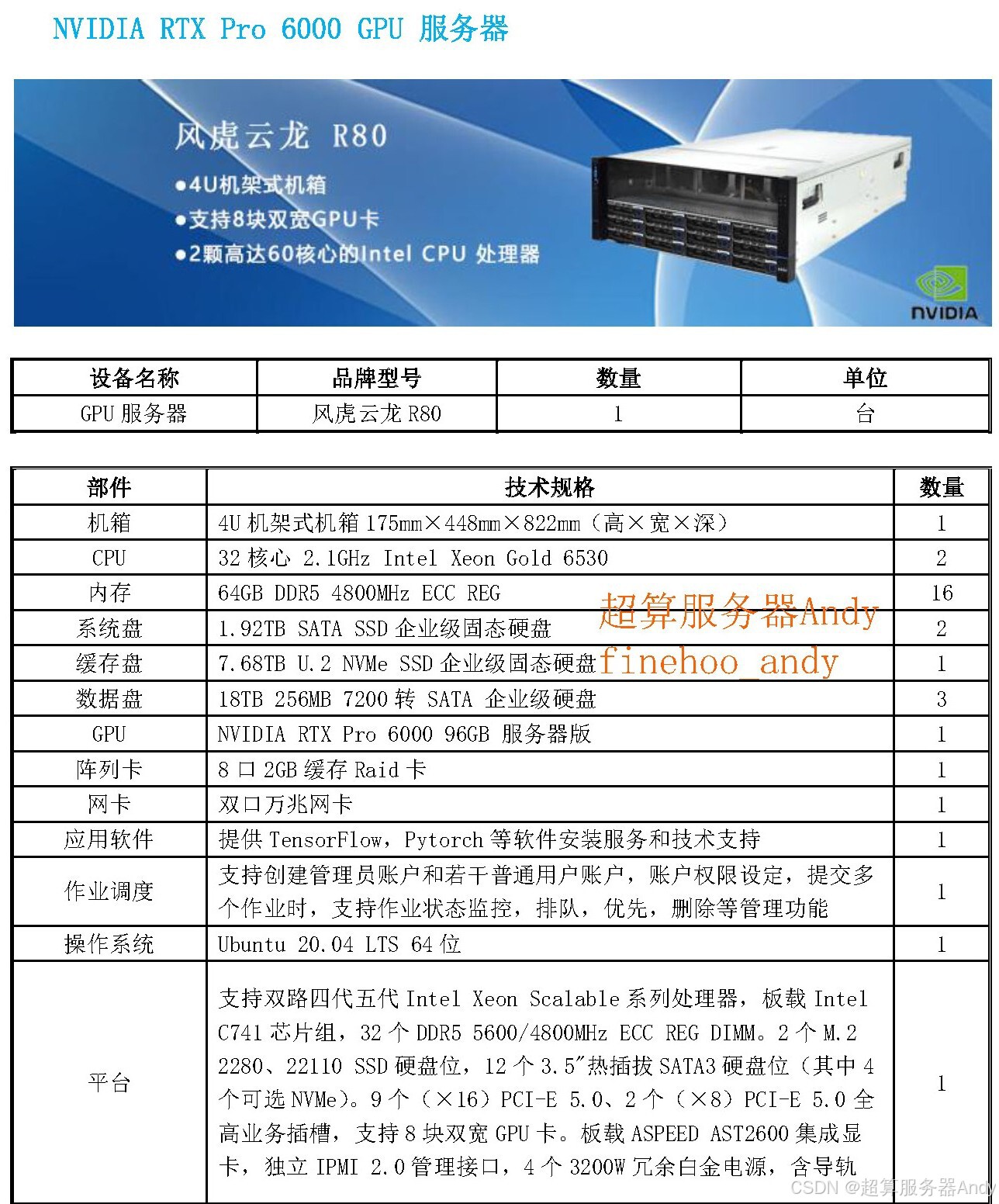
五、GPU 服务器:DeepSeek-OCR 背后的强大助力
5.1 GPU 服务器的关键作用
DeepSeek-OCR 的训练与推理,离不开 GPU 服务器的算力支撑。GPU(图形处理器)具备并行计算架构,可同时处理海量数据,这与模型的技术需求高度契合:在训练阶段,DeepEncoder 的卷积运算、解码器的 MoE 模块激活均需大规模矩阵运算,GPU 服务器的 CUDA 核心能将这类运算速度提升数十倍,原本需要数月的训练任务,借助 GPU 集群可缩短至数周;在推理阶段,面对高分辨率文档图像的实时处理需求,GPU 服务器的显存带宽优势可快速加载模型参数与视觉特征,避免数据传输延迟,确保 OCR 任务高效执行。
5.2 实际生产中的高效协作
在实际生产场景中,DeepSeek-OCR 与 GPU 服务器的协同效应尤为显著。以单块 A100-40G 显卡为例,其强大的算力支持让 DeepSeek-OCR 每天可生成超过 20 万页的大语言模型(LLM)/ 视觉语言模型(VLM)训练数据 —— 这一效率是 CPU 处理的 50 倍以上。具体而言,A100-40G 的 40GB 高带宽显存可同时加载多个模型实例,配合 Tensor Core 的混合精度计算能力,大幅提升视觉 token 的生成与文本还原速度。对于需要大规模训练数据的企业而言,这种 “模型 + GPU” 的组合,可显著降低数据生成成本,加速 AI 模型的迭代优化。
六、广泛应用:DeepSeek-OCR 的无限可能
6.1 金融领域:财报处理的神器
在金融行业,企业财报、银行流水等文档的结构化处理需求巨大。传统人工录入方式不仅效率低(人均日处理不足 100 页),还易出错。DeepSeek-OCR 可快速将财报中的文字、表格转化为结构化数据(如 Excel、数据库格式),结合 GPU 服务器的算力,单台设备日处理量可达 10 万页以上,准确率超 95%。例如,某券商使用该方案后,财报数据处理周期从 7 天缩短至 1 天,为投资分析、风险管控提供了及时的数据支撑。
6.2 医疗行业:病历数字化先锋
医疗行业的历史病历(如纸质病历、扫描件)数字化是重要需求,但这类文档常存在手写模糊、格式不统一等问题。DeepSeek-OCR 的 “模糊文本修复” 与 “手写体识别” 能力,可精准提取病历中的患者信息、诊断结果、用药记录等关键内容,并转化为电子病历系统可识别的格式。配合 GPU 服务器,医院可在数月内完成数十年历史病历的数字化,既节省了存储空间(压缩比 10× 以上),又便于医生快速检索、分析病历数据,助力临床研究与精准医疗。
6.3 出版机构:古籍数字化的救星
古籍保护与数字化是出版机构的重要任务,但古籍存在字体特殊(如篆书、隶书)、纸张泛黄、文字残缺等问题,传统 OCR 技术难以应对。DeepSeek-OCR 通过 “异体字识别模块” 与 “文本修复算法”,可精准识别古籍中的特殊文字,并修复残缺内容。某古籍出版社采用该模型 + GPU 服务器方案后,古籍数字化效率提升 8 倍,原本需要 1 年完成的某套宋代古籍数字化工作,仅用 1.5 个月便完成,且识别准确率达 90% 以上,为文化遗产的保护与传承提供了技术支持。
七、开启 AI 文本处理新篇章
7.1 技术突破的遐想
未来,DeepSeek-OCR 或在两大方向实现突破:一是 “动态压缩比调节”,结合具体应用场景自动调整压缩比 —— 如对精度要求高的法律文档采用 5× 压缩比,对存储需求高的普通新闻采用 20× 压缩比,进一步平衡精度与效率;二是 “与大语言模型深度融合”,将视觉压缩 token 直接接入 LLM 的上下文窗口,突破当前 LLM 的上下文长度限制(如从 128k token 扩展至 1M token 以上),实现超长篇文档的实时理解与分析。此外,模拟人类 “选择性记忆” 机制,让模型优先保留关键文本信息,也是重要研究方向。
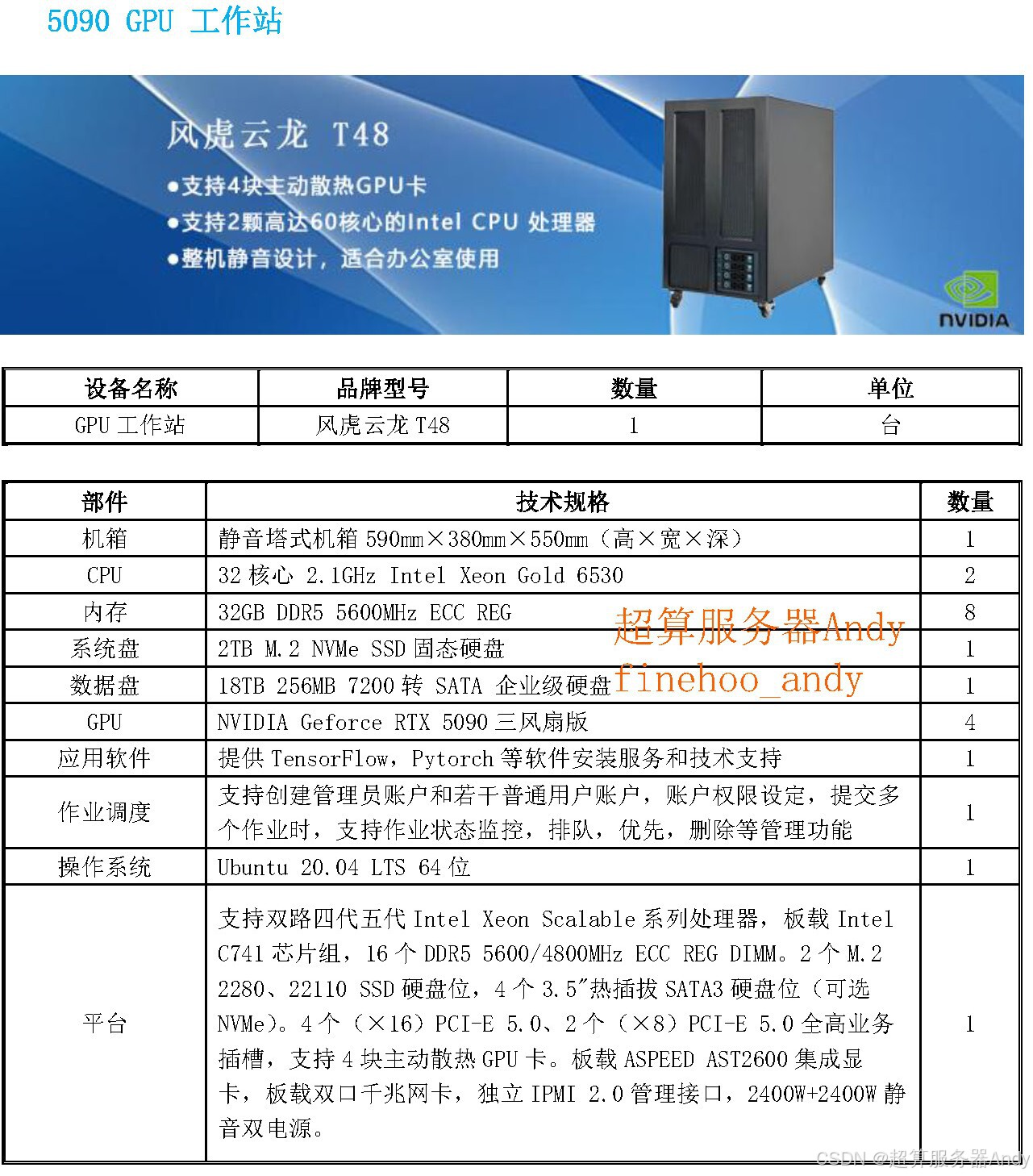
7.2 对 AI 发展的深远影响
DeepSeek-OCR 的出现,不仅为长文本处理提供了新方案,更推动了多模态技术的发展。其 “视觉模态压缩” 思路,可迁移至视频文本识别、多模态内容生成等领域,为 AI 技术开辟新的应用场景。同时,该模型与 GPU 服务器的协同模式,也为中小企业降低 AI 应用门槛提供了参考 —— 无需搭建大规模算力集群,借助单块高性能 GPU 即可实现高效文本处理。长远来看,DeepSeek-OCR 的技术理念或将重塑 AI 文本处理的行业标准,推动整个 AI 领域向 “更高效、更节能、更实用” 的方向发展。
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)