
Redis缓存与数据库一致性终极指南:从延迟双删到分布式事务
明确需求强一致:牺牲性能保安全最终一致:保证吞吐量组合拳策略fill:#333;color:#333;color:#333;fill:none;更新数据库操作删缓存Binlog监听兜底版本号校验持续监控缓存命中率波动 > 10% 告警主从延迟 > 500ms 告警缓存删除失败次数 > 100/分钟 告警🔥黄金口诀增删改先动库,缓存删除要双次强一致上事务,最终一致双删足监听日志做兜底,版本防旧是利
·
💡 血泪教训:某金融平台因缓存数据不一致导致用户余额错乱,损失千万!本文将用银行对账💰比喻+实战代码,揭秘6大解决方案,让你的数据毫秒级同步!
💥 一、为什么需要数据一致性?一个事故引发的思考
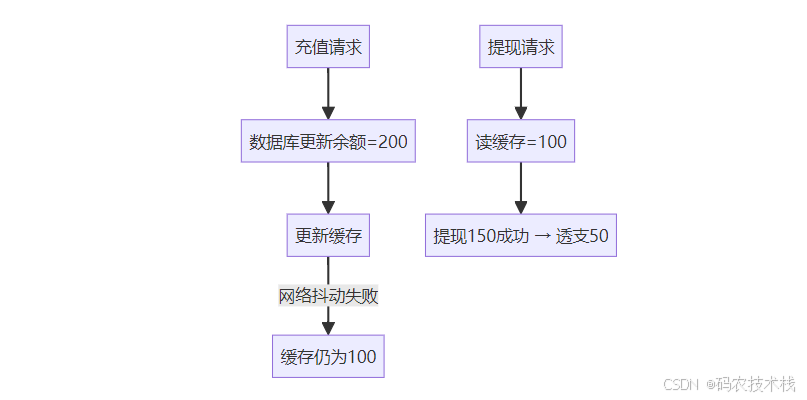
真实案例:
- 用户充值100元,数据库成功
- 缓存更新失败,仍显示旧余额
- 用户发起提现 → 余额透支 → 资金损失
- 审计发现1000+类似错误,赔付1200万💸
🔄 二、缓存模式与一致性问题根源
1. 三种缓存读写模式
| 模式 | 写操作顺序 | 读操作 | 风险 |
|---|---|---|---|
| Cache Aside | 先更DB → 后删缓存 | 读缓存 → 无则读DB | 缓存删除失败 |
| Write Through | 缓存代理写 → 同步写DB | 读缓存 | 性能低,缓存故障数据丢失 |
| Write Back | 写缓存 → 异步批量写DB | 读缓存 | 宕机丢数据 |
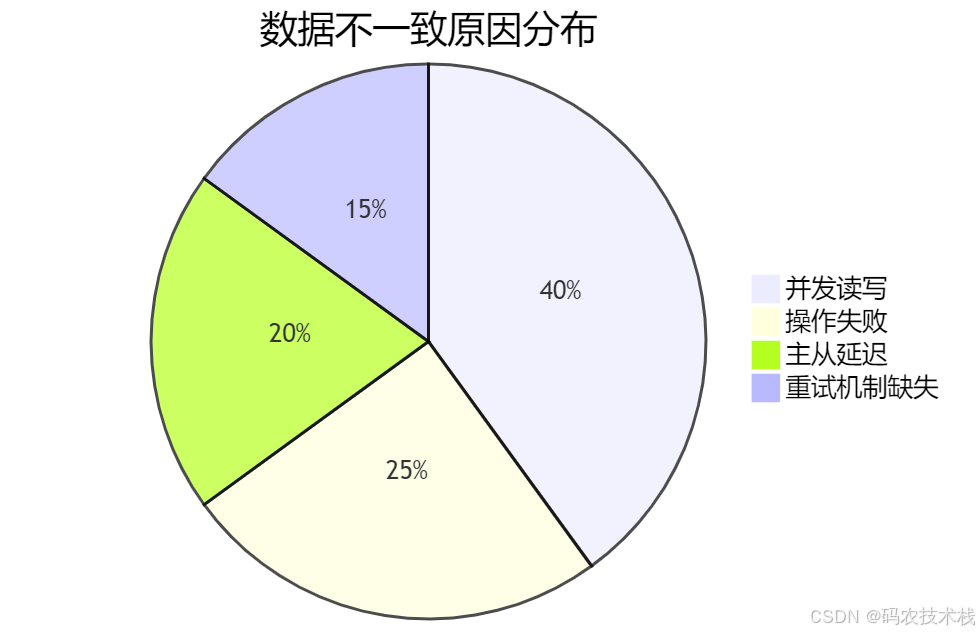
2. 不一致的四大根源
🛠️ 三、六大解决方案详解
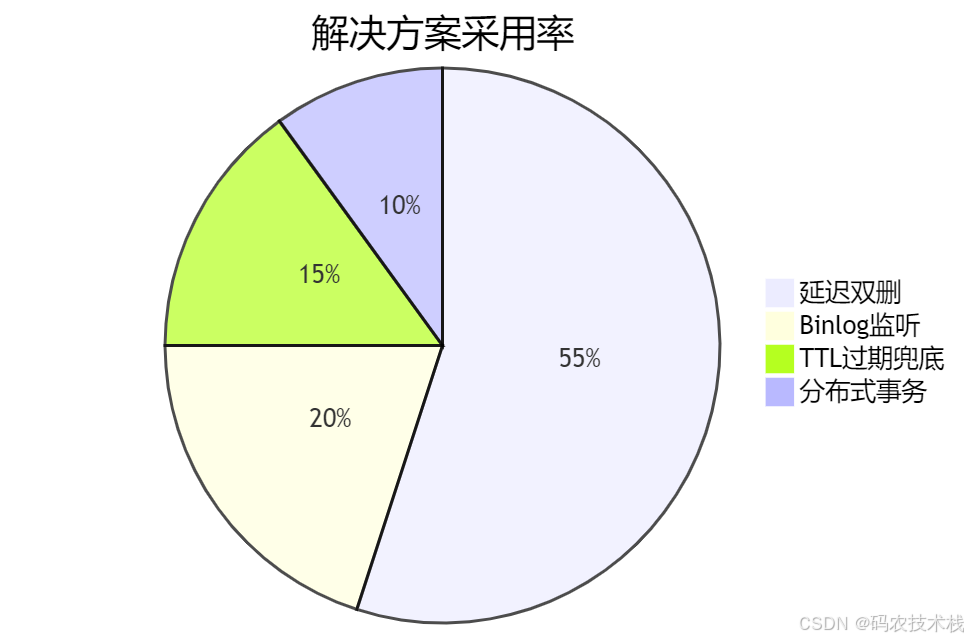
🔧 方案1:延迟双删(最终一致性)
适用场景:对一致性要求一般的电商、社交应用
操作流程:
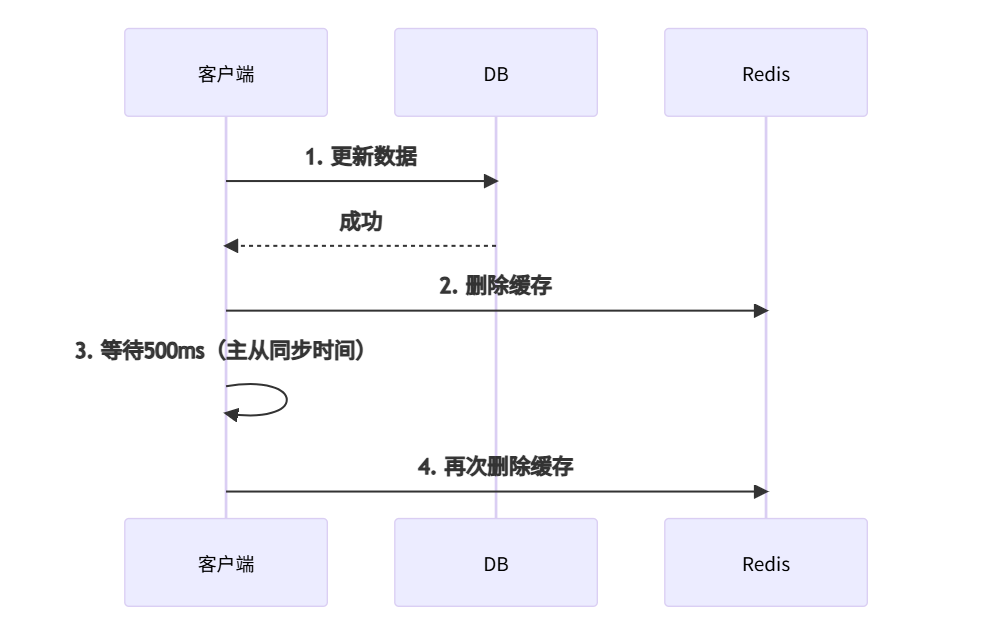
Java代码实现:
public void updateData(Data data) {
// 1. 更新数据库
dataDao.update(data);
// 2. 首次删除缓存
redis.del("data:" + data.getId());
// 3. 延迟二次删除
executor.schedule(() -> {
redis.del("data:" + data.getId());
}, 500, TimeUnit.MILLISECONDS); // 根据主从延迟调整
}
⚡ 方案2:内存队列串行化(强一致性)
原理:相同Key的操作入队顺序执行
Redis Stream实现:
# 写入更新命令
XADD data_ops * type update id 123 value 100
# 消费者顺序执行
XREAD BLOCK 0 STREAMS data_ops $
📝 方案3:Binlog监听(准实时同步)
架构:
Canal配置示例:
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.mq.topic=data_cache
🔒 方案4:分布式事务(强一致性)
Redis + MySQL事务流程:
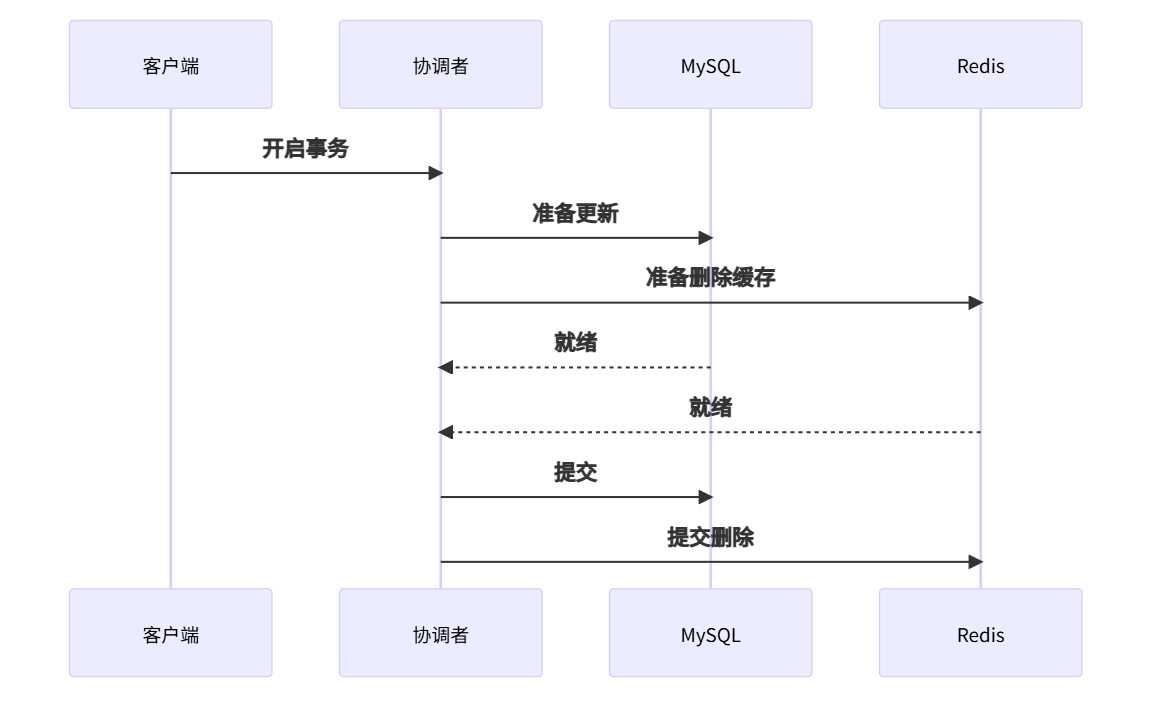
Seata框架实现:
@GlobalTransactional
public void updateData(Data data) {
dataDao.update(data); // 更新DB
redisTemplate.delete("data:" + data.getId()); // 删缓存
}
🧪 方案5:版本号控制(乐观锁)
操作流程:
- 数据中增加版本号字段
- 更新时携带版本号
- 缓存命中时校验版本
public Data getData(long id) {
String cacheKey = "data:" + id;
Data data = redis.get(cacheKey);
if (data == null) {
data = db.query("SELECT * FROM data WHERE id=?", id);
redis.set(cacheKey, data);
} else if (data.version < db.getVersion(id)) {
// 版本落后则刷新
data = refreshFromDb(id);
}
return data;
}
🚀 方案6:TTL自动过期兜底
策略组合:
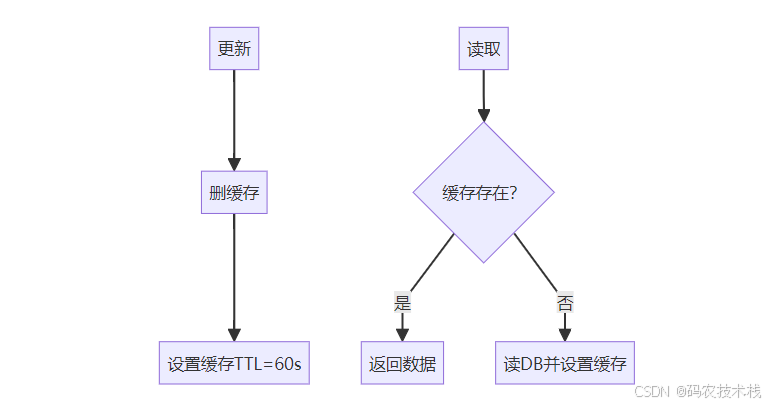
⚖️ 四、方案选型决策表
| 场景 | 一致性要求 | 推荐方案 | 性能影响 | 实现复杂度 |
|---|---|---|---|---|
| 用户余额/库存 | 强一致 | 分布式事务 | 高 | ⭐⭐⭐⭐ |
| 商品详情/文章 | 最终一致 | 延迟双删 | 低 | ⭐⭐ |
| 实时价格 | 准实时 | Binlog监听 | 中 | ⭐⭐⭐ |
| 高并发写入 | 最终一致 | TTL过期兜底 | 极低 | ⭐ |
| 配置信息 | 强一致 | 版本号控制 | 中 | ⭐⭐ |
⚠️ 五、四大生产环境陷阱
🚫 陷阱1:先删缓存后更DB
问题:
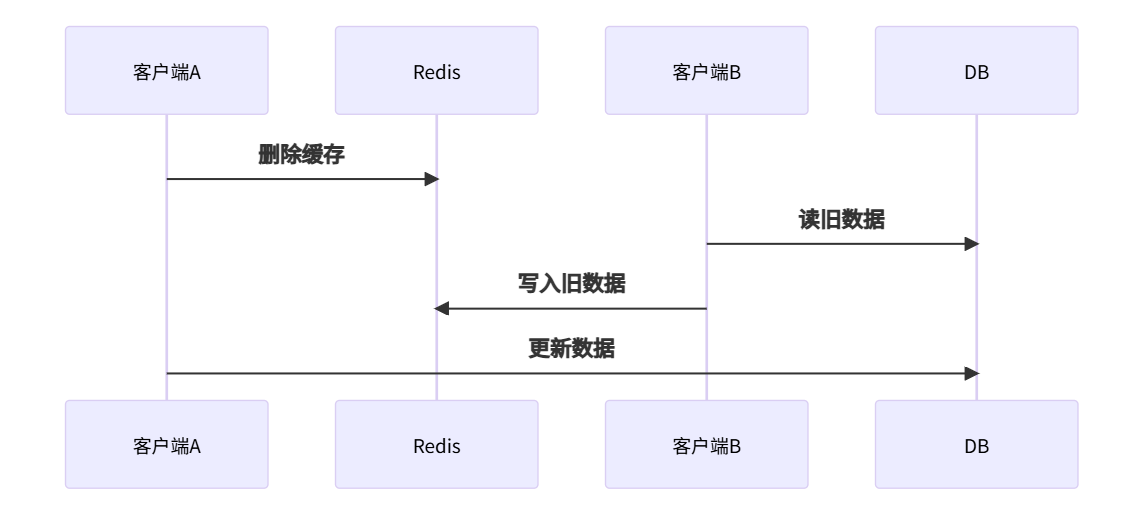
结果:缓存永久存储旧数据!
避坑:永远先更新数据库,再删缓存
🚫 陷阱2:缓存删除失败无重试
解决方案:
// 带重试的删除
void deleteWithRetry(String key, int maxRetries) {
int retry = 0;
while (retry < maxRetries) {
if (redis.del(key) == 1) break;
Thread.sleep(100);
retry++;
}
if (retry == maxRetries) {
mq.send("cache_clean", key); // 投递消息队列
}
}
🚫 陷阱3:主从延迟导致脏读
场景:主库更新 → 从库未同步 → 读从库旧值 → 写入缓存
优化:
延迟双删的等待时间 > 主从延迟最大值
🚫 陷阱4:热点Key频繁更新
方案:
📊 六、性能与一致性权衡
| 方案 | 数据延迟 | 吞吐量 | 适用场景 |
|---|---|---|---|
| 延迟双删 | 500ms | 10万+ QPS | 通用场景 |
| Binlog监听 | 100ms | 5万 QPS | 准实时系统 |
| 分布式事务 | 0ms | 3千 QPS | 金融交易 |
| TTL过期 | 60秒 | 15万+ QPS | 可容忍读旧数据 |
💡 压测环境:Redis 7.0集群,MySQL 8.0,16核CPU
🔧 七、最佳实践:黄金四法则
-
模式选择:
- 80%场景用 Cache Aside + 延迟双删
- 关键业务用 Binlog监听或分布式事务
-
删除策略:
// 伪代码:标准操作顺序 void updateData(Data data) { 1. db.update(data); 2. redis.delete(key); 3. // 可选:延迟二次删除 } -
监控指标:
# 缓存不一致率 = (缓存错误数 / 总请求数) redis-cli info | grep keyspace_misses mysql> SHOW STATUS LIKE 'Innodb_rows_read'; -
降级方案:
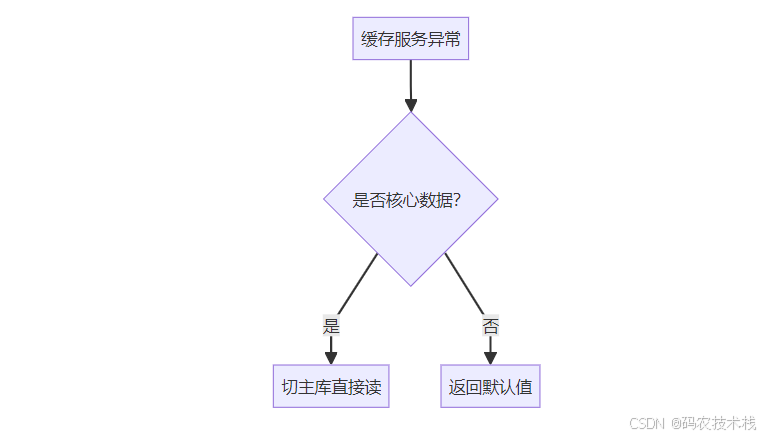
💎 八、总结:一致性保障三原则
-
明确需求:
- 强一致:牺牲性能保安全
- 最终一致:保证吞吐量
-
组合拳策略:
-
持续监控:
- 缓存命中率波动 > 10% 告警
- 主从延迟 > 500ms 告警
- 缓存删除失败次数 > 100/分钟 告警
🔥 黄金口诀:
- 增删改先动库,缓存删除要双次
- 强一致上事务,最终一致双删足
- 监听日志做兜底,版本防旧是利器
#Redis #数据一致性 #高并发架构

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐



 61
61 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)