




- @zyw2002
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文对比了Transformer中的两种位置编码方法:绝对位置编码(APE)和旋转位置编码(RoPE)。APE通过为每个位置分配固定或可学习的向量,直接加到词嵌入中,但存在外推性差的问题。RoPE则通过旋转Q/K向量的方式,使注意力分数天然编码相对位置关系,更适合长文本处理。文章详细分析了两种方法的实现原理、关键特性和适用场景:APE适合固定长度的非自回归任务,而RoPE在自回归语言模型和长上下文
Pandas —— 数据分析处理库安装Pandas: pip install pandasimport pandas as pdpd.show_versions() # 显示当前版本信息读取数据读数据pd.read_csv() : 读取csv类型数据df = pd.read_csv('./data/titanic.csv')df.head(n) : 显示前n条数据df.head(6) # head

yolov3论文精读
机器学习的组件每个数据集由⼀个个样本(example, sample)组成,⼤多时候,它们遵循独⽴同分布(independently and identically distributed, )。样本有时也叫做数据点(data point)或者数据实例(data instance),通常每个样本由⼀组称为特征(features,或协变量(covariates))的属性组成。机器学习模型会根据这些属
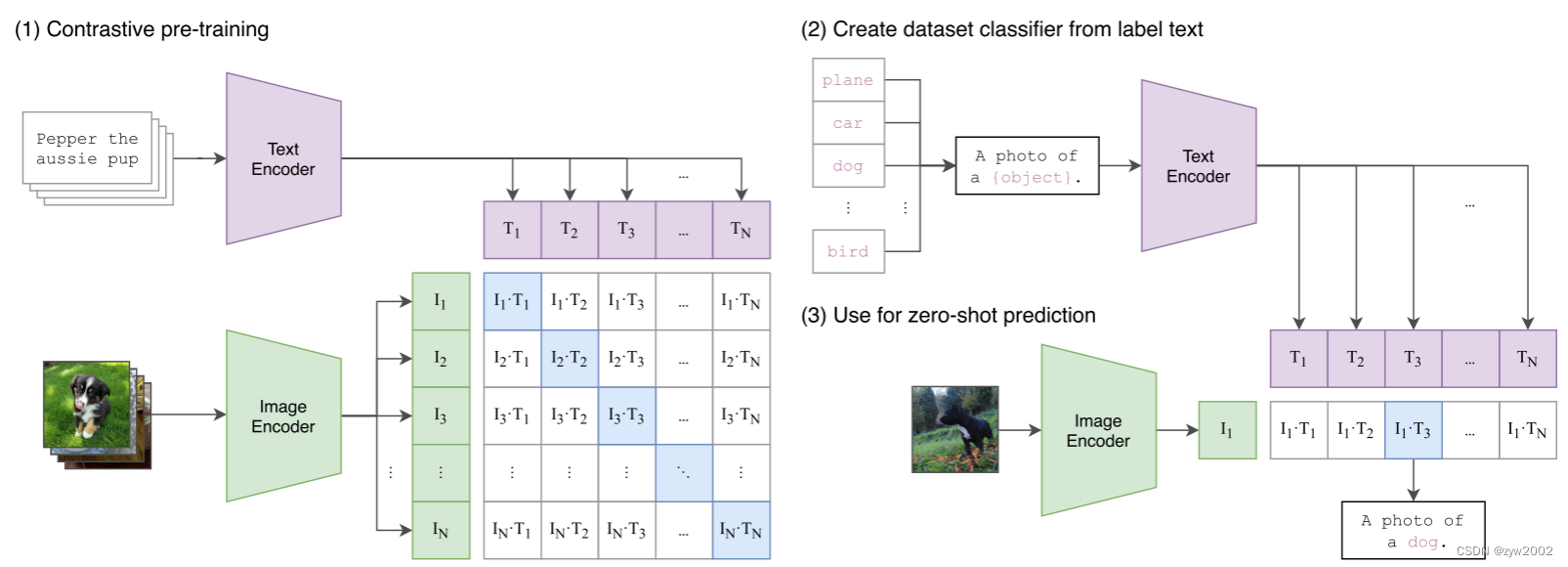
研究动机作者的研究动机就是在 NLP 领域利用大规模数据去预训练模型,而且用这种跟下游任务无关的训练方式,NLP 那边取得了非常革命性的成功,比如 GPT-3。作者希望把 NLP 中的这种成功应用到其他领域,如视觉领域。在预训练时 CLIP 使用了对比学习,利用文本的提示去做 zero-shot 迁移学习。在大规模数据集和大模型的双向加持下,CLIP 的性能可以与特定任务的有监督训练出来的模型竞争
Precision: 描述的是找对的概率Recall: 描述的是找全的概率一般来说,准确率和找回率不能同时兼顾,一个高另一个就相对变低。改变阈值(IOU大于一定的阈值,就被判为正样本),可以得到不同的precision和recall, 然后做出presion - recall 的图(一般叫做PR图)去上限求出与x轴围成的阴影的面积就是AP的值。如上图就是长方形A1,A2,A3,A4的面积之和。对每
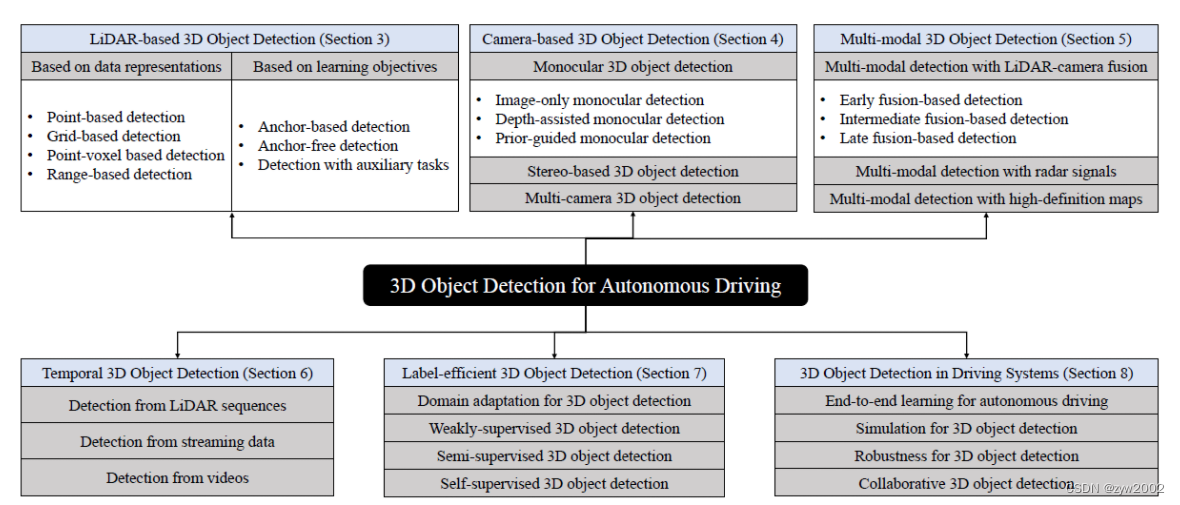
本文的主要工作: 应用于自动驾驶领域的3D目标检测的进展背景&挑战:3D目标检测的背景以及面临的挑战方法&分析:从模型和传感器输入方面对3D目标检测的方法进行探讨。**应用:**研究了3D目标检测在驾驶系统中的应用性能分析&未来展望:对3D目标检测方法进行了性能分析,并进一步总结了多年来的研究趋势,展望了该领域的未来方向。自动驾驶,通过传感器感知周围的环境输入:多模态数据(来自摄像头的图像数据、来
本文提出的最先进的,实时目标检测系统算法是YOLO9000,可以检测超过9000个目标类别。该算法是在YOLOv1的基础上改进得到的。YOLO9000使用一种新颖的多尺度训练方法(multi-scale training method),相同的YOLOv2模型可以运行在不同的大小的图片上,权衡(t
文章目录Bag of freebies(BOF)数据增强网络正则化的方法类别不平衡,损失函数设计Bag of specials(BOS)SPPNet(Spatial Pyramid Pooling)CSPNet(Cross Stage Partial Network)CBAM(Convolutional Block Attention Module)PAN(Path Aggregation Net
文章目录OpenCL&Cuda1. 环境配置1.1 cuda的安装和配置1.1.1 安装CUDA1.1.2 配置环境变量1.1.3 检查cuda是否安装成功1.2 VS中配置cuda1.3 VS中配置opencl2. OpenCL&Cuda编程2.1 编程基础2.2 编程案例2.2.1 查看配置信息2.2.2. 向量运算实验目的实验步骤opencl 代码分析cuda 代码分析实验结